系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
目录
- 系列篇章💥
- 前言
- 案例场景
- 准备工作
- 1)学术加速
- 2)安装LFS
- 3)下载数据集(原始语料库)
- 4)下载模型到本地
- 步骤1:导入相关依赖
- 步骤2:获取数据集
- 步骤3:构建数据集
- 步骤4:划分数据集
- 步骤5:创建DataLoader
- 步骤6:创建模型及其优化器
- 步骤7:训练与验证
- 步骤8:模型预测
- 总结
前言
在深入探索Transformer库及其高级组件之前,我们先手工编写一个预训练流程代码。这一过程不仅有助于理解预训练的步骤和复杂性,而且能让您体会到后续引入高级组件所带来的开发便利性。通过实践,我们将构建一个情感分类模型,该模型能够接收文本评价并预测其是正面还是负面的情感倾向。
案例场景
想象一下,我们有一个原始数据集,其中包含了酒店顾客的评价文本。我们的目标是训练一个模型,当输入类似“昨天我在酒店睡觉发现被子有一股霉味。”的评价时,模型能够预测出“差评”。
准备工作
本次仍是采用云服务器autodl调试运行
1)学术加速
source /etc/network_turbo

2)安装LFS
从 Hugging Face Hub 下载模型需要先安装Git LFS
安装git-lfs是为了确保从Hugging Face拉取模型时能够高效且完整地下载所有相关文件,尤其是那些大型的模型文件。
Ubuntu系统操作命令:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
Centos命令参考:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
sudo yum install git-lfs
执行:git lfs install

3)下载数据集(原始语料库)
创建一个pretrains目录,将数据集下载到这个目录,下载到本地后可以提高执行效率
git clone https://huggingface.co/datasets/dirtycomputer/ChnSentiCorp_htl_all

注意!重要!!:下载后请记得和Huggingface上的文件对比,尤其是大文件,确保下载完整
4)下载模型到本地
git clone https://huggingface.co/hfl/rbt3
下载到本地后,从本地加载执行效率更高

注意!重要!!:下载后请记得和Huggingface上的文件对比,尤其是大文件,确保下载完整
步骤1:导入相关依赖
首先,我们需要设置Python环境,并导入必要的库
python">from transformers import AutoTokenizer, AutoModelForSequenceClassification
步骤2:获取数据集
获取数据集是预训练中关键一步。我们使用前面从Huggingface下载的包含酒店评价的文本数据集。
1)加载本地的数据集,查看读取内容
python">import pandas as pd
data = pd.read_csv("/root/pretrains/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv")
data.dropna()
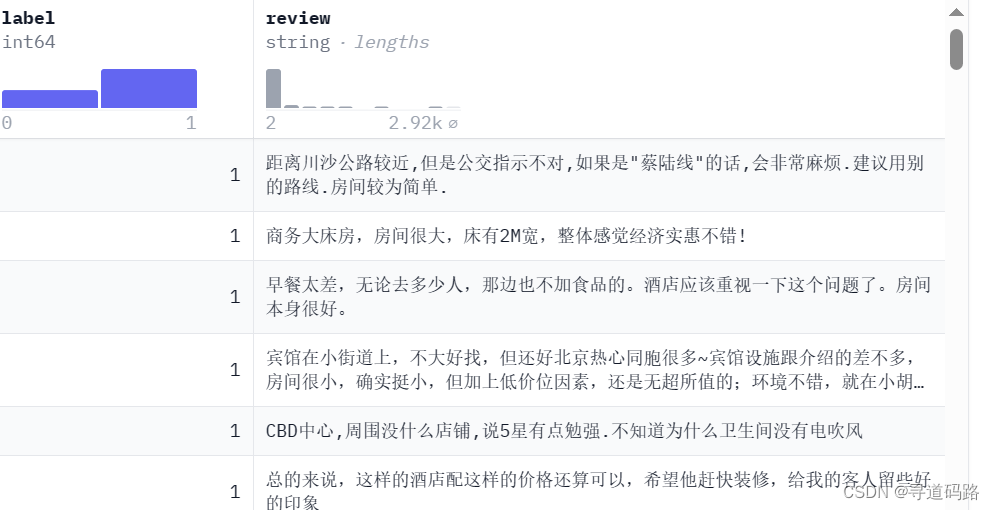
data
执行输出如下:

