python_pandas_0">python数据分析 pandas库-数据读取和保存
一、数据文件
在数据分析中,数据的读取是非常重要的一步。Pandas 提供了丰富的接口来读取各种格式的数据文件,例如 CSV、Excel、JSON、SQL 数据库等。接下来我们将详细说明如何使用 Pandas 读取不同格式的数据文件。
1、CSV文件的读取和保存
pandasread_csv_10">1) 读取 CSV 文件(pandas.read_csv())
CSV(Comma-Separated Values)是最常见的文本数据格式之一,通常用于保存表格数据。Pandas 提供了 pd.read_csv() 函数来读取 CSV 文件。
python">df = pd.read_csv('data.csv')

参数:
filepath_or_buffer:它是read_csv()的第一个参数,也是最重要的参数。它指定了要读取的 CSV 文件的路径或 URL。sep:指定分隔符,默认是逗号,,可以自定义为其他符号,如分号;。- 例如:
python">df = pd.read_csv('data.csv',sep=';')
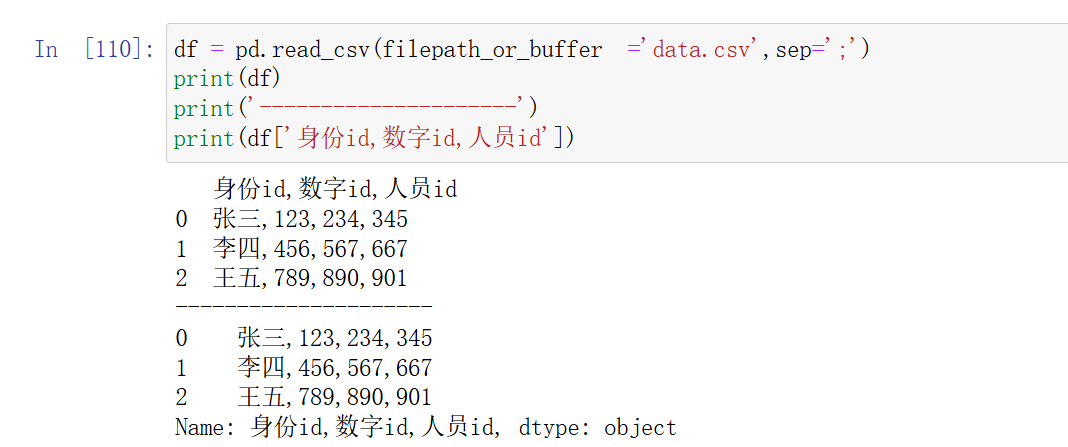
分隔符错了,他们就会变成一列。
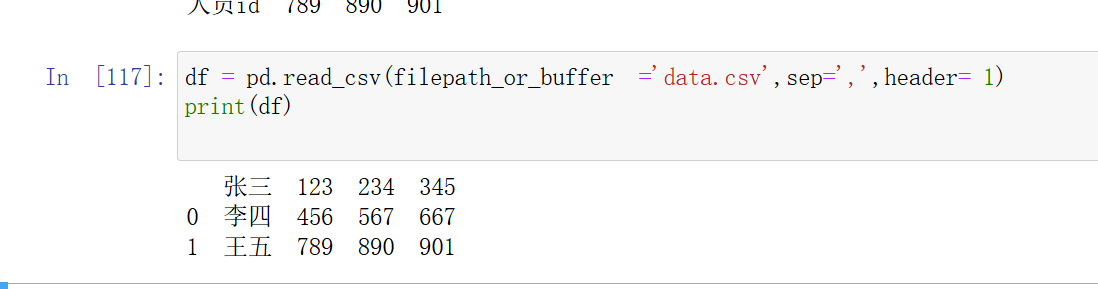
header:指定哪一行作为列名,默认是第 0 行。
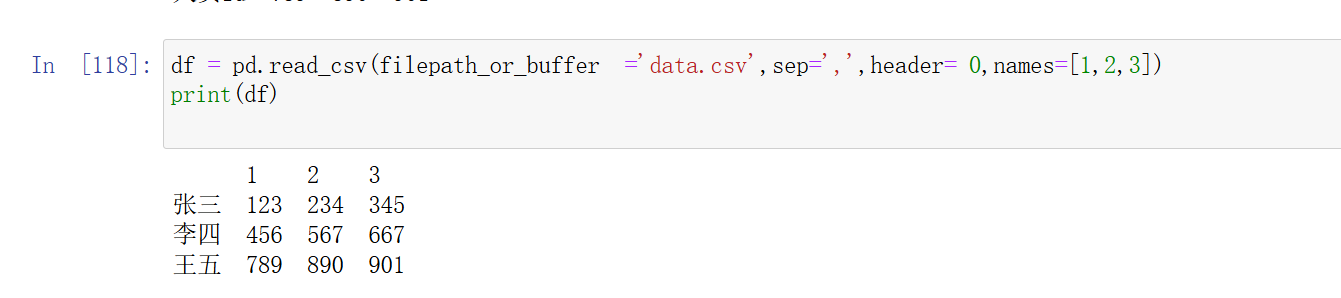
names:如果文件没有列名,可以通过names指定列名列表。
index_col:指定哪一列作为索引列,默认不使用,但我参数填3时,第四列就成为了索引,原索引向前移了一位。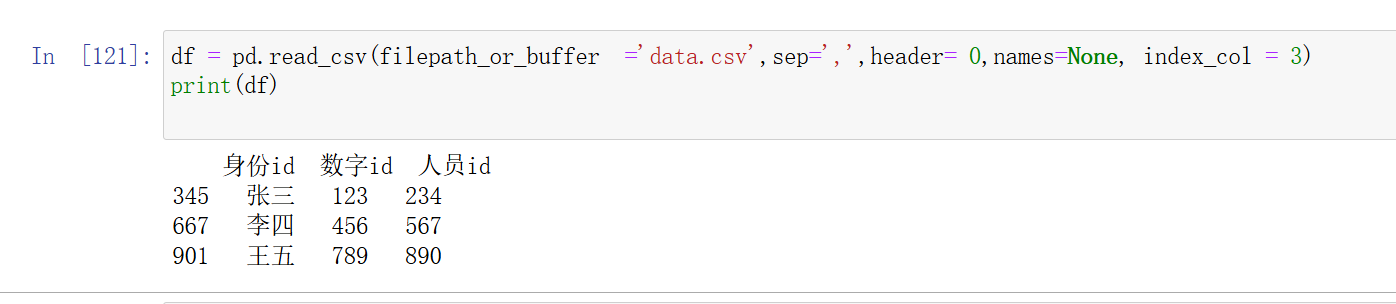
usecols:指定要读取的列,可以通过列名或列号来选择。它是参数可以是列名,也可以是列序号,也就是设置它以后,只读取你想要读取的列,其他列就不读取,节省了内存空间。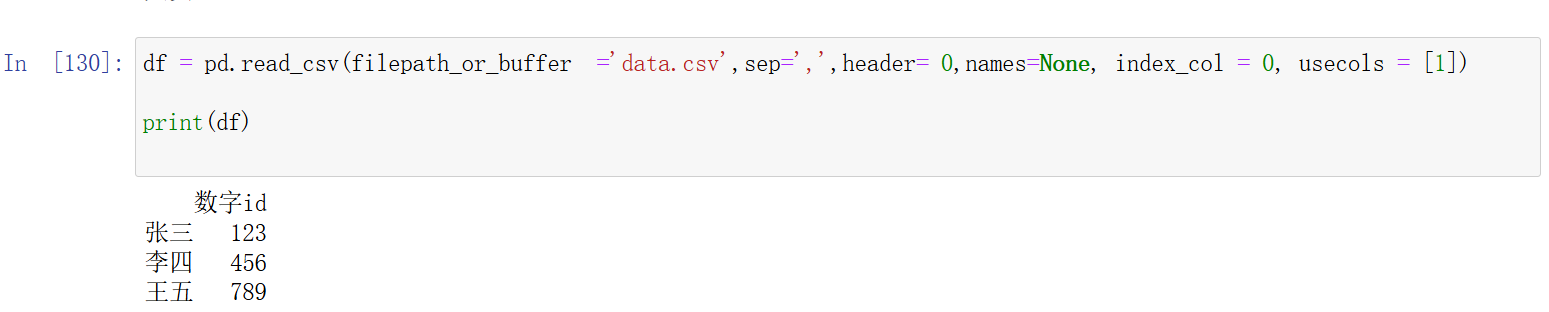
2)保存CSV文件(to_csv())
参数
path_or_buf:
-
说明: 这是文件保存路径或对象。如果是
None,则返回 CSV 数据作为字符串,而不是写入文件。 -
类型:
str或Nonepython">df.to_csv('data.csv') # 保存为 data.csv 文件 df.to_csv(None) # 返回 CSV 数据作为字符串
sep:
-
说明: 指定字段之间的分隔符。默认是逗号(
,)。你可以设置为其他字符,与read_csv()函数的意思一直,只不过这里是设置保存在文本中的分隔符号 -
类型:
strpython">df.to_csv('data.csv') # 保存为 data.csv 文件 df.to_csv('data.csv', sep=';') # 使用逗号作为分隔符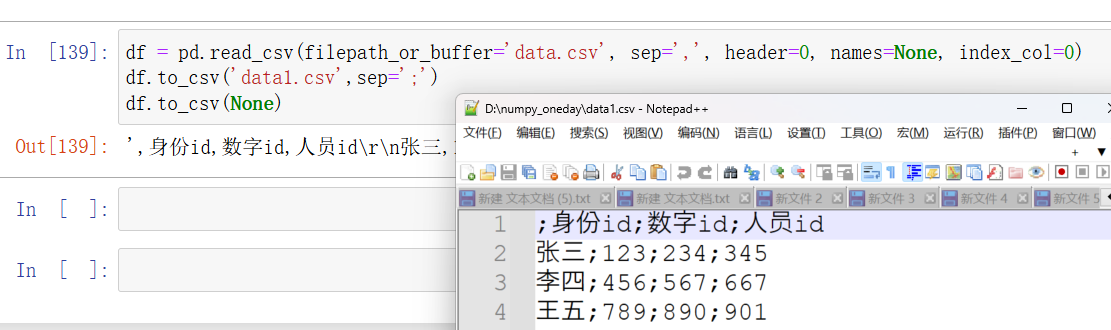
na_rep:
-
说明: 用于表示缺失数据的字符串。如果 DataFrame 中有缺失值,会用这个字符串代替。
-
类型:
str -
示例
python">df = pd.read_csv(filepath_or_buffer='data.csv', sep=',', header=0, index_col=0) df.loc['张三','国家'] = '333' df.to_csv('data1.csv', sep=',',na_rep="我是缺失的数据") csv_string = df.to_csv() print(csv_string)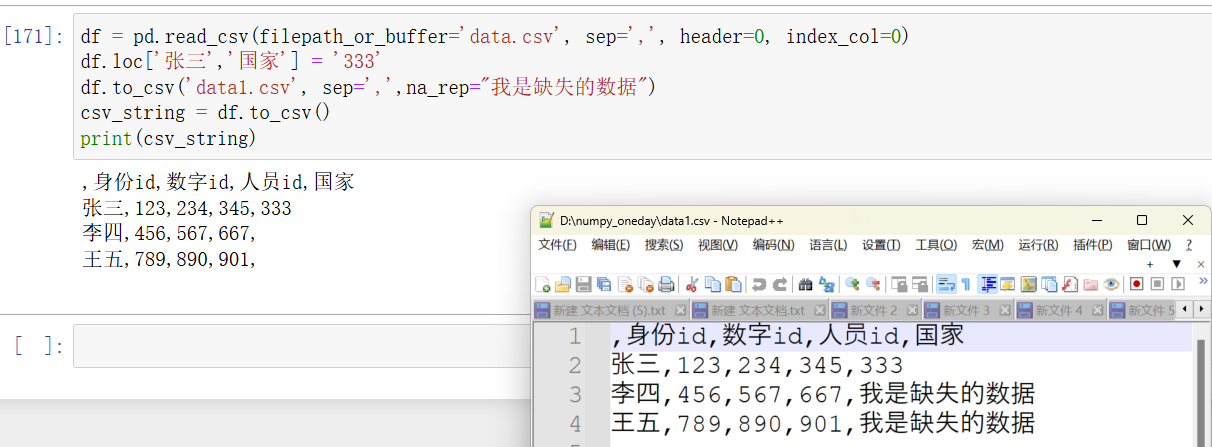
float_format:
-
说明: 格式化浮点数的格式字符串。例如
'%0.2f'表示保留两位小数。 -
类型:
str -
示例
:
python">df.to_csv('data.csv', float_format='%0.3f') # 浮点数格式为两位小数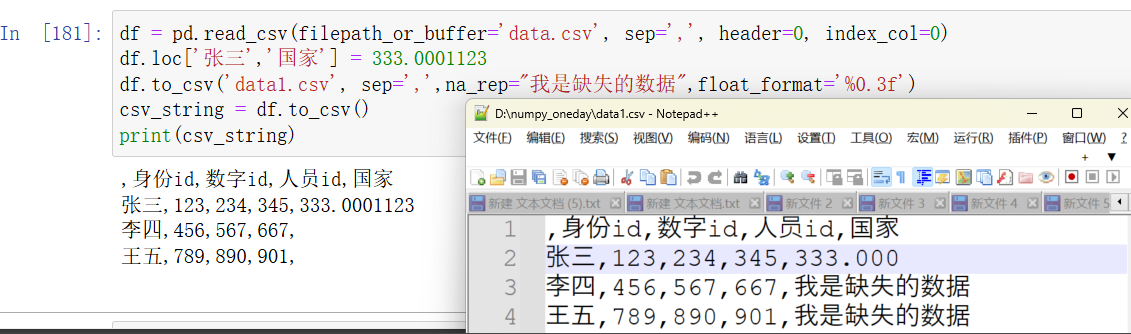
columns:
-
说明: 指定要写入 CSV 文件的列名。如果不指定,则写入所有列。
-
类型:
list或None -
示例
:
