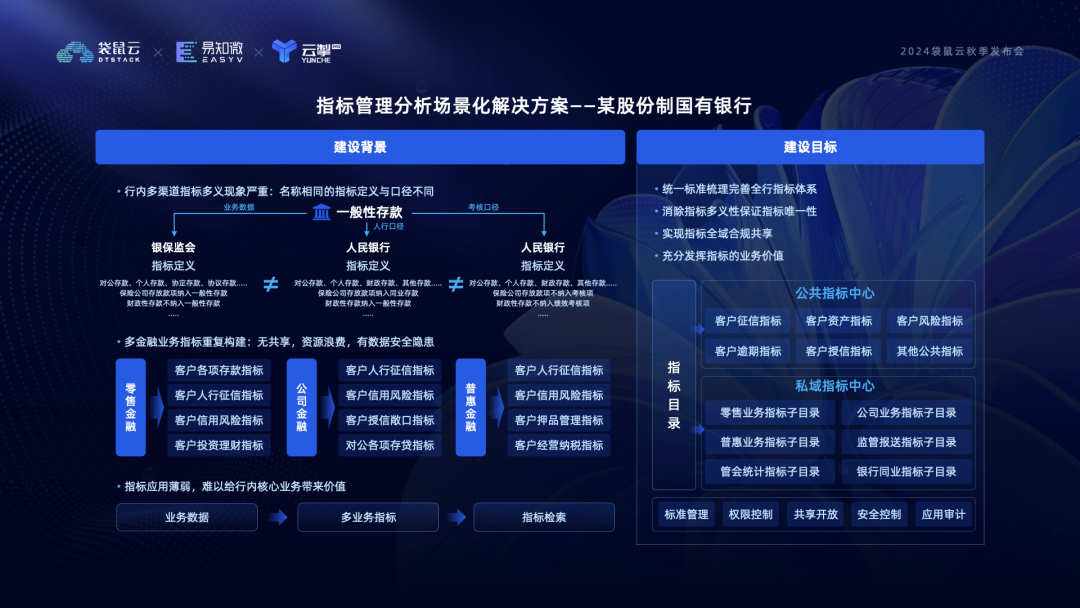
目录
一、时空复杂度
1.时间复杂度
2.空间复杂度
3.分析技巧
4.代码示例
二、递归
1.递归的介绍
2.递归如何实现
3.递归和循环的比较
4.代码示例
三、差分
1.差分的原理和特点
2.差分的实现
3.例题讲解
四、枚举
1.枚举算法介绍
2.解空间的类型
3. 循环枚举解空间
4.例题讲解
五、前缀和
1.前缀和原理和特点
2.实现前缀和
3.代码示例
六、离散化
1.离散化简介
2.离散化的实现方法
4.代码示例
一、时空复杂度
1.时间复杂度
(1)时间复杂度是衡量算法执行时间随输入规模增长的增长率。
(2)通过分析算法中基本操作的执行次数来确定时间复杂度。
(3)常见的时间复杂度包括:常数时间 0(1)、线性时间 O(n)、对数时间 O(logn)、平方时间O(n^2)等。
(4)在计算的时候我们关注的是复杂度的数量级,并不要求严格的表达式。
一般我们关注的是最坏时间复杂度,用O(f(n))表示,大多数时候我们仅需估算即可-般来说,评测机1秒大约可以跑2e8次运算,我们要尽可能地让我们的程序运算规模级控制在1e8以内。
2.空间复杂度
(1)空间复杂度是衡量算法执行过程中所需的存储空间随输入规模增长的增长率。
(2)通过分析算法中所使用的额外存储空间的大小来确定空间复杂度。
(3)常见的空间复杂度包括:常数空间 0(1)、线性空间 0(n)、对数空间 0(logn)、平方空间0(n^2)等。
一般我们关注的是最坏空间复杂度,用O(f(n))表示,大多数时候程序占用的空间一般可以据开的数组大小精确算出,但也存在需要估算的情况。题目一般不会卡空间,一般是卡时1举个例子,假如题目限制128MB,1int~32bit~4Bytes,128MB~32*2^20int~3e7int
3.分析技巧
1.理解基本操作:基本操作可以是算术运算(加法、乘法、位运算等)、比较操作、赋值操作等。
2.关注循环结构:循环是算法中常见的结构,它的执行次数对于时间复杂度的分析至关重要
3.递归算法:递归算法的时间和空间复杂度分析相对复杂。需要确定递归的深度以及每个归调用的时间和空间开销。
4.最坏情况分析:对于时间复杂度的分析,通常考虑最坏情况下的执行时间。要考虑输入数据使得算法执行时间达到最大值的情况。
5.善用结论:某些常见算法的时间和空间复杂度已经被广泛研究和证明。可以利用这些已知结果来分析算法的复杂度。
4.代码示例
时间复杂度:O(n)该算法使用迭代的方式计算斐波那契数列的第n个数,循环遍历n次,因此时间复杂度与n成正比。
//斐波那契数列,又称黄金分割数列,指的是这样一个数列:0、1、1、2、3、5、8、13、21、34、……在数学上,斐波纳契数列以如下被以递归的方法定义:F(0)=0,F(1)=1,F(n)=F(n-1)+F(n-2)(n≥2,n∈N*)
空间复杂度:O(1)算法只使用了常数级别的额外空间来存储变量,不随输入规模变化。
#include <iostream>
usinp namespace std;
int fibonacci(int n)
{
if(n←1)
return n;
int prev1 = 0:
int prev2 = 1;
int fib = 0;
for (int i =2;i <= n ;i++)
{
fib = prev1 = prev2;
prev1 = prev2;
prev2 = fib;
}
return fib;
}
int main()
{
int n;
cout << "Enter the position: ";
cin >> n;
