手写基于redis-lua脚本实现分布式id生成器starter
文章目录
1.前言
由于之前分享过一篇:百度开源分布式id生成器集成–真香警告
https://mp.weixin.qq.com/s/FDIEcLcpcaRzjDWTHiMWrg
里面提到了基于redis来实现一个分布式id生成器的思路,只是简单的说了下,本次分享就手写了一个。
2.实现思路
本文只讲思路,至于源码就不做过多的讲解,也很简单,可以拉下来看一看是如何实现的。
lua_19">2.1lua脚本的特性
利用redis执行lua脚本是原子的,这个是核心,至于lua脚本的写法千变万化。
redis_25">2.2 了解三个redis命令
首先,要知道redis的EVAL,EVALSHA、TIME命令:
http://redis.io/commands/eval
http://redis.io/commands/evalsha
http://redis.io/commands/time
2.3集群自增序列实现原理
假定集群里有3个节点,则节点1返回的seq是:
0, 3, 6, 9, 12 ...
节点2返回的seq是
1, 4, 7, 10, 13 ...
节点3返回的seq是
2, 5, 8, 11, 14 ...
这样每个节点返回的数据都是唯一的。
2.4三种实现思路
tag:是一个applicationName + ”:“ + tabName这个对应哪个业务应用的哪张表,tag是一个标记隔离各个业务表的id生成key,本文基于redis-lua脚本实现的分布式id生成器starter的实现固定redis是1-3个节点,大于三节点需要去改源码和lua脚本,所以配置只能配置1-3个redis节点信息,超过三个不支持。最大位数19位,该限制是由于mysq的bigInt的最大位数是19位,可以拓展为其它存储的主键类型的最大位支持。
2.4.1 实现思路一
前缀格式有三种,后缀都是一个自增序列:
YY + 三位天(该年第几天) +一个自增序列
YYYY + 三位天(该年第几天) +一个自增序列
YYYYMMDD + 一个自增序列
位数:8-19位
格式一:24114000000000128
格式二:20241140000000135
格式三:20240423000000003
生成的id自增长度取决于19位-去前缀格式位的长度,可以满足每日id生成亿级别的id,可以满足大多数的业务id生成场景使用。
2.4.2 实现思路二
一个自增序列
位数不限,也就是可以无限生成id
2.4.3实现思路三
7188371276761663493
利用redis的lua脚本执行功能,在每个节点上通过lua脚本生成唯一ID。 生成的ID是64位的:
- 使用41 bit来存放时间,精确到毫秒,可以使用41年。
- 使用12 bit来存放逻辑分片ID,最大分片ID是4095
- 使用10 bit来存放自增长ID,意味着每个节点,每毫秒最多可以生成1024个ID
比如GTM时间 Fri Mar 13 10:00:00 CST 2015 ,它的距1970年的毫秒数是 1426212000000,假定分片ID是53,自增长序列是4,则生成的ID是:
5981966696448054276 = 1426212000000 << 22 + 53 << 10 + 4
redis提供了TIME命令:
http://redis.io/commands/time
可以取得redis服务器上的秒数和微秒数。因为lua脚本返回的是一个四元组。
second, microSecond, partition, seq
客户端要自己处理,生成最终ID。
((second * 1000 + microSecond / 1000) << (12 + 10)) + (shardId << 10) + seq;
本实现分片设置是选取的节点个数0-3,也可以自己去拓展只要在最大分片ID是4095内即可,可以修改为取代码中自增的index的值,该实现生成的id可以反解id信息。
3.项目工程目录
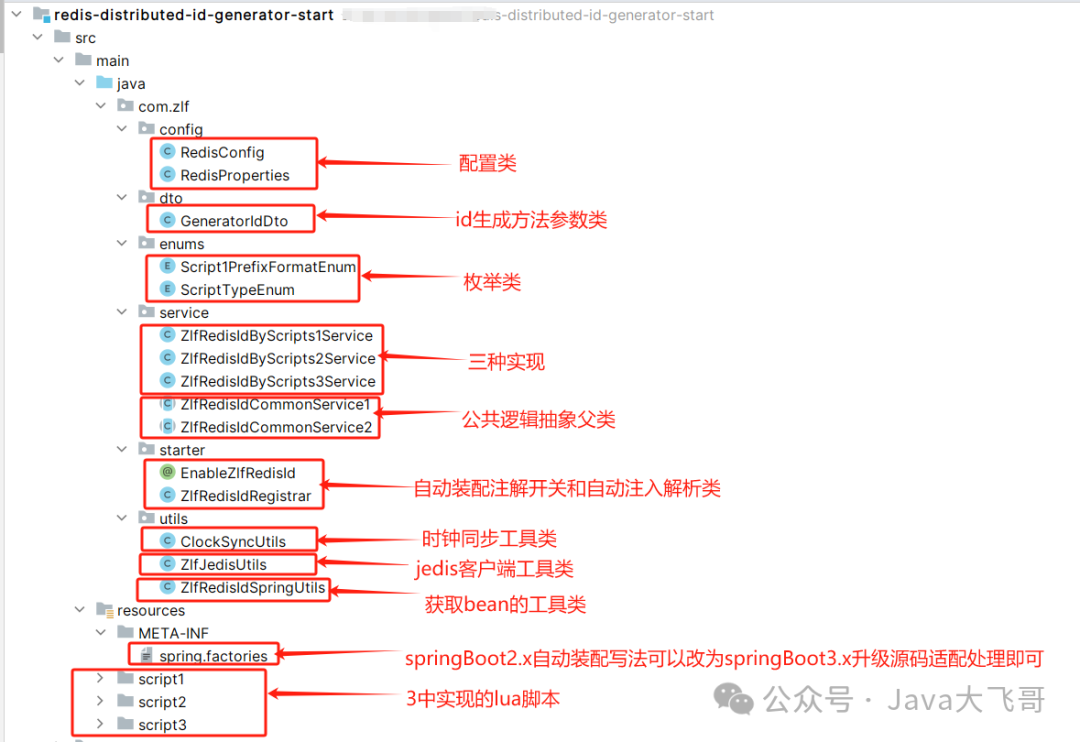
有兴趣的可以拉代码下来扒一扒,瞧一瞧看一看。
4.源码仓库地址
https://gitee.com/BigBigFeiFei/redis-distributed-id-generator-start
https://github.com/BigBigFeiFei/redis-distributed-id-generator-start
5.依赖及使用配置
5.1依赖
项目中引入如下一个依赖即可:
<dependency><groupId>io.github.bigbigfeifei</groupId><artifactId>redis-distributed-id-generator-start</artifactId><version>1.0</version>
</dependency>
或
<dependency><groupId>io.gitee.bigbigfeifei</groupId><artifactId>redis-distributed-id-generator-start</artifactId><version>1.0</version>
</dependency>
5.2nacos配置
## 配置需要保证唯一不重复(eqps中的每一的index唯一,一般配置成递增的,队列交换机绑定关系的bean注入都是根据rps的List下标+eqps中index下标注入保证了唯一性)
zlf-redis-id-generator:redis:rps:- redis-host: xxxx1redis-port: 6379redis-pass: 12345678- redis-host: xxxx2redis-port: 6379redis-pass: 12345678- redis-host: xxxx3redis-port: 6379redis-pass: 12345678
5.3.启动类上加入如下注解
@EnableZlfRedisId
5.4使用
package xxxx.controller;import com.zlf.dto.GeneratorIdDto;
import com.zlf.service.ZlfRedisIdByScripts1Service;
import com.zlf.service.ZlfRedisIdByScripts2Service;
import com.zlf.service.ZlfRedisIdByScripts3Service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("id")
public class IdGcontroller {@Autowiredprivate ZlfRedisIdByScripts1Service zlfRedisIdByScripts1Service;@Autowiredprivate ZlfRedisIdByScripts2Service zlfRedisIdByScripts2Service;@Autowiredprivate ZlfRedisIdByScripts3Service zlfRedisIdByScripts3Service;@GetMapping("getId1")public Long getId1() {GeneratorIdDto dto = new GeneratorIdDto();dto.setApplicationName("t_id1");dto.setTabName("id1");dto.setLength(16);return zlfRedisIdByScripts1Service.generatorIdByLength(dto);}@GetMapping("getId2")public Long getId2() {GeneratorIdDto dto = new GeneratorIdDto();dto.setApplicationName("t_id2");dto.setTabName("id2");return zlfRedisIdByScripts2Service.generatorId(dto);}@GetMapping("getId3")public Long getId3() {GeneratorIdDto dto = new GeneratorIdDto();dto.setApplicationName("t_id3");dto.setTabName("id3");return zlfRedisIdByScripts3Service.generatorId(dto);}}
6.性能压测
单台redis机器压测可以抗住单机redis最大并发吞吐量,redis单台配置最大并发数可达100w,三台可达300w,由于我机器资源有限,使用的是一个redis压测1000000线程,循环1s,Ram-Up:1s由于会遇到一个apache-jmeter-5.6.3在windows下开了多个线程会导致TCPIP端口被占用,从而导致压测Jmeter 报错:
Address already in use: connect
所以解决办法是:
https://blog.csdn.net/qq_24857309/article/details/111477286报错原因:
1、windows系统为了保护本机,限制了其他机器到本机的连接数.
