【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
- 一、延后初始化
- 实例化网络
- 二、自定义层
- (一)不带参数的层
- (二)带参数的层
- 小结
一、延后初始化
到目前为止,我们忽略了建立网络时需要做的以下这些事情:
- 我们定义了网络架构,但没有指定输入维度。
- 我们添加层时没有指定前一层的输出维度。
- 我们在初始化参数时,甚至没有足够的信息来确定模型应该包含多少参数。
有些读者可能会对我们的代码能运行感到惊讶。 毕竟,深度学习框架无法判断网络的输入维度是什么。 这里的诀窍是框架的延后初始化(defers initialization), 即直到数据第一次通过模型传递时,框架才会动态地推断出每个层的大小。
在以后,当使用卷积神经网络时, 由于输入维度(即图像的分辨率)将影响每个后续层的维数, 有了该技术将更加方便。 现在我们在编写代码时无须知道维度是什么就可以设置参数, 这种能力可以大大简化定义和修改模型的任务。 接下来,我们将更深入地研究初始化机制。
实例化网络
首先,让我们实例化一个多层感知机。此时,因为输入维数是未知的,所以网络不可能知道输入层权重的维数。 因此,框架尚未初始化任何参数,我们通过尝试访问以下参数进行确认。
接下来让我们将数据通过网络,最终使框架初始化参数。
一旦我们知道输入维数是20,框架可以通过代入值20来识别第一层权重矩阵的形状。 识别出第一层的形状后,框架处理第二层,依此类推,直到所有形状都已知为止。 注意,在这种情况下,只有第一层需要延迟初始化,但是框架仍是按顺序初始化的。 等到知道了所有的参数形状,框架就可以初始化参数。
二、自定义层
深度学习成功背后的一个因素是神经网络的灵活性:我们可以用创造性的方式组合不同的层,从而设计出适用于各种任务的架构。例如,研究人员发明了专门用于处理图像、文本、序列数据和执行动态规划的层。有时我们会遇到或要自己发明一个现在在深度学习框架中还不存在的层。在这些情况下,必须构建自定义层。本节将展示如何构建自定义层。
(一)不带参数的层
首先,我们构造一个没有任何参数的自定义层。回忆一下在【现代深度学习技术】深度学习计算 | 层和块 对块的介绍,这应该看起来很眼熟。下面的CenteredLayer类要从其输入中减去均值。要构建它,我们只需继承基础层类并实现前向传播功能。
import torch
import torch.nn.functional as F
from torch import nnclass CenteredLayer(nn.Module):def __init__(self):super().__init__()def forward(self, X):return X - X.mean()
让我们向该层提供一些数据,验证它是否能按预期工作。
layer = CenteredLayer()
layer(torch.FloatTensor([1, 2, 3, 4, 5]))
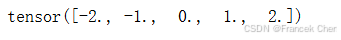
现在,我们可以将层作为组件合并到更复杂的模型中。
net = nn.Sequential(nn.Linear(8, 128), CenteredLayer())
作为额外的健全性检查,我们可以在向该网络发送随机数据后,检查均值是否为0。由于我们处理的是浮点数,因为存储精度的原因,我们仍然可能会看到一个非常小的非零数。
Y = net(torch.rand(4, 8))
Y.mean()

(二)带参数的层
以上我们知道了如何定义简单的层,下面我们继续定义具有参数的层,这些参数可以通过训练进行调整。我们可以使用内置函数来创建参数,这些函数提供一些基本的管理功能。比如管理访问、初始化、共享、保存和加载模型参数。这样做的好处之一是:我们不需要为每个自定义层编写自定义的序列化程序。
现在,让我们实现自定义版本的全连接层。回想一下,该层需要两个参数,一个用于表示权重,另一个用于表示偏置项。在此实现中,我们使用修正线性单元作为激活函数。该层需要输入参数:in_units和units,分别表示输入数和输出数。
class MyLinear(nn.Module):def __init__(self, in_units, units):super().__init__()self.weight = nn.Parameter(torch.randn(in_units, units))self.bias = nn.Parameter(torch.randn(units,))def forward(self, X):linear = torch.matmul(X, self.weight.data) + self.bias.datareturn F.relu(linear)
接下来,我们实例化MyLinear类并访问其模型参数。
linear = MyLinear(5, 3)
linear.weight

我们可以使用自定义层直接执行前向传播计算。
linear(torch.rand(2, 5))

我们还可以使用自定义层构建模型,就像使用内置的全连接层一样使用自定义层。
net = nn.Sequential(MyLinear(64, 8), MyLinear(8, 1))
net(torch.rand(2, 64))