本文的内容是介绍网络爬虫中的数据存储方式。大家都知道爬虫的最重要功能就是从网络中将数据提取出来。现在问题来了,那么提取出来的数据该何去何从,如果仅仅只是保存在内存当中,当程序结束后岂不是所有的内容都消失了?因此需要将数据保存在计算机本地硬盘中。常见的存储方式如下:
- 文本存储
- json格式存储
- 表格存储
- MySQL存储
- mongoDB存储
- redis存储
以上存储方式均会在本次文章中为大家进行详细的讲解,后面大家如果往爬虫方向就业的话也是必须要掌握的知识点。
文本文档存储
文件打开模式
python中所有open()打开一个文件,文件的打开有很多模式:
- r:以只读方式打开文件,文件的指针将会放在文件的开头,这是默认模式。
- rb:以二进制只读方式打开一个文件,文件指针将会放在文件的开头。
- r+:以读写方式打开一个文件,文件指针将会放在文件的开头。
- rb+: 以二进制读写方式打开一个文件,文件指针将会放在文件的开头。
- w:以写入方式打开一个文件。如果该文件已存在,则将其瞿盖;如果该文件不存在,则创建新文件。
- wb:以二进制写入方式打开一个文件。如果该文件已存在,则将其覆盖;如果该文件不存在,则创建新文件。
- w+:以读写方式打开一个文件。如果该文件已存在,则将其覆盖;如果该文件不存在,则创建新文件。
- wb+:以二进制读写格式打开一个文件。如果该文件已存在,则将其覆盖;如果该文件不存在, 则创建新文件。
- a:以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后;如果该文件不存在, 则创建新文件来写入。
- ab:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。也就是说,新的内容将会被写入到己有内容之后;如果该文件不存在,则创建新文件来写入。
- a+:以读写方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式;如果眩文件不存在,则创建新文件来读写。
- ab+:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾;如果该文件不存在,则创建新文件用于读写。
实战知乎热点问题
目标网址:
import requests
from bs4 import BeautifulSoupurl = 'https://www.zhihu.com/explore'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36','Referer': 'https://www.zhihu.com/'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
title_list = soup.select('div .css-1g4zjtl')for div in title_list:title = div.select('a')[0].get_text()print(title)
运行结果如下:
如何评价京东请杨笠宣传?
多家品牌官微撤掉易建联相关内容,东莞政协回应「具体情况需等通报」,此次风波会对其商业价值造成哪些影响?
韩国有胆子对朝鲜首都发起第二次传单攻势吗?
楼市政策「组合拳」来了,住建部出台五项政策支持货币化安置房,允许地方发行专项债,将如何影响楼市?
如何评价电影《三体》将由张艺谋执导?
美国担心中国月球探测器「玉兔」轧了阿姆斯特朗的脚印,会出现这种情况吗?如何保护人类在月球上的历史遗迹?
梅西美洲杯决赛伤退,替补席捂脸持续痛哭 3 分钟,他本届比赛表现如何?如何评价他现在的实力?
如何评价外网玩家对绝区零的这句话?
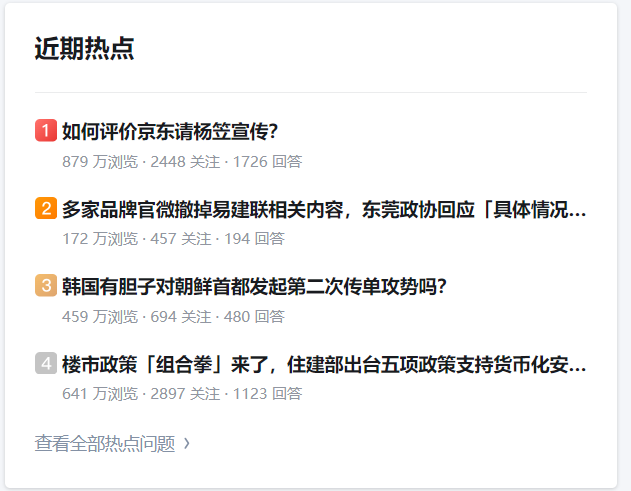
打开目标网址就会发现,抓取的内容与图片的内容完全一致。但是你使用我这边的代码的时候就不一定能说抓取的内容是一样了,因为这个是小时榜。
在上面的代码中只是将热搜数据打印了出来,没有保存到本地,我们该怎么样修改代码呢?