python">df.to_csv('data.csv', columns=['身份id']) # 只保存 '身份id' 和 '数字id' 列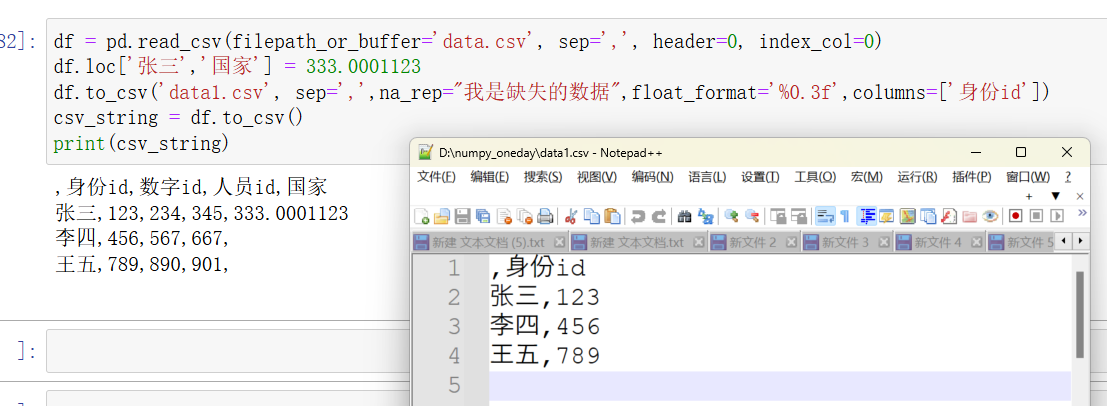
header:
-
说明: 是否写入列名。可以是布尔值(
True或False)或列名列表。如果为True,则写入列名;如果为False,则不写入列名。如果提供列名列表,则会覆盖默认的列名。 -
类型:
bool或list -
示例
:
python">df.to_csv('data.csv', header=True) # 写入列名 df.to_csv('data.csv', header=False) # 不写入列名 df.to_csv('data.csv', header=['1', '2', '3']) # 使用自定义列名,自定义的列名数量必须要和源数据的一致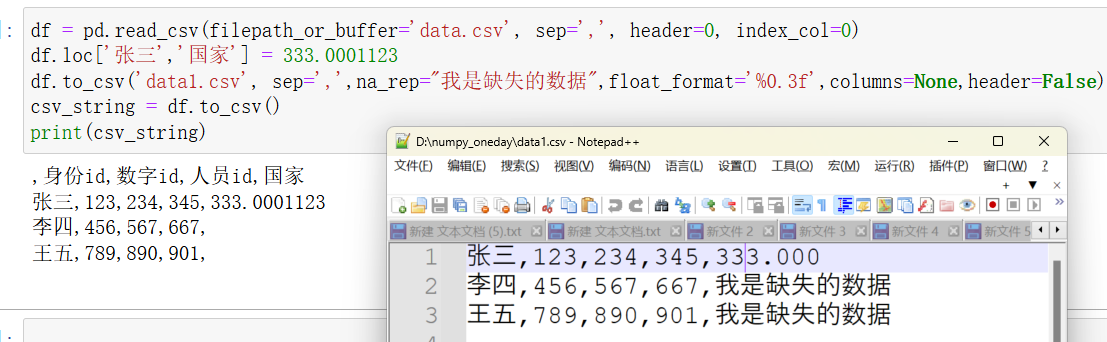
index:
-
说明: 是否写入行索引。默认为
True,即写入行索引。如果设置为False,则不写入行索引。 -
类型:
bool -
示例
:
python">df.to_csv('data.csv', index=True) # 写入行索引 df.to_csv('data.csv', index=False) # 不写入行索引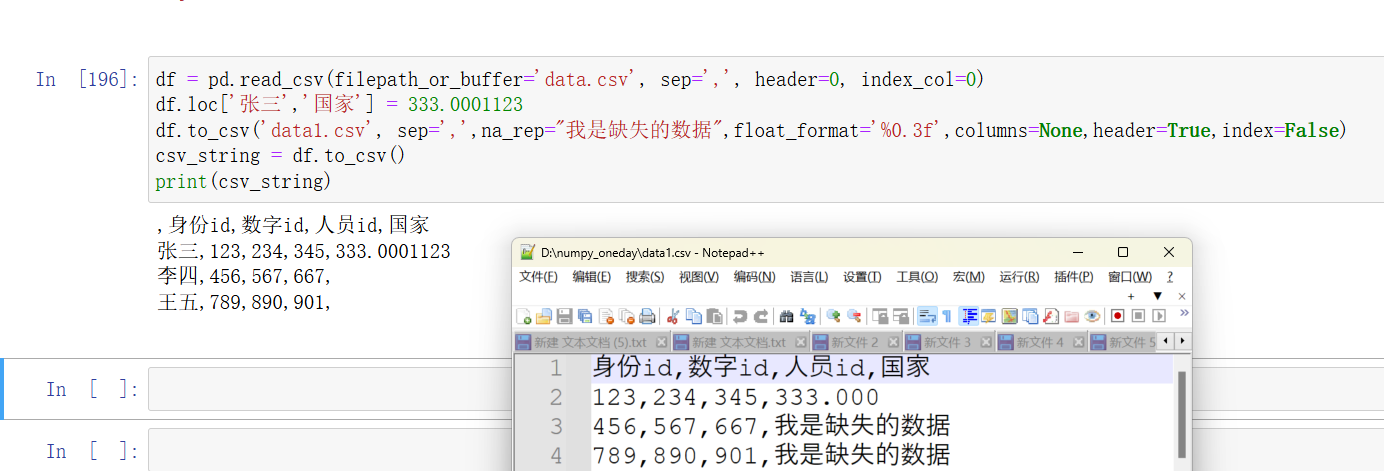
index_label:
-
说明: 行索引的列名。如果
index为True,可以指定索引列的名称。如果不指定,则不设置索引列名。 -
类型:
str或None -
示例
:
python">df.to_csv('data.csv', index=True, index_label='索引') # 行索引列名为 '索引'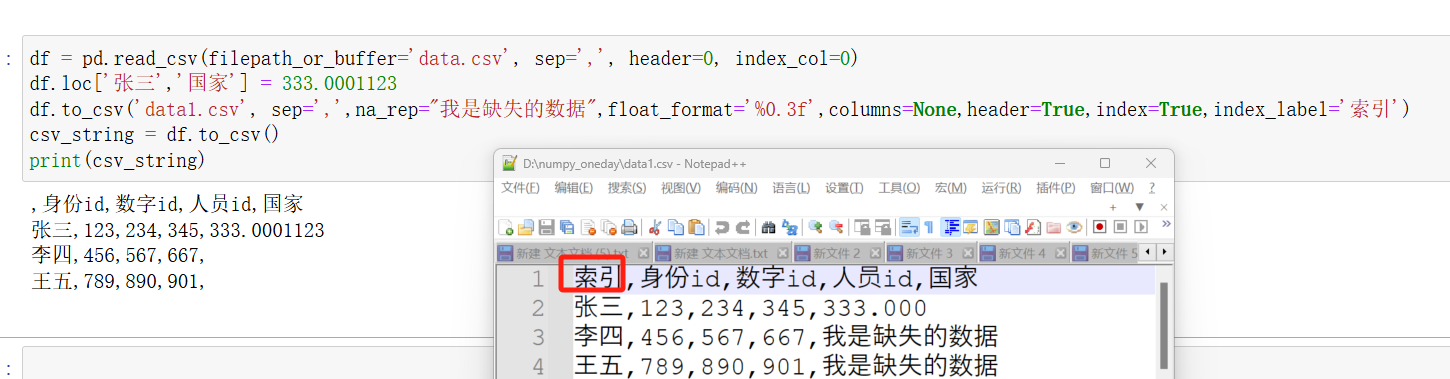
mode:
-
说明: 文件打开模式。默认是
'w'(写模式)。可以设置为'a'(追加模式),将数据追加到现有文件的末尾。 -
类型:
str -
示例
:
python">df.to_csv('data.csv', mode='w') # 写模式(覆盖原文件) df.to_csv('data.csv', mode='a') # 追加模式(追加到文件末尾)
compression:
-
说明: 文件压缩方式。可以设置为
'infer'(根据文件扩展名自动推断)、'bz2'、'gzip'、'xz'、'zip'等。如果使用压缩格式,可以通过compression_options参数提供额外的压缩选项。 -
类型:
str或dict或None -
示例
:
python">df.to_csv('data.csv.gz', compression='gzip') # 使用 gzip 压缩 df.to_csv('data.zip', compression='zip') # 使用 zip 压缩
2. Excel 文件
Excel 是常用的电子表格格式,Pandas 支持使用 pd.read_excel() 函数读取 .xlsx 和 .xls 文件。注意,这需要安装额外的依赖库,如 openpyxl(用于 .xlsx)或 xlrd(用于 .xls)。
# 读取 Excel 文件
df = pd.read_excel('data.xlsx', sheet_name='Sheet1')# 查看前几行数据
print(df.head())
pandasto_excel_226">1)读取excel文件(pandas.to_excel())
-
io:-
说明: 文件路径、URL、Excel 文件对象、或
StringIO对象。 -
类型:
str,pathlib.Path,file-like object,StringIOpython">df = pd.read_excel(io=pathlib.Path('data.xlsx'))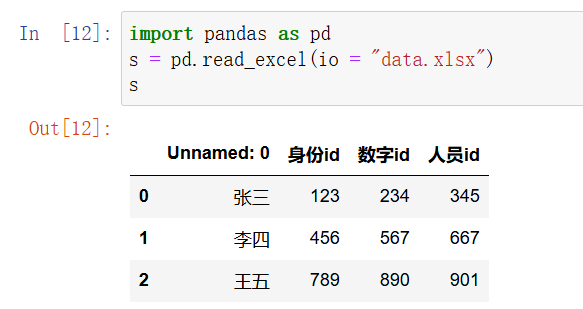
-
-
sheet_name:-
说明: 要读取的工作表名称或位置。如果有多个工作表,可以使用列表指定多个工作表。
-
类型:
str,int,list,Nonepython">df = pd.read_excel('data.xlsx', sheet_name='Sheet1') # 读取名为 'Sheet1' 的工作表 df = pd.read_excel('data.xlsx', sheet_name=0) # 读取第一个工作表 df = pd.read_excel('data.xlsx', sheet_name=['Sheet1', 'Sheet2']) # 读取多个工作表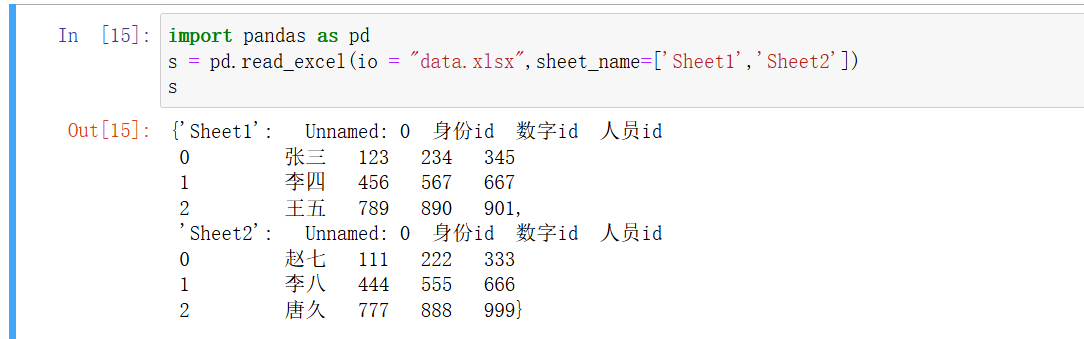
