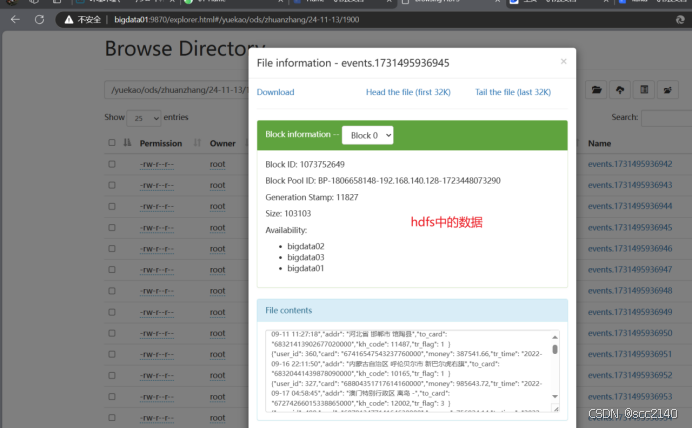
抽取trans_info.json的数据到kafka上,对其中的tr_flag=0的数据进行过滤抛弃,只保留正常的状态数据: 将此json文件放在集群中的 /home/zidingyi/trans_info.json 目录下
首先先在java代码中自定义拦截器:
1):创建maven项目,在pom文件中导入相关依赖
<dependencies><!-- https://mvnrepository.com/artifact/org.apache.flume/flume-ng-core --><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version></dependency><!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.48</version></dependency>
</dependencies><!--可以使用maven中的某些打包插件,不仅可以帮助我们打包代码还可以打包所依赖的jar包--><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><configuration><!-- 禁止生成 dependency-reduced-pom.xml--><createDependencyReducedPom>false</createDependencyReducedPom></configuration><executions><!-- Run shade goal on package phase --><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><relocations><relocation><!-- 解决包冲突 进行转换--><pattern>com.google.protobuf</pattern><shadedPattern>shaded.com.google.protobuf</shadedPattern></relocation></relocations><artifactSet><excludes><exclude>log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude></excludes></filter></filters><transformers><!-- 某些jar包含具有相同文件名的其他资源(例如属性文件)。 为避免覆盖,您可以选择通过将它们的内容附加到一个文件中来合并它们--><transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"><resource>reference.conf</resource></transformer><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>mainclass</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins>
</build>自定义拦截器代码:
package com.bigdata;import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.util.ArrayList;
import java.util.List;public class zidingyi implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {String body = new String(event.getBody());JSONObject jsonObject = JSONObject.parseObject(body);//获取json中的值int trFlag = jsonObject.getInteger("tr_flag");// 如果tr_flag中的值为0,就返回空if (trFlag == 0){return null;}return event;}@Overridepublic List<Event> intercept(List<Event> list) {ArrayList<Event> filterEvents = new ArrayList<>();for (Event event : list) {Event intercept = intercept(event);if (intercept != null){filterEvents.add(intercept);}}return filterEvents;}@Overridepublic void close() {}public static class BuilderEvent implements Builder{@Overridepublic Interceptor build() {return new zidingyi();}@Overridepublic void configure(Context context) {}}}使用maven打包,生成jar包后上传到flume下的lib目录下
