一、框架思想
requests+yaml+pytest+allure实现接口自动化框架。结合数据驱动和分层思想,将代码与数据分离,易维护,易上手。使用yaml编写编写测试用例,利用requests库发送请求,使用pytest管理用例,allure生成测试报告,后续可能加上CI 持续集成(Jenkins)。
数据驱动是整个框架的核心
什么是数据驱动?
在接口测试中,测试用例可能有上百条,如果将用例全部写在代码中,一旦需要修改,将会消耗大量的时间,不容易维护。所以,我们就要测试数据,或者测试用例存储到文件中,用代码读取文件获取数据,实现数据驱动。
数据驱动分为两种:
1、参数的数据驱动
2、用例的数据驱动
| json | 格式完备,格式死板,不能写注释 |
| yaml | 格式完备,格式简单,可注释 |
| csv | 可以使用excel编辑,文本格式方便管理 |
| xml | 格式完备,冗长复杂 |
二、yaml基本语法
大小写敏感
使用缩进表示层级关系
缩进时不允许使用Tab键,只允许使用空格。
缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
yaml支持三种数据结构:
对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
纯量(scalars):单个的、不可再分的值
数组:
- Cat
- Dog
- Goldfish也可写成:列表嵌套列表
-- Cat- Dog- Goldfish字典与列表嵌套:-id:login_02三、读取yaml
yaml.load和safe_load()
两者区别:
safe_load()可以解析简单的数据结构,而且比较安全,load可以解析比较复杂的数据结构,通常一般使用的最多的还是load()
四、测试用例数据驱动
-id: login_01title: 登录成功url: member/loginmethod: POSTrequest_data: {"mobile_phone": "17866554324","pwd":"188888"}expect: {"code":0,"msg":"OK"}#读取yamldef read_yaml(self):with open(self.filename, encoding='utf-8') as fs:# 避免报警告:yaml.FullLoaderdata = yaml.load(fs, Loader=yaml.FullLoader)return data
五、参数化数据驱动
将测试用例部分数据进行参数化,比如用户名密码之类的数据。 然后将数据放入配置文件中
[case_data]
mobile_phone = 11111111111
pwd = 123456789
六.使用正在表达式替换参数化数据
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式的大致匹配过程是: 1.依次拿出表达式和文本中的字符比较, 2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。 3.如果表达式中有量词或边界,这个过程会稍微有一些不同。 正则表达式贪婪模式:尽可能多的匹配 非贪婪模式:尽可能少的匹配
引入模块
import re
方法:
1.compile(pattern[,flag]):对正则表达式pattern进行编译,编译后比直接查找速度快
2.match(patter,string[,flag]):从字符串string的开始就匹配,若匹配成功,则返回匹配对象,否则返回None(None对象没有group()和groups()方法,不判断直接调用这两个方法,则会出现异常)
3.search(pattern,string[,flag]):从字符串中查找,若匹配成功,则返回匹配对象,否则返回None
4.findall(pattern,string[,flag]):在字符串 string 中查找正则表达式模式 pattern 的所有(非重复)出现;返回一个匹配对象的列表
5.finditer(pattern,string[, flags])b 和 findall()相同,但返回的不是列表而是迭代器;对于每个匹配,该迭代器返回一个匹配对象
6.split(pattern,string, max=0) 根据正则表达式 pattern 中的分隔符把字符 string 分割为一个列表,返回成功匹配的列表,最多分割 max 次(默认是分割所有匹配的地方)
7.sub(pattern, repl, string, max=0) 把字符串 string 中所有匹配正则表达式 pattern 的地方替换成字符串 repl,如果 max 的值没有给出, 则对所有匹配的地方进行替换
代码如下(示例):res=re.findall("#(.*?)#",data)
七、发送请求
使用第三方库requests 请求方式:get/post/put/delete
代码如下(示例):
def send_request(method,url,data,header):if method=="POST":res=requests.post(url,json=data,headers=header)elif method=="GET":res = requests.post(url, params=data, headers=header)elif method=="PUT":'''封装put方法,uri是访问路由,params是put请求需要传递的参数,如果没有参数这里为空:param uri: 访问路由:param params: 传递参数,string类型,默认为None:return: 此次访问的response'''if data is not None:# 如果有参数,那么通过put方式访问对应的url,并将参数赋值给requests.put默认参数data# 返回request的Response结果,类型为requests的Response类型res=requests.put(url,json=data,headers=header)else:# 如果无参数,访问方式如下# 返回request的Response结果,类型为requests的Response类型res = requests.put(url)elif method=="DELETE":'''封装delete方法,uri是访问路由,params是delete请求需要传递的参数,如果没有参数这里为空:param uri: 访问路由:param params: 传递参数,string类型,默认为None:return: 此次访问的response'''if data is not None:# 如果有参数,那么通过put方式访问对应的url,并将参数赋值给requests.put默认参数data# 返回request的Response结果,类型为requests的Response类型res=requests.delete(url,data=data,headers=header)else:# 如果无参数,访问方式如下# 返回request的Response结果,类型为requests的Response类型res = requests.delete(url,headers=header)else:logger.info("无效的请求方式,get/post/put/delete,请查找原因!!!")return reslogger.info("响应数据为{}".format(res.json))
八、pytest管理用例
为什么选择pytest,不选择unittest?