-
-
header:-
说明: 指定哪一行作为列名。默认为 0,表示第 0 行作为列名。可以设置为
None表示没有列名,或提供行号作为列名,如果设置其他行序号,则会跳过这个序号之前的数据。 -
类型:
int,list,Nonepython">df = pd.read_excel('data.xlsx', header=0) # 使用第 0 行作为列名 df = pd.read_excel('data.xlsx', header=None) # 不使用任何行作为列名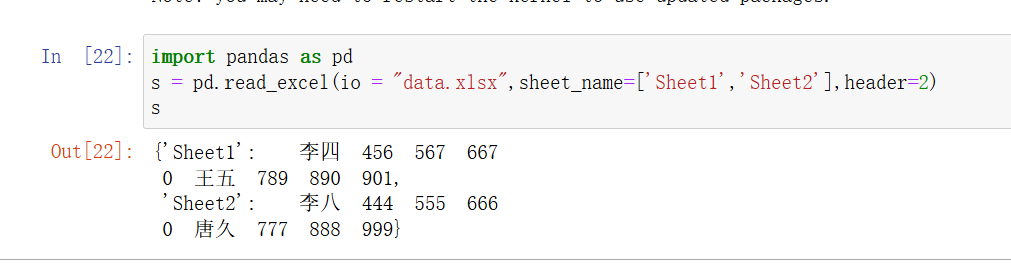
-
-
names:-
说明: 如果
header=None,可以通过names参数指定列名列表,列名的数量取决于names列表的长度,从第一列开始逐一命名。 -
类型:
listpython">df = pd.read_excel('data.xlsx', header=None, names=['A', 'B', 'C'])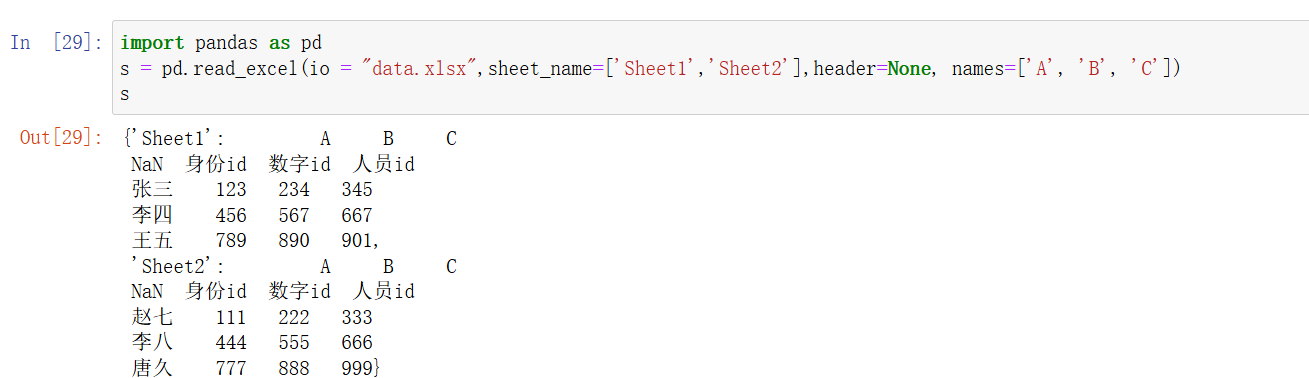
-
names列表中的每一个值都会被设置为对应列的列名,不会影响 Series 的name属性。 -
如果列数比
names指定的多余或不足,可能会出现列名缺失或数据丢失的问题。
-
-
-
index_col:-
说明: 指定哪一列作为行索引。默认为
None,即不设置索引列。 -
类型:
int,str,Nonepython">df = pd.read_excel('data.xlsx', index_col=3) # 使用第 0 列作为行索引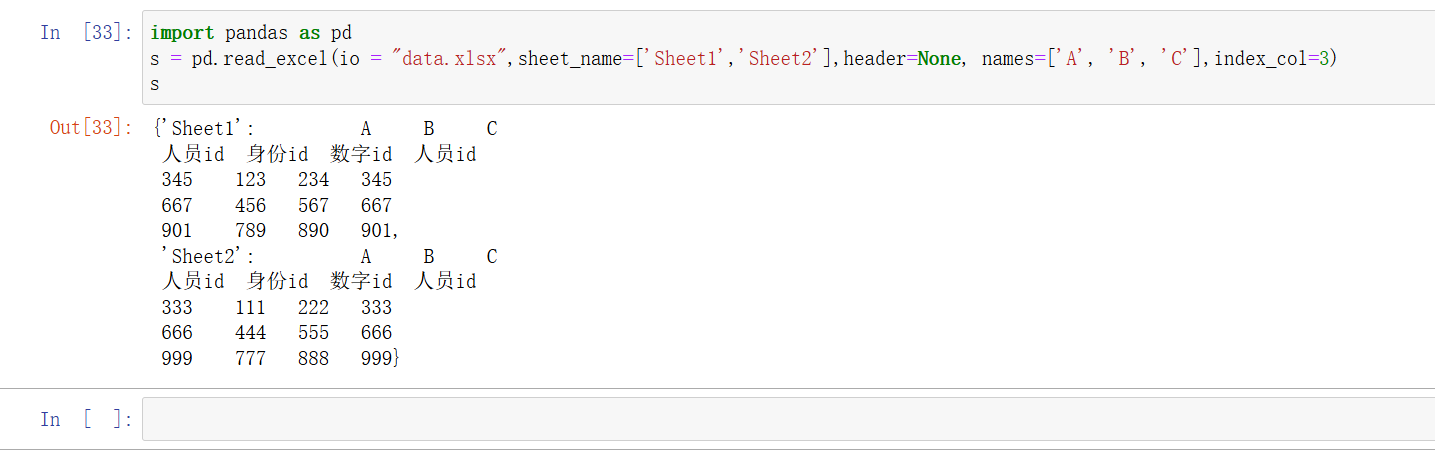
-
-
usecols:-
说明: 指定要读取的列。可以使用列名、列号、或列名的范围(例如
'A:C'指定 Excel 文件中的列字母范围)。可以是字符串、列表或范围。 -
类型:
str,list,callablepython">df = pd.read_excel('data.xlsx', usecols='A:C') # 读取 A 到 C 列Excel 文件中的列字母范围 df = pd.read_excel('data.xlsx', usecols=['身份id','数字id']) Series列名字 df = pd.read_excel('data.xlsx', usecols=[0, 2, 4]) # 读取第 0、2、4 列 列序号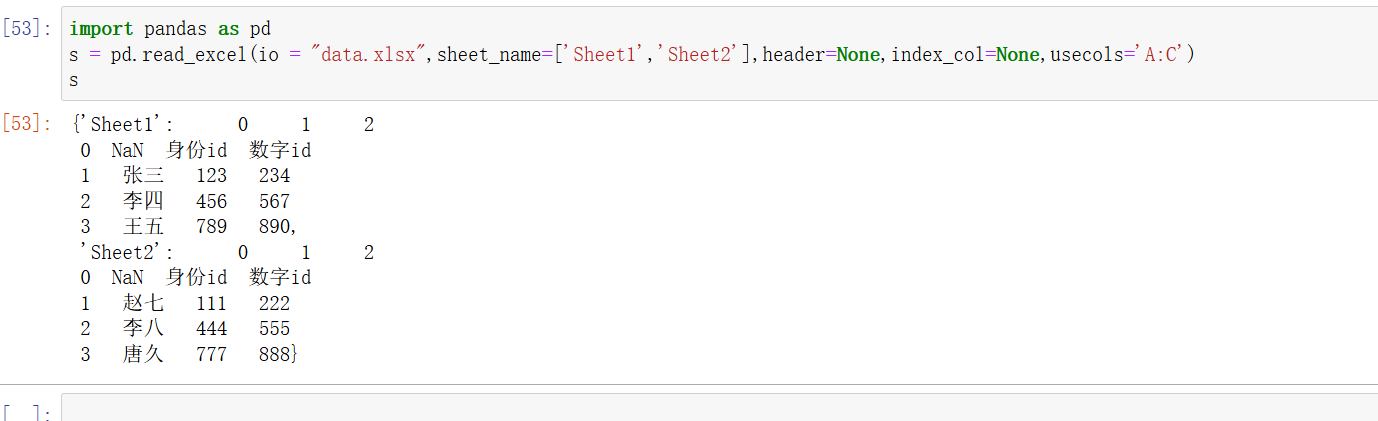
-
-
dtype:-
说明: 指定列的数据类型。可以是数据类型的字典,也可以是具体的类型。
-
类型:
typeordictdf = pd.read_excel('data.xlsx', dtype={'A': float, 'B': str}) # 指定 A 列为 float 类型,B 列为 str 类型
-
-
skiprows:-
说明: 跳过文件开头的行数。可以是整数,也可以是行号的列表。
-
类型:
int,listpython">df = pd.read_excel('data.xlsx', skiprows=2) # 跳过前两行 df = pd.read_excel('data.xlsx', skiprows=[1, 3]) # 跳过第 1 和第 3 行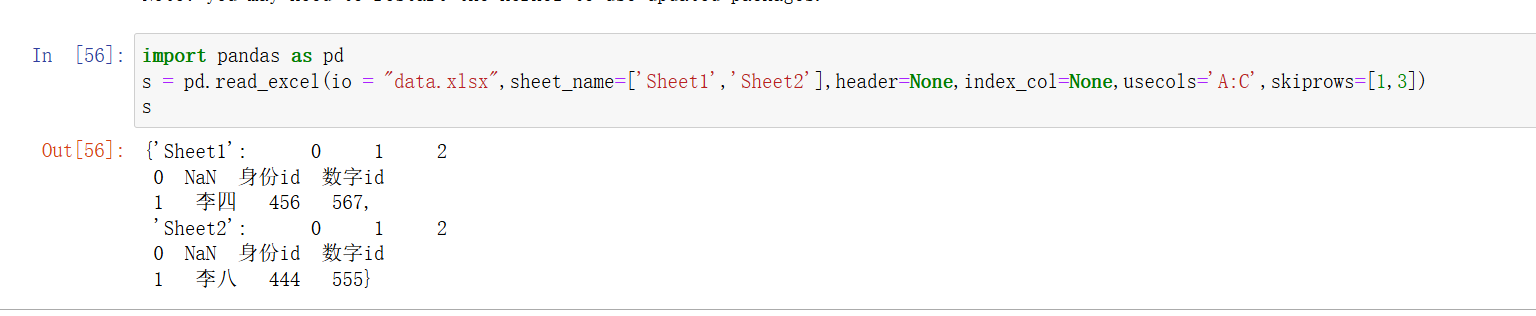
-
-
nrows:-
说明: 读取指定数量的行。
-
类型:
intpython">df = pd.read_excel('data.xlsx', nrows=3) # 只读取前 10 行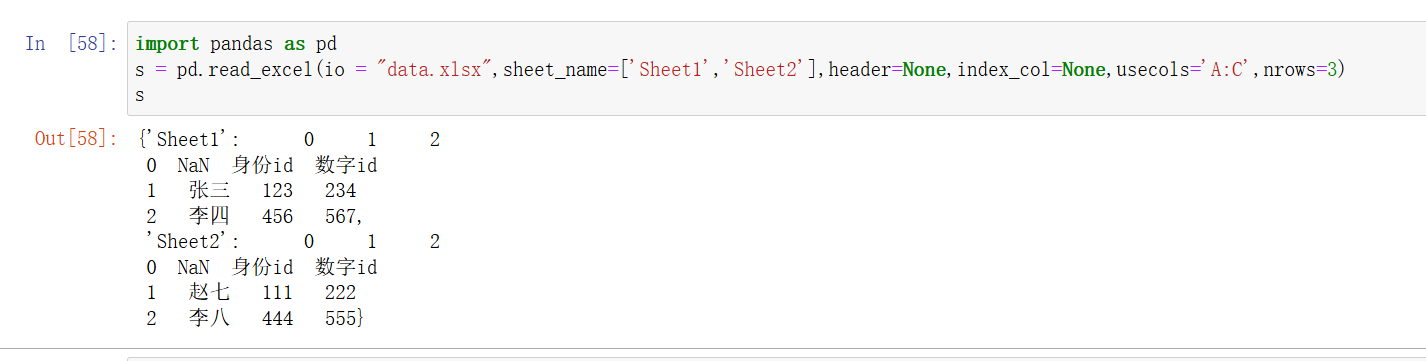
-
-
encoding:-
说明: 文件编码。默认为
None。可以指定编码格式,例如'utf-8'或'latin1'。 -
类型:
strpython">df = pd.read_excel('data.xlsx', encoding='utf-8')
-
-
engine:-
说明: 指定解析引擎。可以是