步骤3:构建数据集
创建一个自定义的数据集类,它将负责读取原始数据,可以执行必要的预处理步骤(例如清洗、分词、向量化),并将数据划分为训练集和验证集。
python">from torch.utils.data import Datasetimport pandas as pdclass MyDataset(Dataset):def __init__(self) -> None:super().__init__()self.data = pd.read_csv("/root/pretrains/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv")self.data = self.data.dropna()def __getitem__(self,index):return self.data.iloc[index]["review"], self.data.iloc[index]["label"]def __len__(self):return len(self.data) dataset = MyDataset()
for i in range(5):print(dataset[i])
python">('距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦.建议用别的路线.房间较为简单.', 1)
('商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!', 1)
('早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。房间本身很好。', 1)
('宾馆在小街道上,不大好找,但还好北京热心同胞很多~宾馆设施跟介绍的差不多,房间很小,确实挺小,但加上低价位因素,还是无超所值的;环境不错,就在小胡同内,安静整洁,暖气好足-_-||。。。呵还有一大优势就是从宾馆出发,步行不到十分钟就可以到梅兰芳故居等等,京味小胡同,北海距离好近呢。总之,不错。推荐给节约消费的自助游朋友~比较划算,附近特色小吃很多~', 1)
('CBD中心,周围没什么店铺,说5星有点勉强.不知道为什么卫生间没有电吹风', 1)步骤4:划分数据集
对数据集进行划分,语料库中90%作为预训练数据,10%作为验证数据;这确保了模型在未见过的数据上进行验证和测试。
python">from torch.utils.data import random_splittrainset, validset = random_split(dataset,lengths=[0.9,0.1])
len(trainset),len(validset)
输出:(6989, 776)
步骤5:创建DataLoader
1)加载数据集
利用分词器进行数据加载(即将文本数据转化为机器能识别的数字序列矩阵)
为了高效地加载数据,采用批量的方式加载预训练数据和校验数据,加载时最大长度为128,多了会进行截取,少了会自动补0
python">import torch
from torch.utils.data import DataLoadertokenizer = AutoTokenizer.from_pretrained("/root/pretrains/rbt3")def collate_func(batch):texts,labels=[],[]for item in batch:texts.append(item[0])labels.append(item[1])## return_tensors="pt" 返回的是pytorch tensor类型。## 吃葡萄不吐葡萄皮## 不吃葡萄到吐葡萄皮inputs = tokenizer(texts,max_length=128,padding="max_length",truncation=True, return_tensors="pt")inputs["labels"] = torch.tensor(labels)return inputs
## dataloader中设置shuffle值为True,表示每次加载的数据都是随机的,将输入数据的顺序打乱。shuffle值为False,
## 表示输入数据顺序固定。trainloader = DataLoader(trainset,batch_size=32,shuffle=True,collate_fn=collate_func)
validloader = DataLoader(validset,batch_size=64,shuffle=False,collate_fn=collate_func)next(enumerate(validloader))[1]
输出如下:(下面tensor就是转化后的序列矩阵)