int result = fibonacci(n);
cout << "Fibcnacci number at position " << n << " : "<< result <<endl;
return 0;
}
二、递归
1.递归的介绍
概念:递归是指函数直接或间接调用自身的过程。
解释递归的两个关键要素:
基本情况(递归终止条件):递归函数中的一个条件,当满足该条件时,递归终止,避免无限递归。可以理解为直接解决极小规模问题的方法。
递归表达式(递归调用):递归函数中的语句,用于解决规模更小的子问题,再将子问题的答案合井成为当前问题的答案。
2.递归如何实现
递归函数的基本结构如下:
返回类型 函数名(参数列表)
{
//基本情况(递归终止条件)
if(满足终止条件)
{
//返回终止条件下的结果
}
//递归表达式(递归调用)
else
{
//将问题分解为规模更小的子问题
//使用递归调用解决子问题
// 返回子问题的结果
}
}
实现过程:
1.将大问题分解为规模更小的子问题。
2.使用递归调用解决每个子问题。
3.通过递归终止条件来结束递归。
设计时需注意的细节:
1.确保递归一定能到递归出口,避免无限递归,这可能导致TLE(超时)、MLE(超内存)或RE(运行错误)。
2.考虑边界条件,有时候递归出口不止一个
3.避免不必要的重复计算,尽可能优化递归函数的性能(例如使用记忆化)。
3.递归和循环的比较
递归的特点:
1.直观、简洁,易于理解和实现。
2.适用于问题的规模可以通过递归调用不断减小的情况。
3.可以处理复杂的数据结构和算法,如树和图的遍历。
4.存在栈溢出风险(栈空间一般只有8MB,所以递归层数不宜过深,一般不超过1e6层)。
循环的特点:
1.直接控制流程,效率较高。
2.适用于问题的规模没有明显的缩减,或者需要特定的选代次数。
3.适合处理大部分的动态规划问题。
在部分情况下,递归和循环可以相互转化。
4.代码示例
斐波那契数列
已知F(1)=F(2)= 1;
n>3时F(n)=F(n-1)+F(n-2)
输入n,求F(n),n<=100000,结果对1e9+7取模。
#include<bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 1e5 + 9;
const ll p= 1e9 +7;
ll fib(int n)
{
if( n <=2 )
return 1;
return (fib(n - 1) + fib(n - 2)) % p;
}
int main()
{
int n;
cin >> n;
for(int i = 1 ;i <= n; ++ i)
cout << fib(i) << '\n';
return 0;
}
三、差分
1.差分的原理和特点
对于一个数组a[ ],差分数组diff[]的定义是:
diffi]=a[i]-a[i-1]
对差分数组做前缀和可以还原为原数组:
diff[1]=a[1]
diff[2] = a[2]- a[1]
diff[3]= a[3]-a[2]
diff[n]=a[n]-a|n-1]
diff[1]+ diff[2]+ diff[3]+...+diff[i]
= a[1] +(a[2]-a [1])+(a[3]- α[2])+...+(a[i]-a[i-1])
= a[i]
利用差分数组可以实现快速的区间修改,下面是将区间[,r]都加上x的方法:
diff[l] += x;
diff[r +1] -= x;
在修改完成后,需要做前缀和恢复为原数组,所以上面这段代码的含义是:
diff[l] += x表示将区间[l,n]都加上x,
