论文:Query Expansion by Prompting Large Language Models
⭐⭐⭐
Google Research, arxiv:2305.03653
论文速读
之前我在论文笔记 Query2doc 中介绍了信息检索(IR)以及 Query Expansion 的相关背景知识。
本篇文章是 Google 发表的关于对 LLM 进行 prompt 来做 Query Expansion 的论文,所采取的思路与 Query2doc 相似,但侧重点不同。
论文的思路如下:
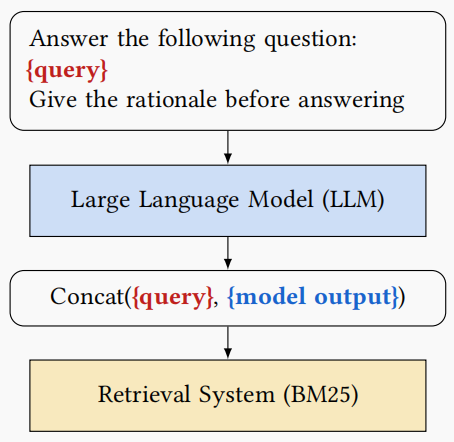
可以看到,也是把 user query 带上 prompt 输入给 LLM,然后拼接 user query 和 LLM 响应得到 Query Expansion 的结果,将其输入给 Retrieval System 来完成检索。
其中“concat”这个拼接过程,也是为了提高 user query 的权重,把 user query 重复了 5 遍再与 LLM response 拼接,做法与 Query2doc 十分相似:
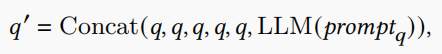
本文工作主要研究 sparse retrieval 的场景,与之前 Query2doc 的工作的区别主要如下:
- 不同 prompt 的研究:这篇文章研究了多种不同的 prompt 方式,包括 Q2D、Q2D/ZS、Q2D/PRF、Q2E、Q2E/ZS、Q2E/PRF、CoT 和CoT/PRF,而 Query2Doc 论文主要关注单一的少样本提示。(这几种 prompt 方法的具体含义可以参考原论文)
- 生成查询扩展术语:这篇文章的工作重点是生成 query expansion terms,而不是像 Query2doc 论文那样生成整个 pseudo-document 作为 expansion。
- 模型大小的多样性:这篇文章在多种不同大小的模型上测试了提示的性能,以更好地理解LLM方法在查询扩展上的实用能力和局限性。而Query2Doc论文使用的是一个更大的模型,且没有详细比较不同模型大小的性能。
- 开源模型的使用:这篇文章完全使用开源模型进行实验,以促进研究的可复制性和开放性。相比之下,Query2Doc 论文使用的是一种只能通过第三方 API 访问的特定类型的模型。
- 实验数据集:这篇文章在 MS-MARCO 和 BEIR 数据集上进行了实验,以验证 LLMs 在查询扩展中的有效性,而 Query2Doc 论文可能使用了不同的数据集或实验设置。
- 性能提升:文章中提到,通过使用CoT提示,尤其是结合PRF文档的CoT/PRF提示,可以在保持召回率的同时,提高排名指标,如MRR@10和NDCG@10,而传统的查询扩展方法可能会牺牲这些排名指标来提高召回率。
- 模型大小对性能的影响:文章还探讨了不同模型大小对查询扩展性能的影响,并发现CoT方法只需要3B参数的模型就能达到与BM25+Bo1基线相当的效果,而Q2D方法则至少需要11B参数的模型。
实验结果
本论文做了大量的实验,文中展示的实验数据对比值得一看:
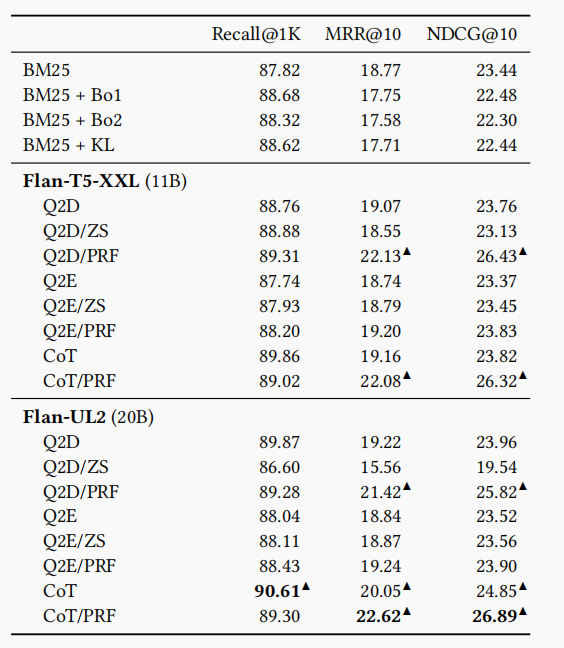
每个指标的最好结果已经用黑体进行了标注,可以看到,CoT 的 prompt 下可以让 LLM 生成的 expansion 表现更好。原文作者认为,CoT 这种特殊的 prompt 指示模型通过将其答案分解为多个步骤来生成详细的解释,这种详细性的解释可能会导致生成许多潜在的有效关键字,并对查询扩展有用。
总结
文章提出了一种新的查询扩展方法,该方法利用大型语言模型(LLMs)的生成能力。通过不同的提示方式(zero-shot, few-shot, Chain-of-Thought, CoT)来指导 LLM 生成与原始查询相关的新术语,并将其对 query 进行 expansion 从而提高检索的效果。文章做了较多实验,其实验结果值得我们一看,从而让我们对 LLM 生成 Query Expansion 的不同 prompt 有了一个不同表现的认识。
但是文章也指出了该工作的一些局限性,如只研究了稀疏检索系统,未考虑密集检索系统;仅使用了 Flan 系列的LLMs,未来可以扩展到其他模型;提示模板可能还有改进空间;LLMs 的计算成本可能限制了其在实际应用中的部署。