当然,非常的简答,使用open()函数即可实现。
代码修改如下:
for div in title_list:title = div.select('a')[0].get_text()with open('hot.txt', 'a', encoding='utf-8') as f:print(title)f.write(title + '\n')
如上代码所示,仅仅需要将循环输出标题的代码进行修改即可。注意:将数据存储到文本文档的时候,写入的模式必须是a,意思是不停的往后添加内容。
json数据存储
JSON,全称为 JavaScript Object Notation, 也就是 JavaScript 对象标记,它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式。本节中,我们就来了解如何利用 Python 保存数据到 JSON 文件。
对象和数组
在 JavaScript 语言中,一切都是对象。因此,任何支持的类型都可以通过 JSON 来表示,例如字符串、数字、对象、数组等,但是对象和数组是比较特殊且常用的两种类型,下面简要介绍一下它们。
- 对象:它在 JavaScript 中是使用花括号 {} 包裹起来的内容,数据结构为 {key1:value1, key2:value2,…} 的键值对结构。在面向对象的语言中,key 为对象的属性,value 为对应的值。键名可以使用整数和字符串来表示。值的类型可以是任意类型。
- 数组:数组在 JavaScript 中是方括号 [] 包裹起来的内容,数据结构为 [“java”, “javascript”, “vb”, …] 的索引结构。在JavaScript 中,数组是一种比较特殊的数据类型,它也可以像对象那样使用键值对,但还是索引用得多。同样,值的类型可以是任意类型。
所以,一个 JSON 对象可以写为如下形式:
[{
"name": "Bob",
"gender": "male",
"birthday": "1992-10-18"
}, {
"name": "Selina",
"gender": "female",
"birthday": "1995-10-18"
}]
由中括号包围的就相当于列表类型,列表中的每个元素可以是任意类型,这个示例中它是字典类型,由大括号包围。
json模块方法
| 方法 | 作用 |
|---|---|
| json.dumps() | 把python对象转换成json对象的一个过程,生成的是字符串。 |
| json.dump() | 用于将dict类型的数据转成str,并写入到json文件中 |
| json.loads() | 将json字符串解码成python对象 |
| json.load() | 用于从json文件中读取数据。 |
实战4399小游戏
目标网址:https://www.4399.com/flash/
目标:抓取该网址下所有的游戏标题及其链接,并以json的格式进行存储。
import requests
from lxml import etreeurl = 'https://www.4399.com/flash/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36','Referer': 'https://www.zhihu.com/'
}
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
html_obj = etree.HTML(response.text)
li_list = html_obj.xpath('//ul[@class="n-game cf"]/li')
# print(li_list)
for li in li_list:link = li.xpath('./a/@href')[0]title = li.xpath('./a/b/text()')[0]print(link, title)
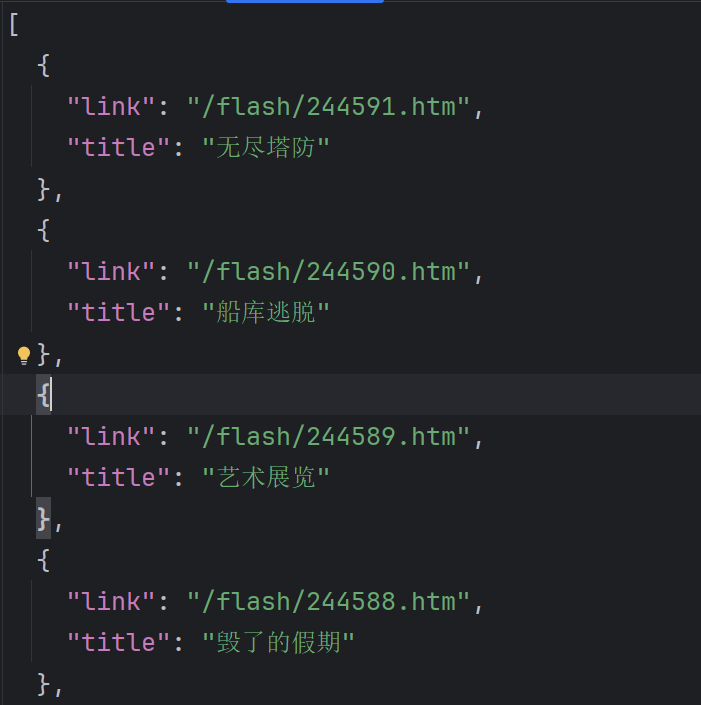
通过这段代码提取出了,网页游戏中的标题和链接,并把它打印出来。那么该如何保存呢?往往我们都会将它保存为json数组。
代码修改如下所示:
data = []
for li in li_list:item = {}item['link'] = li.xpath('./a/@href')[0]item['title'] = li.xpath('./a/b/text()')[0]data.append(item)with open('4399.json', 'w', encoding='utf-8') as f:f.write(json.dumps(data, ensure_ascii=False, indent=2))print('存储完成!')
ensure_ascii=False:代表的含义是不对中文进行编码。
indent:美化json数据,每条数据两行显示。
总结
本篇文章是数据存储的上半部分,讲述的内容是如何将数据存储进文本文档和以json格式存储。内容不多,也比较简单,适合初学者学习过程中存储数据。
跟着我一起学习爬虫。
没有一件事情是可以一蹴而就,路漫漫其修远兮,吾将上下而求索!