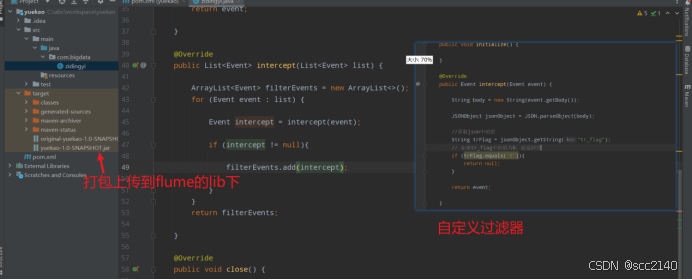
2):上传好jar包后,在flume下的conf中创建了一个myconf文件,创建一个zidinfyi.conf文件,编写flume的conf文件即可(记得使用自定义拦截器)
a1.sources = r1
a1.sinks = k1
a1.channels = c1# Describe/configure the source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /home/zidingyi/trans_info.json#使用自定义拦截器
a1.sources.s1.interceptors = i1
# type指的是编写java代码所在目录的路径名(我的是在com.bigdata.zidingyi下)
a1.sources.s1.interceptors.i1.type = com.bigdata.zidingyi$BuilderEvent# 修改sink为kafka
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = bigdata01:9092
a1.sinks.k1.kafka.topic = zidingyi
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1执行之前,先在kafka中创建消息队列(topic)中创建一个topic :zidingyi 数据将会导入到这个topic中
创建好后执行conf文件即可
flume-ng agent -c ./ -f zidingyi.conf -n a1 -Dflume.root.logger=INFO,console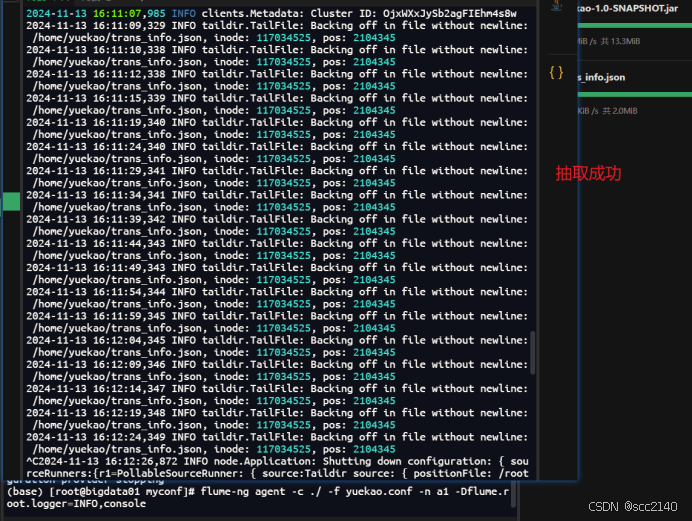
可以使用
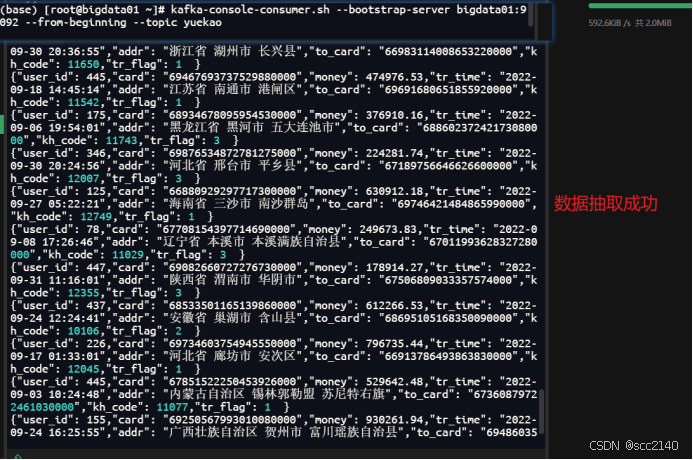
kafka-console-consumer.sh --bootstrap-server bigdata01:9092 --from-beginning --topic zidingyi把主题中所有的数据都读取出来(包括历史数据)并且还可以接收来自生产者的新数据
3):将topic中的数据抽取到hdfs中
里面的group.id随便指定即可
执行此conf文件即可
flume-ng agent -c ./ -f zidingyi2.conf -n a1 -Dflume.root.logger=INFO,consolea1.sources = r1
a1.sinks = k1
a1.channels = c1# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 100
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = bigdata01:9092,bigdata02:9092,bigdata03:9092
a1.sources.r1.kafka.topics = zidingyi
a1.sources.r1.kafka.consumer.group.id = donghu# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /zidingyi/ods/clearDate/%y-%m-%d/%H%M/
a1.sinks.k1.hdfs.filePrefix = events
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.useLocalTimeStamp=truea1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollSize = 102400
a1.sinks.k1.hdfs.rollInterval = 0a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text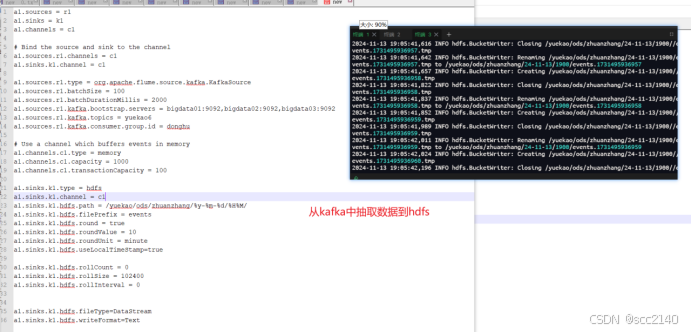
数据抽取成功