'openpyxl'(用于.xlsx)或'xlrd'(用于.xls)。如果不指定,pandas会根据文件格式自动选择引擎。 -
类型:
strpython">df = pd.read_excel('data.xlsx', engine='openpyxl') # 指定使用 openpyxl 引擎
-
2)保存excel文件(to_excel())
excel_writer:
-
说明: 指定要保存的 Excel 文件名或路径,或者传入
pandas.ExcelWriter对象。 -
类型:
str,path-like,ExcelWriterpython">df.to_excel('output.xlsx') # 保存为名为 output.xlsx 的文件
sheet_name:
-
说明: 指定工作表的名称。可以是单个字符串(表示单个工作表),也可以是一个列表(当使用
ExcelWriter保存多个工作表时)。 -
类型:
str,listpython">df.to_excel('output.xlsx', sheet_name='Sheet1') # 保存到名为 Sheet1 的工作表
na_rep:
-
说明: 用于表示缺失数据(NaN)时的填充值。
-
类型:
strpython">df.to_excel('output.xlsx', na_rep='N/A') # 将 NaN 值表示为 'N/A'
columns:
-
说明: 指定要保存的列。可以是列名的列表或
None(保存所有列)。 -
类型:
list,Nonepython">df.to_excel('output.xlsx', columns=['col1', 'col2']) # 只保存 'col1' 和 'col2' 列
header:
-
说明: 是否写入列名。
True表示写入,False表示不写入。 -
类型:
bool,listpython">df.to_excel('output.xlsx', header=False) # 不写入列名
index:
-
说明: 是否写入行索引。
True表示写入索引,False表示不写入索引。 -
类型:
boolpython">df.to_excel('output.xlsx', index=False) # 不写入行索引
index_label:
-
说明: 用于指定行索引的标签。如果
index为True,可以使用此参数指定索引的名称。 -
类型:
str,list,Nonepython">df.to_excel('output.xlsx', index_label='Index') # 指定索引列的名称为 'Index'
startrow:
-
说明: 数据写入工作表的起始行,默认值为 0。
-
类型:
intpython">df.to_excel('output.xlsx', startrow=2) # 从第 3 行开始写入数据
startcol:
-
说明: 数据写入工作表的起始列,默认值为 0。
-
类型:
intpython">df.to_excel('output.xlsx', startcol=2) # 从第 3 列开始写入数据
engine:
-
说明: 指定用于写入 Excel 文件的引擎。常见的引擎包括
openpyxl(默认用于.xlsx文件)和xlsxwriter。 -
类型:
strpython">df.to_excel('output.xlsx', engine='xlsxwriter') # 使用 xlsxwriter 引擎
3. JSON 文件
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于 Web API 返回的数据格式。Pandas 提供了 pd.read_json() 函数来读取 JSON 文件。
# 读取 JSON 文件
df = pd.read_json('data.json')# 查看前几行数据
print(df.head())
pandasread_json_478">1)读取JSON文件(pandas.read_json())
-
path_or_buf:-
说明: JSON 文件的路径或类文件对象。也可以是 JSON 数据的字符串。
-
类型:
str,PathLike,file-like object,Nonepython">df = pd.read_json('data.json') # 从文件读取 df = pd.read_json('{"name": ["Alice", "Bob"], "age": [25, 30]}') # 从字符串读取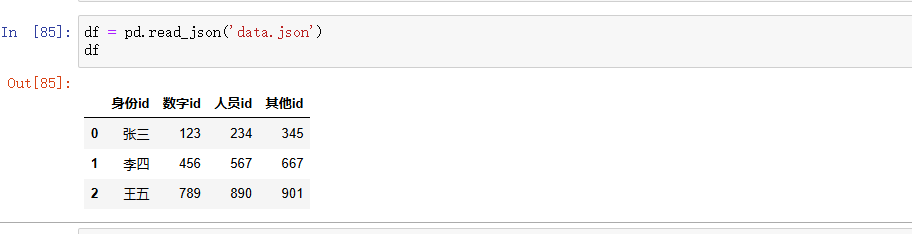
