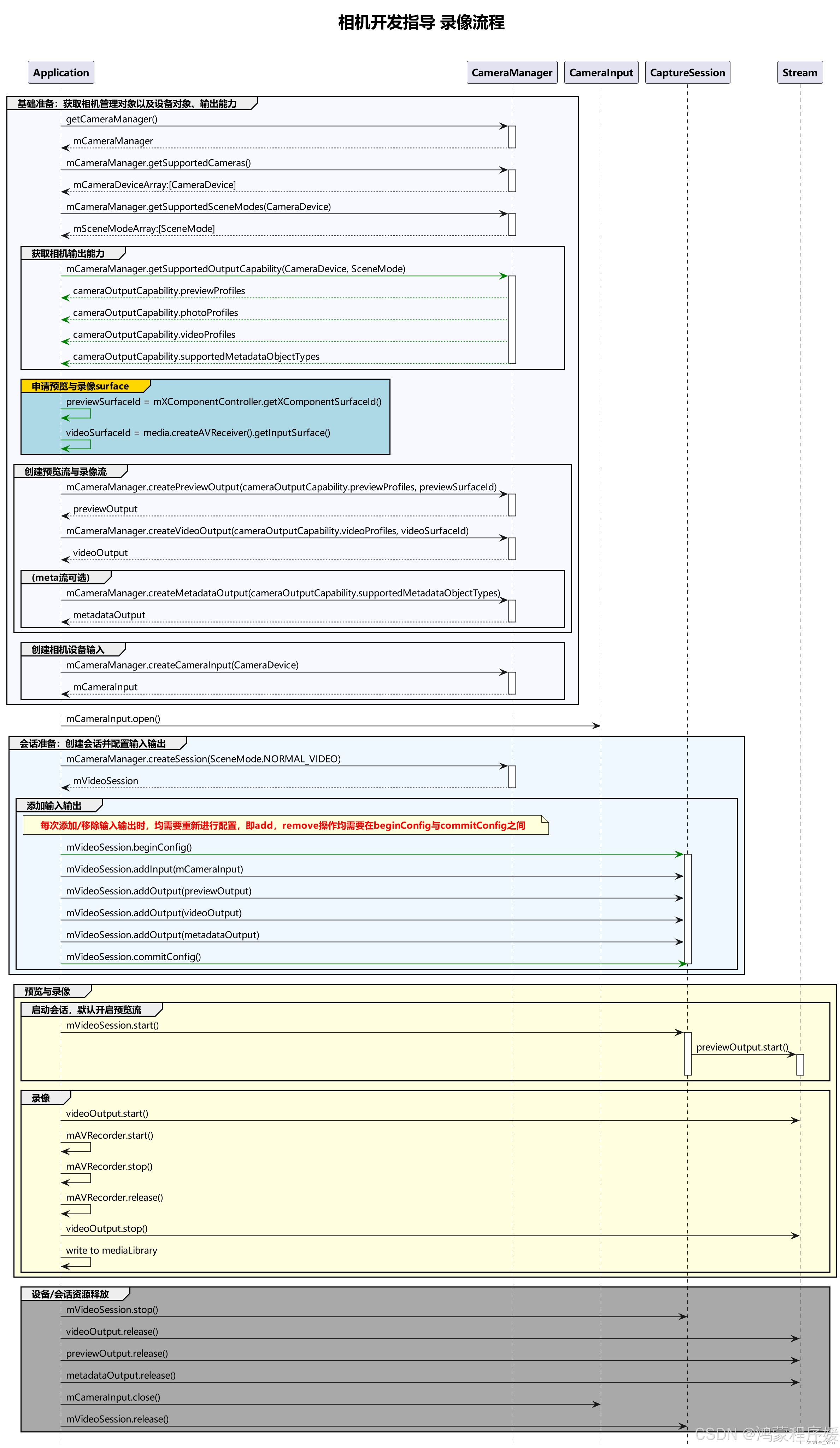
[1].介绍一下CAP理论
CAP理论是指在分布式系统设计中,没有一种设计可以同时满足Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)3个特性,最多只能同时满足三个特性中的两个。
一致性强调的是所有节点在同一时刻看到的数据必须是相同的;
可用性强调的是系统能够持续正常运行并对外提供服务;
分区容错性强调的是系统中任意信息的丢失或失败不会影响系统的继续运作。
kafka_producer_9">[2].kafka producer写入数据的过程
- Producer通过ZooKeeper找partition对应的leader;
- Producer将消息发送给该Leader;
- Leader将消息写入本地log;
- Followers从Leader pull消息,写入本地log后向Leader发送ACK;
- Leader收到所有ISR中的Replication的ACK后,增加HW并向Producer发送ACK;
kafka_16">[3].kafka为什么使用拉取消息的机制?