但是[r+1,n]我们并不想加x,所以再将[r+1,n]减去x即可。
但是注意,差分数组不能实现“边修改边查询(区间和)”,只能实现“多次修改完次查询”。如果要实现“边修改边查询”需要使用树状数组、线段树等数据结构。
2.差分的实现
直接用循环O(n)实现即可,注意这里建议使得a[0]=0,下标从1开始
for(int i = 1;i <= n; ++ i)
diff[a[i]=a[i]-a[i- 1];
将区间[l,r]都加上x:
diff[l] += x;
diff[r + 1]-= x;
3.例题讲解
小明拥有 N 个彩灯,第i个彩灯的初始亮度为 ai,
小明将进行 Q 次操作,每次操作可选择一段区间,并使区间内彩灯的亮度 + x(x 可能为负数)。
求 Q 次操作后每个彩灯的亮度(若彩灯亮度为负数则输出 0)。
利用差分数组对数组a进行区间修改即可
注意输出时亮度如果为负数则输出0,需要开longlong。
#include<bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 1e6 + 3;
ll a[N],d[N];
void solve()
{
int n,m;
cin >> n >>m;
for(int i = 1;i <= n;++i)
cin >> a[i];
for(int i = 1;i <= n;++i)
d[i] = a[i] - a[i-1];
while(n --)
{
intl, r, v,;
cin >> l >>r >>v;
d[l] +=v,d[r + 1] -= v;
}
//前缀和还原
for(int i = 1;i <= n;++i)
a[i] = a[i-1] + d[i];
for(int i = 1;i <= n;++i)
cout << max(011, a[i]) << '\n'(i == n);
}
int main()
{
solve();
return 0;
}
四、枚举
1.枚举算法介绍
枚举算法是一种基本的算法思想,它通过穷举所有可能的情况来解决问题。它的基本思想是将问题的解空间中的每个可能的解都枚举出来,并进行验证和比较,找到满足问题条件的最优解或者所有解。
枚举算法适用于问题规模较小、解空间可穷举的情况。它的优点是简单直观,不需要复杂的数学推导,易于实现。但是,由于需要穷举所有可能的情况,对于问题规模较大的情况,枚举算法的时间复杂度可能会非常高,效率较低。
2.解空间的类型
一个问题的解空间是它的所有可能的解构成的集合。
解空间可以是一个范围内的所有数字(或二元组、字符串等数据),或者满足某个条件的所
有数字。
当然也可以是解空间树,一般可分为子集树和排列树,针对解空间树,需要使用回溯法进行
枚举。
我们目前仅使用循环去暴力枚举解空间,具体的解空间类型需要根据题目来理解构造。
3. 循环枚举解空间
1.首先确定解空间的维度,即问题中需要枚举的变量个数。
例如当题目要求的是满足条件的数字时,我们可以循环枚举某个范围内的数字。
如果要求的是满足条件的二元组,我们可以用双重循环分别枚举第一个和第二个变量,从而构造出一个二元组。
2.对于每个变量,确定其可能的取值范围。这些范围可以根据问题的性质和约束条件来确定这一步往往是时间复杂度优化的关键。
3.在循环体内,针对每个可能解进行处理。可以进行问题的验证、计算、输出等操作。
4.例题讲解
题目描述
小明对数位中含有 2、0、1、9的数字很感兴趣(不包括前导 0),在1到 40中这样的数包括1、2、9、10至32、39 和 40,共 28 个,他们的和是 574.
请问,在1到n中,所有这样的数的和是多少?