pytest特点:
简单灵活,容易上手;支持参数化; 测试用例的skip和xfail 处理;
能够支持简单的单元测试和复杂的功能测试,还可以用来做 selenium/appium等自动化测试、接口自动化测试 (pytest+requests);
pytest具有很多第三方插件,并且可以自定义扩展, 比较好 用的如 pytest-allure(完美html测试报告生成) pytest-xdist (多CPU分发)等;
可以很好的和jenkins集成;**
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
pytest框架结构:
Import pytest 类似的setup,teardown同样更灵活
模块级 (setup_module/teardown_module)
全局的,整个.py模块开始前和结束后调用一次
函数级 (setup_function/teardown_function)
只对函数用例生效(不在类内),每个函数级用例开始和结束时调用一次
类级 (setup_class/teardown_class)
只在类前后运行一次(在类中)。
方法级 (setup_method/teardown_methond)
运行在类中方法始末
类里面的(setup/teardown):运行在调用方法的前后
类中运行顺序:setup_class>setup_method>setup>用例>teardown>teardown_method>teardown_class
pytest执行方式:
Pytest –v (最高级别信息—verbose)
pytest -v -s filename 3.Pytest-q (静默)
(输出打印)
多种执行方式
1.pytest将在当前目录及其子目录中运行test _ * .py或* test.py形 式的所有文件。
2.以test_开头的函数,以Test开头的类,以test_开头的方法。所有包 package都要有__init_.py文件。
3.Pytest可以执行unittest框架写的用例和方法
可以在pytest.ini文件中自定义要运行的测试路径、文件名、类名和方法名等。
pytest断言
mark中skip的使用:
1、不想运行部分用例
2、标记无法运行的测试用例
3、当前外部资源不可用
4、在某些版本中跳过
mark中xfail的使用
1、功能尚未实施或尚未修复,使用@pytest.mark.xfail标记,会是一个xpass,在测试报告中
自定义的标记,可以只执行部分用例
1、当回归测试,只需要执行部分用例时。
pytest中的fixture
在pytest中可以灵活使用fixture,不需要每一个用例都写fixture,写好一个只需要调用就可以
@pytest.fixture(scope="class")
def init():logger.info("=========================开始执行测试项目=========================")yieldlogger.info("=========================测试项目执行完毕=========================")1.机制:与测试用例同级,或者是测试用例的父级,创建一个conftest.py文件。
2.conftest.py文件里:放所有的前置和后置。 不需要用例.py文件主动引入conftest文件。