简化了Kafka Broker的设计,Broker只需存储消息等待消费者拉取,无需主动推送消息。
消费者可以根据自身处理能力和负载情况自主决定从broker拉取消息的频率和数量,能够有效控制消息的消费速度,可有效避免消息堆积和消费压力过大的问题。
Kafka可以选择批量拉取消息,减少网络开销,提高吞吐量,还能灵活控制拉取间隔,实现实时或批量处理模式。
[4].手撕:Java实现LRU
哈希表+双向链表
java">class LRUCache {int capacity;Map<integer, listnode> map;MyQueue queue;public LRUCache(int initialCapacity) {// 初始化LRU缓存的容量this.capacity = initialCapacity;// 使用HashMap来存储缓存项,其中键为键,值为对应的值this.map = new HashMap<>();// 初始化一个MyQueue对象,用于记录缓存项的访问顺序// 保留初始化逻辑以设置MyQueue的初始状态// MyQueue将用于管理缓存项的访问顺序,以支持LRU(最近最少使用)策略this.queue = new MyQueue();}public int get(int key) {// 检查map中是否包含指定的keyif (!map.containsKey(key)) {// 如果不包含,则返回-1表示未找到return -1;}// 从map中获取与key对应的ListNode节点ListNode node = map.get(key);// 将获取到的节点移动到队列的尾部queue.moveToTail(node);// 返回节点的值return node.val;}public void put(int key, int value) {ListNode node;// 检查map中是否已经存在该keyif (map.containsKey(key)) {// 如果存在,获取对应的节点node = map.get(key);// 更新节点的值node.val = value;// 将节点移动到队列的尾部,表示最近被访问queue.moveToTail(node);} else {// 如果map已满,则移除队列头部的节点及其对应的键值对if (map.size() == capacity) {map.remove(queue.removeHead());}// 创建一个新的节点node = new ListNode(key, value);// 将新的键值对添加到map中map.put(key, node);// 将新节点添加到队列的尾部queue.addToTail(node);}}
}
class MyQueue{ListNode head;ListNode tail;public MyQueue() {// 创建一个新的头节点head = new ListNode();// 创建一个新的尾节点tail = new ListNode();// 将头节点的next指针指向尾节点,表示队列为空时,头尾节点直接相连head.next = tail;// 将尾节点的pre指针指向头节点,实现双向链表的闭合tail.pre = head;}public void addToTail(ListNode node) {// 设置新节点的前驱节点为原尾节点tail.pre.next = node;// 设置新节点的前驱节点为原尾节点的前驱节点node.pre = tail.pre;// 设置新节点的后继节点为原尾节点node.next = tail;// 更新原尾节点的前驱节点为新节点tail.pre = node;}public int removeHead() {// 如果队列中只有一个节点(头尾相连),则返回-1表示队列为空if (head.next == tail) {return -1;}// 获取待移除节点的键值int headKey = head.next.key;// 移除队列头部的节点removeNode(head.next);// 返回被移除节点的键值return headKey;}public void moveToTail(ListNode node) {// 从队列中移除指定节点removeNode(node);// 将指定节点添加到队列的尾部addToTail(node);}public void removeNode(ListNode node) {// 将当前节点的前一个节点的next指针指向当前节点的下一个节点// 这样,前一个节点就跳过了当前节点,直接指向了下一个节点node.pre.next = node.next;// 将当前节点的下一个节点的pre指针指向当前节点的前一个节点// 这样,下一个节点的前一个节点就变成了当前节点的前一个节点// 实现了当前节点从双向链表中被移除node.next.pre = node.pre;}
}class ListNode{int key;int val;ListNode pre;ListNode next;public ListNode(){}public ListNode(int key, int value){this.key = key;this.val = value;}
}