一、读取数据
- 示例代码
python">import pandaspeople = pandas.read_excel('../002/People.xlsx') #读取People数据
print(people.shape) # 打印people表的行数、列数
print(people.head(3)) # 默认打印前5行,当前打印前3行
print("==============================================")
print(people.tail(3)) # 默认打印后5行,当前打印后3行
print("==============================================")
print(people.columns)
-
项目目录

-
运行结果

二、数据处理
实战一:表头脏数据
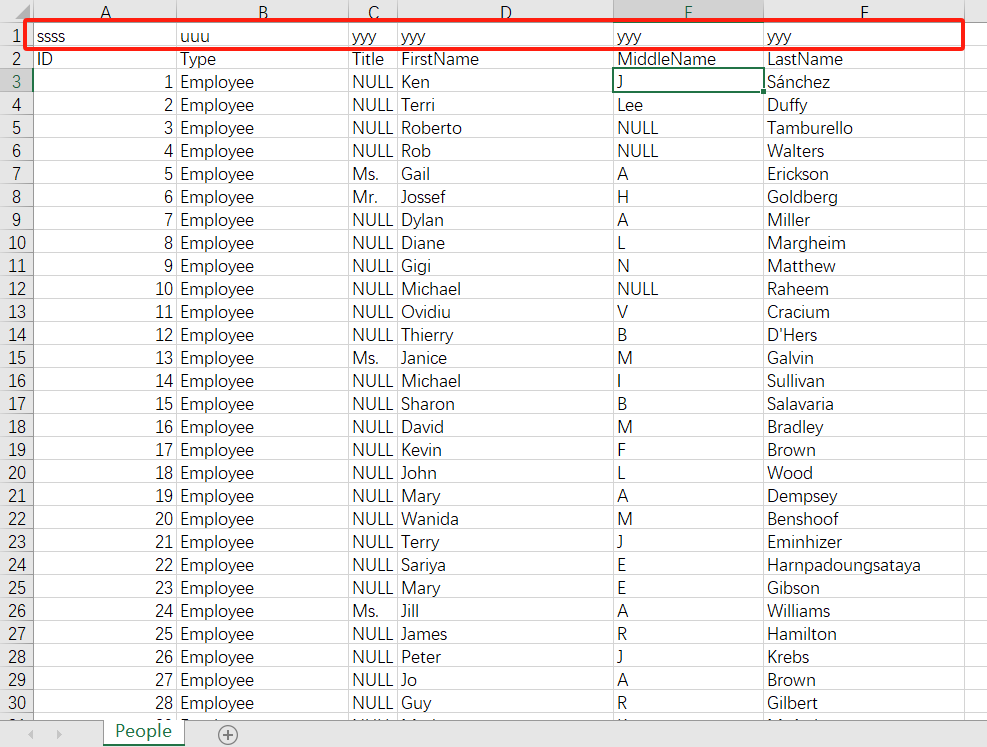
- 表中有脏数据情况,columns 时会读取第一行脏数据
python">import pandaspeople = pandas.read_excel('../002/People.xlsx') #读取People数据
print(people.columns)

- 处理方法,read_excel方法中修改 headers 参数值
python">import pandaspeople = pandas.read_excel('../002/People.xlsx',header=1) #读取People数据
print(people.columns)

实战二:指定序列号
-
未指定索引值,将数据写入新表时,会自动创建序列号,默认从0开始

-
可指定 ID 为索引号,read_excel 方法中补充 index_col 参数,使 index_col = ‘ID’
python">import pandaspeople = pandas.read_excel('../002/People.xlsx', index_col='ID') #读取People数据,使用‘ID’做序号
people.to_excel('../002/People_copy.xlsx') #将People.xlsx数据写入People_copy.xlsx,
print('done!')






