研究背景
- 研究问题:这篇文章要解决的问题是大型语言模型(LLMs)在生成输出时存在的事实不准确性,即所谓的幻觉问题。尽管LLMs在各种实际应用中表现出色,但当遇到超出训练语料库范围的新知识时,它们通常会生成不准确的信息。
- 研究难点:该问题的研究难点包括:现有的方法主要依赖LLMs自身进行知识图谱(KG)知识提取,这种方法的灵活性较差,因为LLMs只能对知识(例如KG中的知识路径)是否应该使用提供二元判断。此外,LLMs倾向于仅选择与输入文本有直接语义关系的知识,而可能会忽略具有间接语义关系的有用知识。
- 相关工作:为了解决这一问题,已有研究提出了在训练阶段或推理阶段将新知识整合到LLMs中的方法。然而,这些方法通常需要大量的计算资源。最近的研究表明,通过提示工程将新知识与输入文本一起引入是一种高效的方法。
研究方法
这篇论文提出了一个名为KELP(Knowledge Graph-Enhanced Large Language Models via Path Selection)的新方法,用于解决LLMs在生成输出时的事实不准确性。具体来说,KELP通过以下三个阶段的框架来处理上述问题:
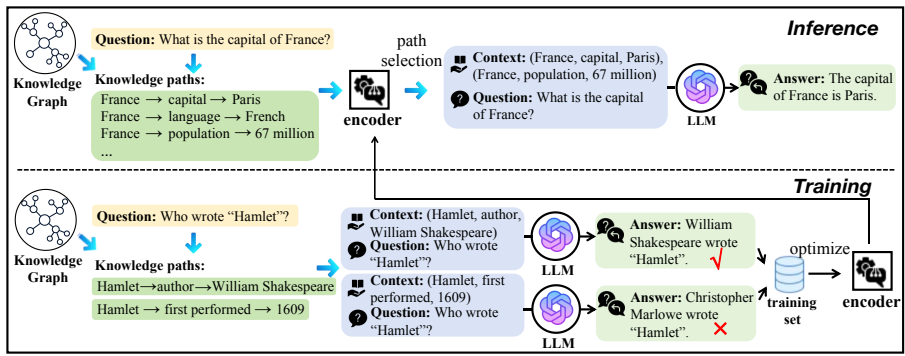
- 知识路径提取:首先,从背景KG中提取与输入文本中的实体相关的知识路径。对于每个实体,提取所有1跳和2跳的知识路径作为候选知识。
- 样本编码:其次,使用一个在潜在语义空间上训练的句子编码器M对输入问题q和提取的知识路径进行编码,以获得它们的距离(即路径对LLMs输出的潜在影响),从而确保捕捉到路径中有潜在影响力的知识。
- 细粒度路径选择:最后,基于余弦相似度分数引入两个覆盖规则,进一步细化所选路径,以确保选择的路径具有高灵活性。具体步骤如下:
- 将所有实体的路径集聚合成一个总路径集PqPq。
- 对于每个共享特定三元组的路径子集Pq(h,r,t)Pq(h,r,t),选择得分最高的k1k1条路径。
- 通过另一个规则限制不同共享三元组的数量,确保所选路径的多样性。
- 设置一个阈值γγ,过滤掉低相似度的路径,最终得到高相似度的路径集PrPr。
公式解释:
- 知识路径提取公式:
Pe={(e→r→o)∣o∈E,r∈R}∪{(e→r1→o1→r2→o2)∣o1,2∈E,r1,2∈R}Pe={(e→r→o)∣o∈E,r∈R}∪{(e→r1→o1→r2→o2)∣o1,2∈E,r1,2∈R}
- 样本编码公式:
hq=M(q),hp=M(p′)hq=M(q),hp=M(p′)
- 细粒度路径选择公式:
Pq′(h,r,t)=argmaxPq′(h,r,t)∑p∈Pq′(h,r,t)cos(hp,hq)Pq′(h,r,t)=Pq′(h,r,t)argmaxp∈Pq′(h,r,t)∑cos(hp,hq)
实验设计
- 数据集:实验使用了两个不同类型的数据集:强语义知识和弱语义知识。强语义知识任务使用MetaQA数据集,弱语义知识任务使用FACTKG数据集。
- 基线:实验包括与之前研究相同的基线,使用大型语言模型“gpt-3.5-turbo-0613”。
- 实现细节:使用预训练的DistilBert模型作为编码器M,优化器为AdamW,学习率为2×10−62×10−6。在FactKG数据集中,由于实体邻居子图过大,采用关系优先排序策略。
结果与分析
-
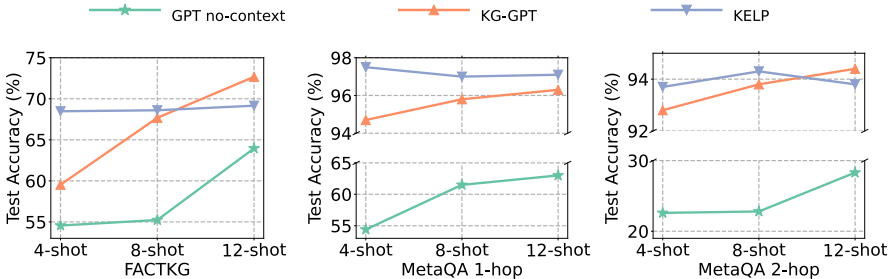
少样本学习设置:在4-shot、8-shot和12-shot配置下,KELP在强语义知识任务中的表现优于基于LLM的证据方法,特别是在12-shot场景中,KELP在1跳强语义知识任务中的检索性能超过了基于LLM的证据方法。
-
全监督模型比较:在少样本学习设置中,KELP的表现超过了一些全监督模型,接近这些模型中的最高准确率基准。
-
敏感性分析:KELP在不同少样本数量下的性能变化不大,特别是在样本数量有限的情况下,KELP表现出稳定性和优越性。
总体结论
这篇论文提出了KELP方法,通过灵活捕捉可能与输入文本无直接语义关系的潜在影响力知识,提高了LLMs生成输出的事实准确性。实验结果表明,KELP在强语义知识和弱语义知识任务中均优于现有的最先进基线方法,特别是在少样本学习场景中表现出显著的优越性。KELP的贡献在于:
- 批判性地研究了提示工程中缺乏灵活性和遗漏潜在影响力知识的挑战。