-
-
orient:-
说明: JSON 数据的格式。指定 JSON 数据的结构,决定如何解析 JSON 文件。常见值包括
'split','records','index','columns','values'。 -
类型:
str-
- JSON 格式为
'split'{ 'index': [...], 'columns': [...], 'data': [...] }python">df = pd.read_json('data.json', orient='split') -
- JSON 格式为记录的列表,例如
'records'[{ "name": "Alice", "age": 25 }, { "name": "Bob", "age": 30 }]python">df = pd.read_json('data.json', orient='records') -
- JSON 格式为
'index'{ index: { column: value } }python">df = pd.read_json('data.json', orient='index') -
- JSON 格式为
'columns'{ column: { index: value } }python">df = pd.read_json('data.json', orient='columns') -
- JSON 格式为二维数组,例如
'values'[[name1, age1], [name2, age2]]python">df = pd.read_json('data.json', orient='values')
-
-
'split'
说明: JSON 数据的格式为
{ 'index': [...], 'columns': [...], 'data': [...] }。其中,'index'是行索引,'columns'是列名,'data'是二维数据数组(每个子数组表示 DataFrame 的一行)。适用场景: 当 JSON 数据以这种结构存储时,用于读取具有明确索引和列名的 DataFrame。
{"index": [0, 1],"columns": ["name", "age"],"data": [["Alice", 25],["Bob", 30]] }python">df = pd.read_json('data.json', orient='split')
'records'
说明: JSON 数据的格式为一个对象的列表,其中每个对象都是一个记录(即每个 JSON 对象表示 DataFrame 的一行)。适用于结构较简单的记录集合。
适用场景: 当 JSON 数据以记录的列表形式存储时,例如从数据库导出的数据。
[{ "name": "Alice", "age": 25 },{ "name": "Bob", "age": 30 } ]python">df = pd.read_json('data.json', orient='records')
'index'
说明: JSON 数据的格式为
{ index: { column: value } }。其中,index是行索引,内部的对象表示每行的列值。适用场景: 当 JSON 数据以索引作为键,每个索引的值是一个包含列和值的对象时。
{"0": { "name": "Alice", "age": 25 },"1": { "name": "Bob", "age": 30 } }python">df = pd.read_json('data.json', orient='index')
'columns'
说明: JSON 数据的格式为
{ column: { index: value } }。其中,column是列名,每列的值是一个包含行索引和值的对象。适用场景: 当 JSON 数据以列名作为键,每个列名的值是一个包含行索引和值的对象时。
{"name": {"0": "Alice","1": "Bob"},"age": {"0": 25,"1": 30} }python">df = pd.read_json('data.json', orient='columns')
'values'
说明: JSON 数据的格式为二维数组(列表的列表),每个子列表表示 DataFrame 的一行,没有行索引和列名。
