概述
论文地址:https://arxiv.org/abs/2409.10516
本文的研究背景主要是为了解决 "具有长语境的大型语言模型(LLM)"问题。基于变换器的 LLM 被广泛应用于各个领域,但在处理长上下文时,其计算成本非常高。特别是计算 "注意力 "时,较长上下文会增加处理时间和内存使用量,这是一个瓶颈。为了解决这个问题,人们开发了许多技术,但没有一种技术能完全解决这个问题。
我们的方法优于现有的注意力优化技术,因为它可以在保持几乎相同的准确度水平的同时,对长上下文进行非常高效的推理。特别是,它允许大型模型(8B 参数模型)在规格相对较低的 GPU 上高效运行。
简而言之,RetrievalAttention 是一种能显著提高长语境 LLM 推理的记忆和时间效率的技术,是向实际应用迈出的重要一步。
研究背景
大规模语言模型能够处理超长文本数据,因此在各种自然语言处理任务中表现出色。例如,它们可以阅读大量文本,并根据内容生成回复或摘要。然而,这些模型的核心 "注意力机制 "却面临着巨大的挑战。
注意力机制是一种确定输入文本中哪些部分重要并据此预测下一个单词的技术。然而,注意力的计算复杂度是通过比较两组向量("查询 "向量和 "键值 "向量)来完成的,因此随着文本变长,计算复杂度也会急剧增加。这就导致推理速度缓慢,内存占用巨大。一个主要瓶颈是 GPU 内存很快就会达到极限,尤其是在上下文非常长的情况下。
传统的解决方案是使用一种称为 "KV 缓存 "的技术。这种技术可以保留和重复使用计算所需的先前 "键 "和 "值 "状态,从而消除不必要的计算。不过,即使是这种方法,在处理长上下文时也会消耗大量内存。例如,在单个 GPU 上处理大量令牌可能需要 500 GB 以上的内存。这使得它很难在现实系统中使用,因此需要一种更高效的方法。
因此,本文重点关注注意力机制中的 "动态稀疏性 "特征。实际上,并不是所有的标记都对预测下一个词重要,只有某些标记子集才起重要作用。换句话说,我们的想法是,没有必要将所有标记符都纳入计算,如果我们只关注重要的标记符,就可以大大降低计算成本。
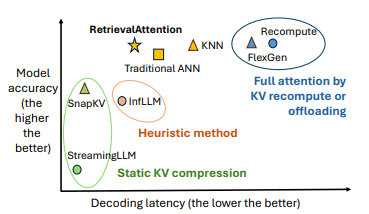
基于这一背景,我们提出了一种新方法–RetrievalAttention,以实现高效的注意力计算。
建议方法
在 ransformer 模型中,注意力机制决定了输入文本的哪些部分是重要的,并据此预测下一个标记。然而,上下文越长,计算所有标记的注意力就越耗费计算量。
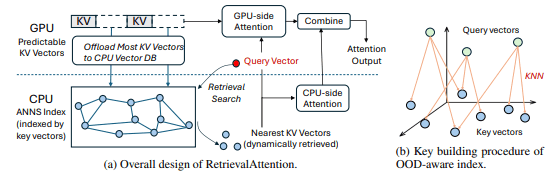
RetrievalAttention 的一个主要特点是它能解决查询向量和键值向量之间的分布差异(OOD 问题)。在普通的近似最优搜索中,假设查询和键值属于相同的分布,但在注意力计算中,查询向量和键值向量往往具有不同的分布,从而导致性能低下。为了解决这个问题,RetrievalAttention 采用了一种新的搜索算法,这种算法能适应注意力的特定分布。这种方法使得即使只扫描查询数据的 1-3%,也能获得高度准确的注意力结果。
RetrievalAttention 还能充分利用 GPU 和 CPU 的内存。具体来说,重要的 "键值 "向量保存在 GPU 上,其余数据则卸载到 CPU 上,从而在保持计算效率的同时减少了 GPU 内存消耗。
RetrievalAttention "使用两大理念来简化注意力计算
利用动态稀疏性
在注意力计算中,并非所有标记都同等重要,事实上,只有部分标记在预测下一个标记时起着重要作用。这就是所谓的 “动态稀疏性”。检索注意力 "就是利用这一特性,只关注重要的标记,而忽略其他标记。
通过向量搜索进行优化
接下来,一种名为 “近似最优搜索”(ANNS)的技术被用来近似地选择最重要的标记,而不是针对所有标记。这种技术能从海量数据中高速搜索出重要数据,与普通注意力计算相比,大大减少了计算量。
试验
本文提出的 RetrievalAttention 实验测试了该方法在提高具有长语境的大规模语言模型(LLM)的推理效率方面的有效性。实验使用了多个大规模模型和基准,对所提出方法的性能进行了详细评估。
首先,在实验环境中使用英伟达™(NVIDIA®)RTX 4090 GPU(24 GB 内存)对 Llama-3-8B 和 Yi-6B 等几个 LLM 进行了测试。每个模型都能处理多达 128,000 个标记的长上下文。实验的目的是了解 RetrievalAttention 与其他方法相比能快多少,同时保持推理的准确性。
实验从准确性和速度两个方面对所提出的方法进行了评估。首先,在准确性方面,RetrievalAttention 的表现几乎与 FullAttention 相当。这意味着,通过有效地只提取重要的标记,计算成本得以降低,而不会影响模型的推理结果。基准任务 ∞-Bench 的结果证实了这一结果。

另一方面,推理速度也有显著提高。特别是在处理 128,000 个标记的长语境时,发现 RetrievalAttention 的推理速度比传统的 FullAttention 快了近五倍。这种速度提升是通过大幅减少对不必要标记的访问实现的:在 "大海捞针 "任务中,RetrievalAttention 从海量数据中提取特定信息的效率尤为突出,RetrievalAttention 的卓越检索性能得到了展示。

RetrievalAttention 在 GPU 内存使用方面也很出色。通常情况下,处理长上下文需要大量内存,但所提出的方法只需 16 GB GPU 内存即可处理 128,000 个标记,从而在保持较低硬件成本的同时实现了高效推理。
因此,RetrievalAttention 是一种既能显著提高推理速度和记忆效率,又能保持准确性的方法,并已显示出实用性能,尤其是在具有较长语境的任务中。
总结
本文的结论是,所提出的 "RetrievalAttention "方法在简化处理长语境的大规模语言模型(LLM)推理方面非常有效。由于涉及大量的标记,正常的注意力计算往往需要大量的时间和内存。特别是,上下文越长,注意力计算的负荷就会呈指数增长。然而,RetrievalAttention 通过关注注意力中的 “动态稀疏性”,只对必要部分进行有效处理,从而解决了这一问题。
与传统方法相比,该方法能动态选择重要的标记,并以更少的计算量和内存使用量达到相当的准确率。实验结果还表明,使用 RetrievalAttention 可以显著提高推理速度,尤其是在长上下文任务中,最多可提高五倍。
此外,即使 GPU 内存有限,RetrievalAttention 也能高效处理长上下文,从而减少内存使用量。这一功能使得以前需要非常昂贵的硬件才能完成的任务,现在也能在更经济实惠的环境中完成了。
总之,在处理长语境时,RetrievalAttention 是一种既能保持准确性又能显著降低推理成本的强大技术,是 LLM 未来发展的一项非常重要的技术。