- 提出了KELP方法,通过训练路径-文本编码器捕捉潜在影响力知识,并通过两个覆盖规则确保知识提取的灵活性。
- 在事实验证和问答数据集上的广泛实验验证了KELP的有效性。
论文评价
优点与创新
- 灵活性:KELP通过潜在语义匹配为知识路径生成分数,实现了更细粒度的灵活知识提取。
- 间接语义关系:KELP不仅考虑与输入文本直接语义相关的知识路径,还能通过训练编码器考虑与输入文本具有间接语义关系的知识路径。
- 覆盖规则:引入了两个覆盖规则,确保知识路径选择的灵活性,从而获取最具代表性和多样性的路径。
- 关系优先排序:在知识路径集非常大的情况下,引入了“仅关系排序”策略,显著减少了需要编码的候选路径数量,提高了匹配效率。
- 实验验证:在事实验证和问答任务的数据集上进行了广泛的实验,证明了KELP的有效性。
- 多跳推理:KELP能够处理多跳推理,展示了其在复杂推理任务中的潜力。
不足与反思
- 数据收集的复杂性:为了训练一个能够捕捉有价值知识上下文的编码器,需要构建一个包含各种数据类型的训练集,这需要大量的手动测试和时间。
- 社会偏见:背景知识图和预训练大型语言模型中可能包含具有社会偏见的原始数据信息,尽管KELP方法仅基于输入文本与知识路径的关系进行选择,但仍需注意潜在的社会影响。
关键问题及回答
问题1:KELP方法在知识路径提取阶段是如何操作的?
在知识路径提取阶段,KELP方法的目标是从背景知识图谱(KG)中识别出对给定输入问题q有价值的知识路径。具体操作如下:
- 对于输入问题q中的每个实体e,提取其知识路径集PePe。这个集合包括所有从实体e出发的1跳和2跳路径。
- 1跳路径的形式为(e→r→o)(e→r→o),其中o是KG中的一个实体,r是关系。
- 2跳路径的形式为(e→r1→o1→r2→o2)(e→r1→o1→r2→o2),其中o1o1和o2o2是KG中的实体,r1r1和r2r2是关系。
这些提取的路径将作为后续样本编码阶段的候选知识路径。
问题2:KELP方法中的样本编码是如何进行的?其目的是什么?
样本编码是KELP方法中的一个关键步骤,旨在通过预训练的句子编码器M对输入问题q和提取的知识路径进行编码,以获得它们的距离(即路径对LLMs输出的潜在影响),从而确保捕捉到路径中有潜在影响的有用知识。具体操作如下:
- 对于每个知识路径,构建一个路径句子。如果路径只包含一个三元组(h,r,t)(h,r,t),则路径句子为"h r t";如果路径包含两个三元组,则路径句子为"h1 r1 t1, h2 r2 t2"。
- 使用编码器M对问题q和路径句子进行编码,得到它们的嵌入表示hqhq和hphp。
- 通过计算hqhq和hphp之间的余弦相似度,量化每条知识路径的有用性。相似度越高,表示该路径对LLM输出的潜在影响越大。
样本编码的目的是确保所选的路径能够有效地捕捉到对LLM生成输出有潜在影响的有用知识,从而提高输出的事实准确性。
问题3:KELP方法中的细粒度路径选择是如何实现的?其优势是什么?
细粒度路径选择是KELP方法中的最后一个阶段,旨在基于余弦相似度分数选择最适合输入问题q的路径作为上下文。具体操作如下:
- 聚合所有实体的路径集PqPq,得到总的路径集。
- 使用覆盖规则选择得分最高的路径子集Pq′(h,r,t)Pq′(h,r,t),公式如下:
Pq′(h,r,t)=argmaxPq′(h,r,t)∑p∈Pq′(h,r,t)cos(hp,hq)Pq′(h,r,t)=Pq′(h,r,t)argmaxp∈Pq′(h,r,t)∑cos(hp,hq)
- 根据另一个规则进一步限制不同共享三元组的数量,公式如下:
T′=argmaxT′∑(h,r,t)∈T′maxp∈Pq′(h,r,t)cos(hp,hq)T′=T′argmax(h,r,t)∈T′∑p∈Pq′(h,r,t)maxcos(hp,hq)
- 设置阈值γγ,过滤掉低相似度的路径,公式如下:
γ=min(h,r,t)∈T′maxp∈Pq′(h,r,t)cos(hp,hq)γ=(h,r,t)∈T′minp∈Pq′(h,r,t)maxcos(hp,hq)
- 最终得到高相似度的路径集PrPr,作为提示的上下文。
细粒度路径选择的优势在于其灵活性,能够通过调整覆盖规则和阈值,选择出多样且最具代表性的路径,从而确保所选路径能够有效地捕捉到对LLM生成输出有潜在影响的有用知识。这种方法不仅提高了LLM输出的事实准确性,还增强了模型的泛化能力。