适用场景: 当 JSON 数据仅包含数据部分,没有明确的行索引和列名时。
[["Alice", 25],["Bob", 30] ]python">df = pd.read_json('data.json', orient='values')总结
'split': 适合有明确索引和列名的数据。'records': 适合记录列表形式的数据。'index': 适合以索引为主的 JSON 数据。'columns': 适合以列为主的 JSON 数据。'values': 适合没有行索引和列名的数据。选择适当的
orient参数可以确保 JSON 数据被正确地解析成 DataFrame 格式。
-
typ:-
说明: 读取 JSON 数据的类型。
'frame'表示返回 DataFrame,'series'表示返回 Series。 -
类型:
strdf = pd.read_json('data.json', typ='frame') # 默认,返回 DataFrame
-
-
dtype:-
说明: 数据类型转换。默认
True,pandas会根据数据自动推断数据类型。 -
类型:
bool,dict,Nonedf = pd.read_json('data.json', dtype={'age': 'int32'}) # 将 'age' 列的类型强制转换为 int32
-
-
convert_axes:-
说明: 是否转换索引和列为适当的数据类型。默认为
True。 -
类型:
booldf = pd.read_json('data.json', convert_axes=False) # 不转换索引和列
-
-
convert_dates:-
说明: 是否自动解析日期。默认为
True,即尝试将日期字符串转换为日期类型。 -
类型:
booldf = pd.read_json('data.json', convert_dates=False) # 不解析日期
-
-
keep_default_dates:-
说明: 是否保留默认的日期格式。默认为
True,保留默认日期格式。 -
类型:
booldf = pd.read_json('data.json', keep_default_dates=False) # 不保留默认日期格式
-
-
precise_float:-
说明: 是否使用精确的浮点数表示。默认为
False,可以设置为True以提高精度。 -
类型:
booldf = pd.read_json('data.json', precise_float=True) # 使用精确浮点数
-
-
date_unit:-
说明: 用于解析日期的单位,常用的值包括
'D','s','ms'等。 -
类型:
strdf = pd.read_json('data.json', date_unit='s') # 日期单位为秒
-
-
encoding:-
说明: 文件的编码格式。常用的编码包括
'utf-8'和'latin1'。 -
类型:
strdf = pd.read_json('data.json', encoding='utf-8') # 使用 UTF-8 编码
-
-
lines:-
说明: 是否按行读取 JSON 文件。用于处理按行存储的 JSON 文件(每行一个 JSON 对象)。
-
类型:
booldf = pd.read_json('data.json', lines=True) # 按行读取 JSON 文件
-
-
chunksize:-
说明: 用于分块读取 JSON 数据的大小。返回一个迭代器,每次返回一个 DataFrame 的块。
-
类型:
intchunks = pd.read_json('data.json', chunksize=1000) # 每次读取 1000 行数据 for chunk in chunks:process(chunk) # 处理每个块
-
-
compression:-
说明: JSON 文件的压缩类型。常见值包括
'infer','bz2','gzip','xz'。 -
类型:
str,Nonedf = pd.read_json('data.json.gz', compression='gzip') # 从压缩文件读取
-
2)保存JSON文件(to_json())
path_or_buf:
-
说明: JSON 文件的路径或类文件对象。如果指定了路径,数据将保存到该路径的文件中。如果为
None,则返回 JSON 格式的字符串。 -