枚举所有数字(解空间)用一个函数判断某个数字是否是特别的数,将满足条件的数字求和即可。
#include<bits/stdc++.h>
using namespace std;
bool f(int x)
{
while(x)
{
int y = x % 10;
if(y == 2 || y == 0 || y == 9)
return turn;
x /= 10;
}
}
int main()
{
int n;
cin >> n;
int ans = 0;
for(int i = 1;i <= n;++i)
{
if (f (i))
ans += i;
}
cout << ans<< '\n';
return 0;
}
五、前缀和
1.前缀和原理和特点
prefix表示前缀和,前缀和由一个用户输入的数组生成。
对于一个数组a[](下标从1开始),我们定义一个前缀和数组prefix,满足:
prefix[i] => a[j]
prefix有一个重要的特性,可以用于快速生成prefix:
prefix[i] = a|j] + a[i] = prefix |i-1] + a[i]
prefix可以O(1)的求数组a几]的一段区间的和:
sum(l,r) = prefix [r] - prefix [l-1]
但是注意,prefix是一种预处理算法,只适用于a数组为静态数组的情况,即a数组中的元素在区间和查询过程中不会进行修改。
如果需要实现“先区间修改,再区间查询”可以使用差分数组,如果需要“一边修改,一边查询”需要使用树状数组或线段树等数据结构。
2.实现前缀和
利用前面讲过的特性:
prefix[i]= prefix[i - 1] + a[i]
我们的数组下标均从1开始,a[0]=0,从前往后循环计算即可。
for(int i = 1;i <= n; ++ i)
prefix[i]= prefix[i - 1] + a[i];
求区间和:
sum(L, R) = prefix[R]-prefix[L-1]
3.代码示例
问题描述
平衡串指的是一个字符串,其中包含两种不同字符,并且这两种字为的数量相
等。
例如,ababab和aababb都是平衡串,因为每种字符各有三个,而abaab和aaaab 都不是平衡串,因为它们的字符数量不相等。
小郑拿到一个只包含L、Q的字符串,他的任务就是找到最长平衡串,且满足平衡串的要求,即保证子串中L、Q的数量相等。
#include <bits/stdc++.h>
using namespace std;
const int N = 1010;
char s[N];
int prefix[N];
int main()
{
cin >> s + 1;
int n = strlen(s + 1);
for(int i = 1;i <= n;++i)
prefix[i] = prefix[i - 1] + (s[i] == 'L' ? 1: -1);
int ans = 0;
for(int i = 1;i <= n;++i)
for(int j = i;j <= n;++j)
if(prefix[j] = prefix[i - 1] == 0)
ans = max(ans ,j - i + 1);
cout << ans<< '\n';
return 0;
}
}
六、离散化
1.离散化简介
把无限空间中有限的个体映射到有限的空间中去,以此提高算法的时空效率。
离散化是一种将数组的值域压缩,从而更加关注元素的大小关系的算法。当原数组中的数字很大、负数、小数时(大多数情况下是数字很大),难以将“元素值”表示为“数组下标”,一些依靠下标实现的算法和数据结构无法实现时,我们就可以考虑将其离散化。
例如原数组的范围是[1,1e9],而数组大小仅为1e5,那么说明元素值的“种类数”最多也就1e5种,从而可以利用一个数组(即离散化数组)来表示某个元素值的排名(即第几小)现值域的压缩,将原数组的元素值作为下标来处理。
离散化数组要求内部是有序(一般是去重的,当然也存在不去重的方法,但是比较少见)的,中可以直接通过离散化下标得到值,当然也可以通过值得到离散化下标(通过二分实现)。下面是一个离散化的例子:
| a(原数组) (离散化数组) index(下标) | 不使用 2 0 | 3 3 1 | 1000 1000 2 | 2 9999 3 | 9999 4 | 2 5 |
离散化不会单独考察,一般会结合其他算法或数据结构一起考察,例如树状数组、线段树、二维平面的计算几何等等。
2.离散化的实现方法
离散化的实现方法比较多样,但原理相同,这里采用vector来进行离散化。
#include <bits/stdc++.h>
using namespace std;
vector<int> L;//离散化数组
//返回x在L中的下标
int getidx(int x)
{
return lower_ bound( L.begin(),L.end(),x)-L.begin();
}
const int N=1e5 + 9;
int a[n];
int main()
{
int n;
cin >> n;
for(int i = 1;i <= n; ++ i)
cin >> a[i];
//将元素存入L数组中
for(int i = 1;i <= n; ++ i)
L.push back(a[i]);
//排序去重
L.erase(unique(L.begin(),L.end()),L.end());
return 0;
}
4.代码示例
#include <bits/stdc++.h>
using namespace std;
const int N = le5 + 9;
vector<int> L;
int getidx(int x)
{
return lower_bound(L.begin(),L.end(),x) - L.begin
}
int main()
int n;
cin >> n;
for(int i = 1;i <= n; ++ i)
cin >> a[i];
for(int i = 1;i <= n; ++ i)
L.push_ back(a[i]);
sort(L.begin(),L.end());
L.erase(unique(L.begin(),L.end()),L.end());
cout<<“离散化数组为:”;
for(const auto &i : L)
cout << i < ' ' ;
cout << '\n';
int val;
cin >> val;
cout << getidx(val)<< '\n';
return 0;
}