2、TCP/IP 可释放已关闭连接并重用其资源前,必须经过的时间。关闭和释放之间的此时间间隔通称 TIME_WAIT 状态或两倍最大段生命周期(2MSL)状态。此时间期间,重新打开到客户机和服务器的连接的成本少于建立新连接。减少此条目的值允许 TCP/IP 更快地释放已关闭的连接,为新连接提供更多资源。如果运行的应用程序需要快速释放和创建新连接,而且由于 TIME_WAIT 中存在很多连接,导致低吞吐量,则调整此参数。修改操作系统注册表
1、打开注册表:regedit
2、找到HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TCPIP\Parameters
3、新建 DWORD值,name:TcpTimedWaitDe,value:30(十进制) ——> 设置为30秒(默认240)
4、新建 DWORD值,name:MaxUserPort,value:65534(十进制) ——> 设置最大连接数65534
注意:修改时先选择十进制,再填写数字。5、重启系统
所以需要将注册表的TcpTimedWaitDe、MaxUserPort值修改,本文修改后压缩1000000,一百万线程还是会报这个错的,所以需要将MaxUserPort在改大一点。
由于我的机器资源有限,所以压测只做了一个简单的压测,没有做更详细的压测,压测结果还是可以的,性能吞吐量各方面还是可以的,有兴趣,有条件的可以去压测一下,如果压测了,有详细的压测报告,可以联系我,给我一份详细的压测报告,或者在压测或使用过程中发现啥问题,可以联系我,或者有啥好的修复方案也可以联系我,我们一起维护完善这个项目。
7.缺点
本文基于redis-lua脚本实现的分布式id生成器starter有一个缺点就是,不能去清理redis生成使用的database库或这个database库里面跟id生成有关key的信息,否则清理之后重新生成id会重复,所以对于第一种实现需要重新修改id的长度来避免,第二种和第三种实现是没有长度可以修改的,第三种可以修改分区,这个本文实现没有对这个分区做拓展,所以除了第二种没有解决方法,第三种应该不会有影响,只要保证使用本文依赖包所在服务器和redis的服务器的时钟正常即可,第一二种实现不会有时钟回拨的问题,时间取决于使用依赖应用所在服务器的时间,实现三取决于redis服务的时钟,所以还是确保应用服务器、redis集群服务器的时钟都是正常的,那么生成的id就不会有啥问题的,也更加准确,第一种实现生成的id可读性更好一点,但是是牺牲了前几位站位代价的,这就意味着前面格式占位越多,后面可用序列的长度就越短,生成可用的序列号就越少,这就是一个取舍。
8.总结
本文手写基于redis-lua脚本实现的分布式id生成器starter分享到此结束了,我把我手写的轮子开源出去,可以让java又多了一种分布式id生成的选择,解决了分布式id生成的问题,开源才能繁荣,通过本文的分享和之前文章的分享,在解决分布式id生成问题选择上丰富起来了,各种实现上基本都是类似和相通的,希望我的分享对你有所启发和帮助,请一键三连!
![[BT]BUUCTF刷题第20天(4.22)](https://img-blog.csdnimg.cn/direct/9c1d6a5066594a6491083345ec98b2a5.png)