步骤6:创建模型及其优化器
根据本地下载的模型地址,创建模型对象
基于Transformer架构,定义一个情感分类模型。选择合适的优化器(如AdamW或RMSprop)以调整模型权重,从而最小化损失函数。
python">from torch.optim import Adamfrom transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained("/root/pretrains/rbt3")if torch.cuda.is_available():model = model.cuda()
"""
当我们训练一个机器学习模型时,我们需要选择一个优化算法来帮助我们找到模型参数的最佳值。这个优化算法就是优化器(optimizer)。在这行代码中,我们选择了一种叫做Adam的优化算法作为我们的优化器。Adam算法是一种常用的优化算法,
它根据每个参数的梯度(即参数的变化率)和学习率(lr)来更新参数的值。"model.parameters()"表示我们要优化的是模型的参数。模型的参数是模型中需要学习的权重和偏置等变量。"lr=2e-5"表示学习率的值被设置为2e-5(即0.00002)。学习率是控制模型在每次迭代中更新参数的步长。较大的学习率可能导致模型无法收敛,
而较小的学习率可能需要更长的训练时间
"""
optimizer = Adam(model.parameters(), lr=2e-5)
步骤7:训练与验证
python">定义一个训练和评估的函数
设定训练循环,包括前向传播、计算损失、反向传播和权重更新。同时,定期在验证集上检查模型性能,以监控过拟合情况并及时停止训练。
def evaluate():## 将模型设置为评估模式model.eval()acc_num=0#将训练模型转化为推理模型,模型将使用转换后的推理模式进行评估with torch.inference_mode():for batch in validloader:## 检查是否有可用的GPU,如果有,则将数据批次转移到GPU上进行加速if torch.cuda.is_available():batch = {k: v.cuda() for k,v in batch.items()}##对数据批次进行前向传播,得到模型的输出output = model(**batch)## 对模型输出进行预测,通过torch.argmax选择概率最高的类别。pred = torch.argmax(output.logits,dim=-1)## 计算正确预测的数量,将预测值与标签进行比较,并使用.float()将比较结果转换为浮点数,使用.sum()进行求和操作acc_num += (pred.long() == batch["labels"].long()).float().sum()## 返回正确预测数量与验证集样本数量的比值,这表示模型在验证集上的准确率return acc_num / len(validset)def train(epoch=3,log_sep=100):global_step = 0for ep in range(epoch):## 开启训练模式model.train()for batch in trainloader:if torch.cuda.is_available():batch = {k: v.cuda() for k, v in batch.items()}## 梯度归0optimizer.zero_grad()## 对数据批次进行前向传播,得到模型的输出output=model(**batch)## 计算损失函数梯度并进行反向传播output.loss.backward()## 优化器更新optimizer.step()if(global_step % log_sep == 0):print(f"ep:{ep},global_step:{global_step},loss:{output.loss.item()}")global_step += 1## 准确率acc = evaluate()## 第几轮print(f"ep:{ep},acc:{acc}")# 训练
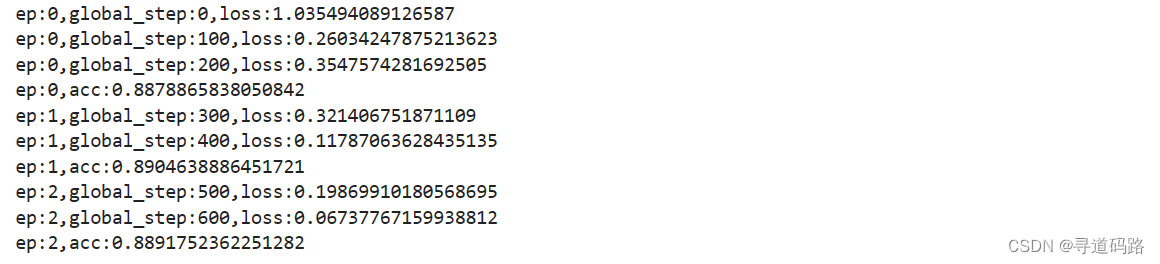
train()
输出3轮训练结果,准确率在88%-89%左右
步骤8:模型预测
完成训练后,利用训练好的模型对新输入的评价进行情感分类。展示模型如何接收新文本,并输出预测结果。
python">#sen = "我昨晚在酒店里睡得非常好"
sen ="昨天我在酒店睡觉发现被子有一股霉味"id2label = {0:"差评",1:"好评"}
## 将模型设置为评估模式
model.eval#将训练模型转化为推理模型,模型将使用转换后的推理模式进行评估
with torch.inference_mode():## 分词&&向量化inputs = tokenizer(sen,return_tensors = "pt")## GPU加速inputs = {k:v.cuda() for k,v in inputs.items()}## 进行预测logits=model(**inputs).logits## 在logits的最后一个维度上找到最大值,并返回其所在的索引。这相当于选择模型认为最有可能的类别pred = torch.argmax(logits, dim = -1)print(f"输入:{sen} \n模型的预测结果:{id2label.get(pred.item())}")
1)第1次预测:(sen =“昨天我在酒店睡觉发现被子有一股霉味”)
输入:昨天我在酒店睡觉发现被子有一股霉味
模型的预测结果:差评
2)第2次预测:(sen =“我昨晚在酒店里睡得非常好”)
输入:我昨晚在酒店里睡得非常好
模型的预测结果:好评
总结
通过上述步骤,我们手工完成了基于Transformer库的情感分类模型预训练流程。虽然这个过程涉及了大量细节和代码编写,但它为我们提供了宝贵的洞见,让我们了解了从原始数据处理到模型训练和验证的整个流程。在后续篇章中,我们将引入更多的Transformer组件,这些高级工具将显著简化我们的开发流程,使我们能够更快捷、更高效地进行模型开发和实验

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!