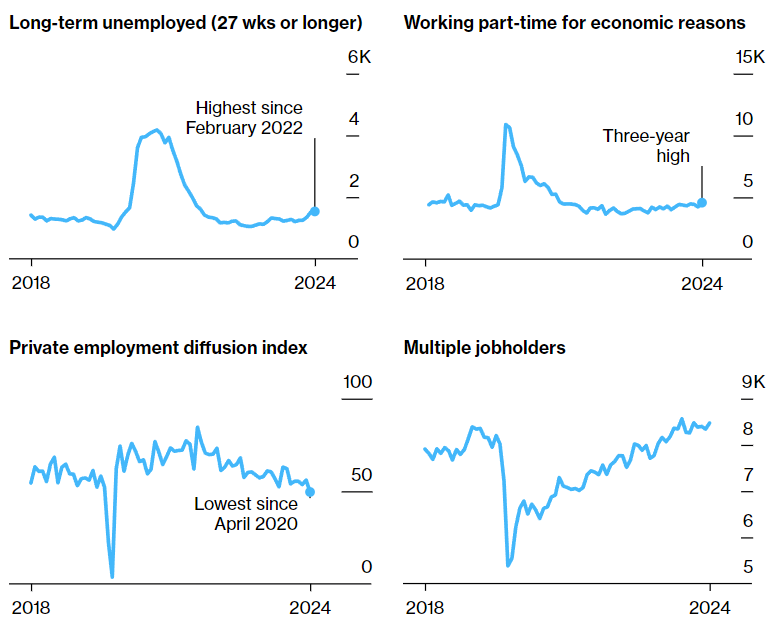
1. 什么是爬虫?
爬虫(Web Scraping)是一种从网站自动提取数据的技术。简单来说,它就像是一个自动化的“浏览器”,能够按照设定的规则,访问网页并提取其中的关键信息。对于我们前端开发者来说,爬虫可以帮助我们抓取一些数据进行可视化或前端展示,非常实用。
2. 为什么选择 Python?
Python 作为一种高效、简洁的编程语言,尤其在数据处理和爬虫方面拥有大量强大的第三方库。使用 Python 编写爬虫非常方便,因为有现成的工具让我们不需要从零开始写所有功能,比如 requests 和 BeautifulSoup 等库。
3. 爬虫小案例
python_8">3.1 安装python
brew install python
运行完成,使用python --version检验安装是否成功。我这里安装的是python2
3.2 安装依赖
首先,确保你已经安装了 Python 和 pip,然后通过以下命令安装我们需要的库:
pip install requests
pip install beautifulsoup4
-
requests是一个非常流行的Python第三方库,用于简化HTTP请求。它允许你发送HTTP/1.1请求极其简单,而无需底层的socket库或urllib库。requests库使得发起请求、处理响应变得非常容易,并且支持多种类型的HTTP请求(GET,POST,PUT,DELETE等)。 -
BeautifulSoup4(通常简称BeautifulSoup)是一个用于解析HTML和XML文档的Python库。它可以帮助开发者从网页中提取所需的数据,常用于Web爬虫项目、数据挖掘以及其他需要解析HTML或XML文档的场景。
3.3 requests请求设置
比如爬我在csdn的主页信息,将访问量,原创,排名,粉丝,铁粉这些数据获取出来。

- 设置访问的URL
python">url = 'https://blog.csdn.net/qq_36012563'
- 设置请求头
有时候,网站会检测请求是否来自浏览器。我们可以通过在requests.get请求中添加请求头来伪装爬虫为浏览器,所以拿取浏览器的请求头来设置。

将user-agent复制出来,设置其requests请求头
python">headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'}
- 解析网页
python">strhtml = requests.get(url, headers=headers) // 发起GET请求,获取网页数据soup = BeautifulSoup(strhtml.text, 'html.parser') // 创建BeautifulSoup对象- 查找元素

python"># 查找具有特定类名的<div>标签
soup.find_all('div', class_='user-profile-statistics-num')
// or
soup.select('div.user-profile-statistics-num')
- 将数据导出文件
在写入文本文件时,确保每行数据后面加上换行符\n,以便每行数据独立。
python">with open('output.txt', 'w') as file:for item in info:file.write(item.get_text() + '\n')
3.4 完整代码
python">import requests
from bs4 import BeautifulSoupurl = 'https://blog.csdn.net/qq_36012563'headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'}
strhtml = requests.get(url, headers=headers)soup = BeautifulSoup(strhtml.text, 'html.parser')info = soup.select('div.user-profile-statistics-num')with open('output.txt', 'w') as file:for item in info:file.write(item.get_text() + '\n')python2 index.py运行该文件,获取到网页数据

4. 总结
Python 爬虫是一个非常强大的工具,能帮助我们自动化地从网页中提取数据。作为前端开发者,掌握一点爬虫技术,不仅能帮助我们快速获取前端展示所需的数据,还能为项目中的 API 数据源提供备选方案。不过,在使用爬虫时,一定要遵守目标网站的使用条款和隐私政策,避免滥用。