3.定义一个函数:包含前置操作+后置操作。
4.把函数声明为fixture :在函数前面加上 @pytest.fixture(作用级别=默认为function)
5.fixture的定义。
如果有返回值,那么写在yield后面。(yield的作用就相当于return)
在测试用例当中,调用有返回值的fixture函数时,函数名称就是代表返回值。
在测试用例当中,函数名称作为用例的参数即可。
@pytest.mark.sign
@allure.epic("测试项目")
@allure.feature("登录模块")
@pytest.mark.usefixtures("init")
class Test_Login:@pytest.mark.parametrize("case",cases)def test_login(self,case):res=send_request(case["method"],case["url"],json.loads(case["request_data"]))expect=json.loads(case["expect"])logger.info("期望结果为{}".format(expect))logger.info("响应结果为:{}".format(res.json()))if expect:try:assert res.json()["code"]==expect["code"]except Exception as e:logger.info("断言失败")raisereturn res进阶方法:conftest中定义多个fixture,一个fixture可以是另一个fixture的前后置,期间还是用yield隔开前后置
参数化与数据驱动框架实现
使用@pytest.mark.parametrize(“case”,cases)实现参数化
当每个测试用例需要不同的测试数据是,可以直接获取
调整测试用例的执行顺序
比如:添加功能模块的用例要先执行,删除功能模块的用例要后执行,可以使用第三方插件
pip install pytest-ordering
在测试方法上加上装饰器:@pytest.mark.last (—最后一个执行) @pytest.mark.run(order=1) (第几个执行)
多线程并行与分布式执行
当用例数量太多时,可以考虑多线程并行,分布式执行
插件:pip3 install pytest-xdist
多个cpu执行,pytest -n 3
import pytest
import time@pytest.mark.parametrize('x',list(range(10)))
def test_somethins(x):time.sleep(1)pytest -v -s -n 5 test_xsdist.py ----一次执行5个 九、allure测试报告
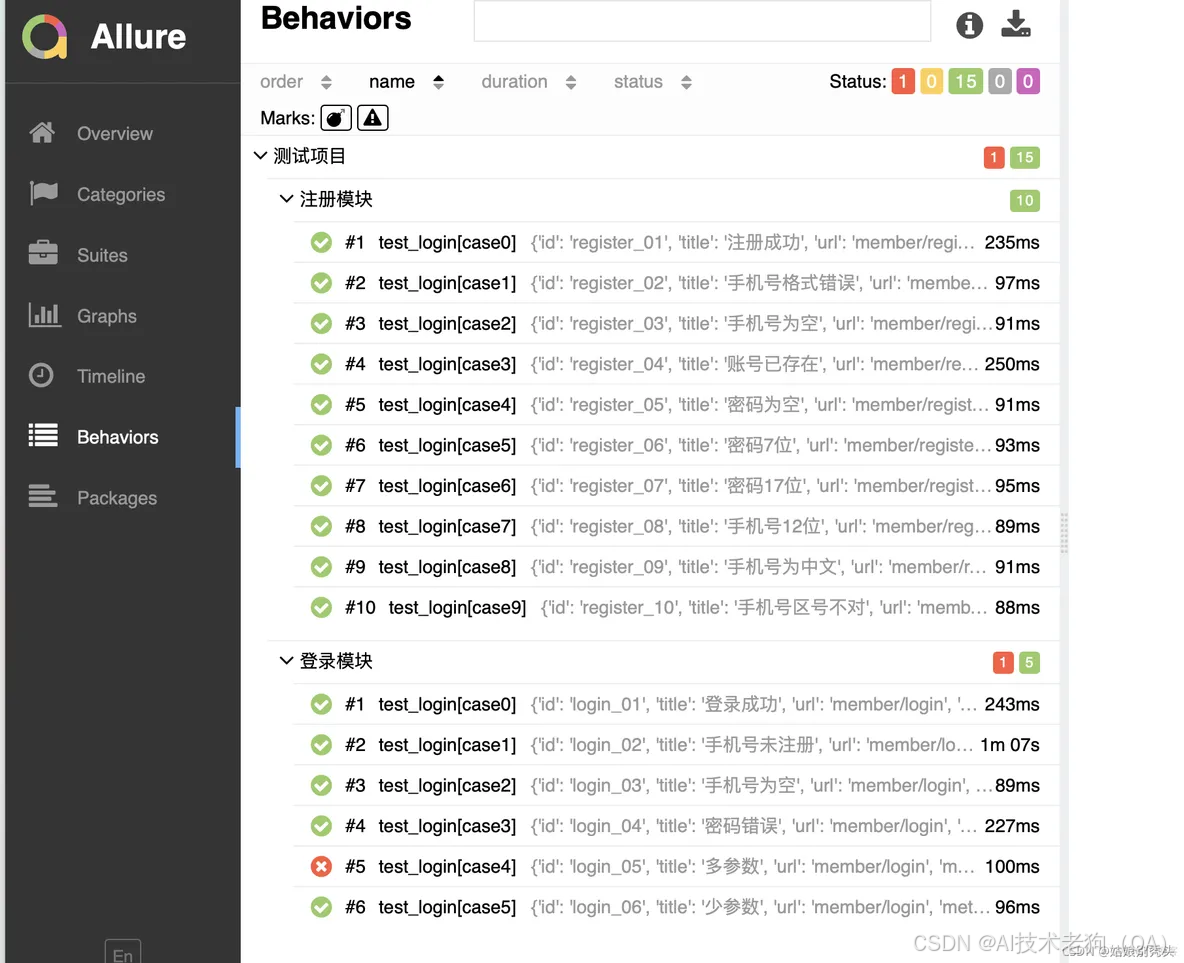
定制化测试报告
Feature: 标注主要功能模块
Story: 标注Features功能模块下的分支功能
Severity: 标注测试用例的重要级别
Step: 标注测试用例的重要步骤
Issue和TestCase: 标注Issue、Case,可加入URL
上述组合框架可以快速简单的实现相应的接口测试,简单上手快,同学们可以亲手实验一下。