类型:
str,PathLike,file-like object,None -
示例
:
python复制代码df.to_json('data.json') # 保存到文件 json_str = df.to_json() # 返回 JSON 字符串
orient:
-
说明: JSON 数据的格式。指定保存 JSON 的结构。常见值包括
'split','records','index','columns','values'。 -
类型:
str-
'split'df.to_json('data.json', orient='split') -
'records'df.to_json('data.json', orient='records') -
'index'df.to_json('data.json', orient='index') -
'columns'df.to_json('data.json', orient='columns') -
'values'df.to_json('data.json', orient='values')
-
date_format:
-
说明: 日期格式。可以是
'epoch'(时间戳格式)或'iso'(ISO 8601 格式)。默认为None,即不进行日期格式化。 -
类型:
str,Nonedf.to_json('data.json', date_format='iso') # 使用 ISO 8601 日期格式
double_precision:
-
说明: 双精度浮点数的精度。默认是
10位小数。 -
类型:
intdf.to_json('data.json', double_precision=5) # 设置浮点数精度为 5 位小数
default_handler:
-
说明: 自定义处理未序列化数据类型的函数。默认为
None。 -
类型:
callableimport numpy as npdef handle_complex(obj):if isinstance(obj, np.complex128):return str(obj)raise TypeError(f"Type {type(obj)} not serializable")df.to_json('data.json', default_handler=handle_complex)
lines:
-
说明: 是否将每个记录保存为一行 JSON 对象。适用于处理按行存储的 JSON 数据。
-
类型:
booldf.to_json('data.json', lines=True) # 按行存储 JSON 对象
compression:
-
说明: 压缩类型。常见值包括
'infer','bz2','gzip','xz'。默认为'infer',即自动推断。 -
类型:
str,Nonedf.to_json('data.json.gz', compression='gzip') # 保存为压缩的 JSON 文件
encoding:
-
说明: 文件编码格式。默认为
'utf-8'。 -
类型:
strdf.to_json('data.json', encoding='utf-8') # 使用 UTF-8 编码
index:
-
说明: 是否包含 DataFrame 的索引。默认为
True,即包含索引。 -
类型:
booldf.to_json('data.json', index=False) # 不保存索引
4. SQL 数据库
Pandas 支持从 SQL 数据库中读取数据,这需要使用 pd.read_sql() 函数。首先,需要建立与数据库的连接,常用的库有 sqlite3(用于 SQLite 数据库)或 SQLAlchemy(支持 MySQL、PostgreSQL 等)。
在使用pandas读取sql数据时候首先要安装 SQLAlchemy。还有 mysql-connector-python(MySQL) 或 pymysql(postgreSQL):
python">from sqlalchemy import create_engine# 数据库连接信息
username = 'root'
password = '123'
host = 'localhost' # 数据库服务器地址
port = '3306' # MySQL 默认端口
database = 'test_01'# 创建数据库连接字符串
connection_string = f'mysql+mysqlconnector://{username}:{password}@{host}:{port}/{database}'# 创建 SQLAlchemy 引擎
engine = create_engine(connection_string)pandasread_sql_938">1)读取SQL(pandas.read_sql())
-
sql:-
说明: SQL 查询或表名。如果是 SQL 查询,它将执行该查询;如果是表名,它将从指定表中读取数据。
-
类型:
strpython">sql = "SELECT * FROM people" # 或 sql = "people"# 表名 s = pd.read.sql(sql=sql)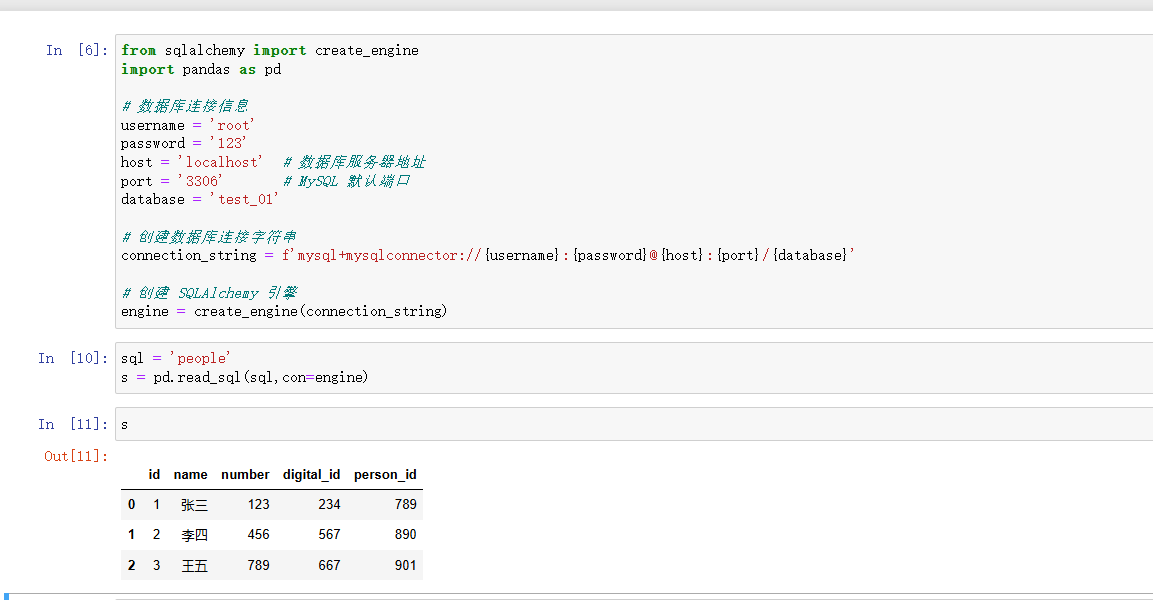
con:-
说明: 数据库连接对象。可以是 SQLAlchemy 引擎、数据库连接字符串或数据库连接对象。
-
类型:
SQLAlchemy engine,sqlite3 connection,str(数据库连接字符串)python">from sqlalchemy import create_engine connection_string = f'mysql+mysqlconnector://{username}:{password}@{host}:{port}/{database}'
index_col:-
说明: 指定 DataFrame 的索引列。如果设置为列名或列的序号,读取的数据将使用该列作为索引。
-
类型:
str,int,Nonepython">df = pd.read_sql(sql, con, index_col='name')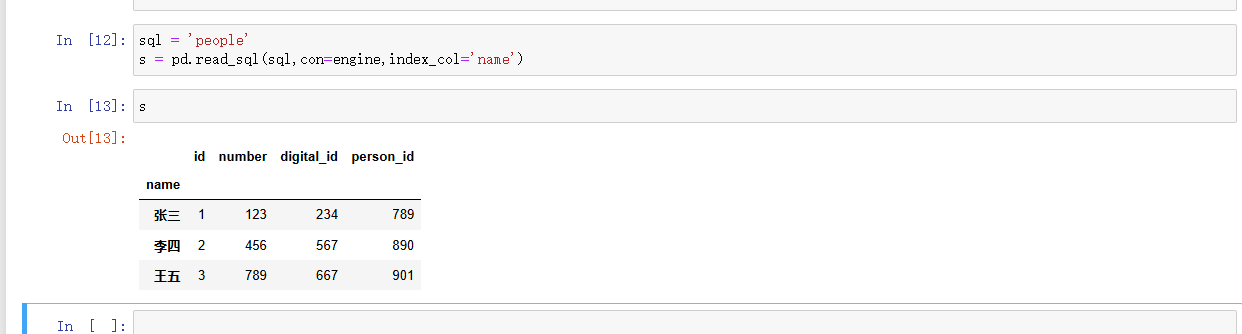
coerce_float:-
说明: 将非整数的浮点数据强制转换为浮点类型。默认为
True。 -
类型:
boolpython">df = pd.read_sql(sql, con, coerce_float=False)
params:-
说明: SQL 查询中的参数。用于防止 SQL 注入攻击。如果
sql是带参数的 SQL 查询,可以通过该参数传递实际值。 -
类型:
list,tuple,dictpython">sql = "SELECT * FROM people WHERE department = %s" df = pd.read_sql(sql, con, params=('HR',))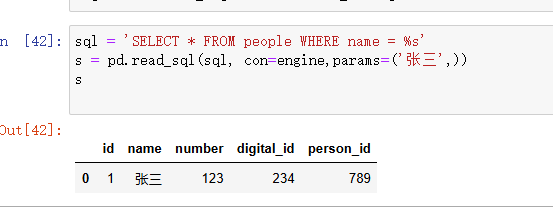
parse_dates:-
说明: 指定需要解析为日期的列。可以是列名的列表或字典。字典形式允许同时指定日期列和解析格式。
-
类型:
bool,list,dict,Nonepython">df = pd.read_sql(sql, con, parse_dates=['hire_date'])
chunksize:-
说明: 返回一个生成器,每次生成
chunksize行数据。这对于处理大型数据集特别有用。 -
类型:
int,Nonepython">chunks = pd.read_sql(sql, con, chunksize=1000) for chunk in chunks:# 处理每个数据块
-
2)保存SQL(to_sql())
name:
-
说明: 要保存数据的目标表名。如果表名已存在,
if_exists参数决定了如何处理。 -
类型:
strpython">s = pd.read_sql(sql, con=engine,params=('张三',)) s1 = pd.DataFrame({'id': [4, 5, 6],'name': ['赵六', '钱七', '孙八'],'number': [999, 888, 777],'digital_id': [234, 567, 678],'person_id': [902, 903, 904] })s1.to_sql('people', con=engine, if_exists='append', index=False)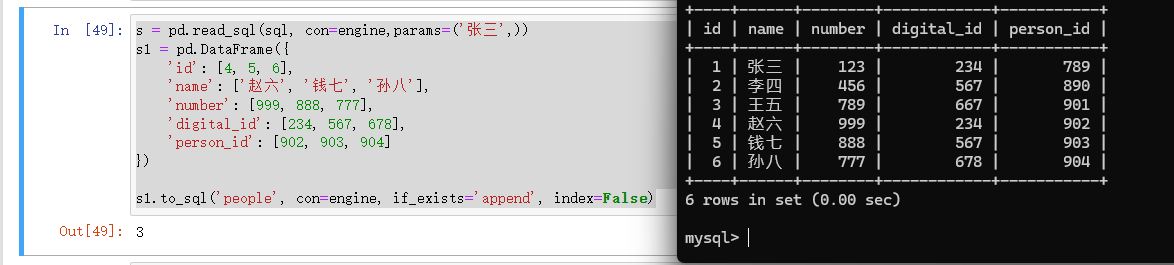
con:
-
说明: 数据库连接对象。可以是 SQLAlchemy 引擎、数据库连接字符串或数据库连接对象。
-
类型:
SQLAlchemy engine,sqlite3 connection,str(数据库连接字符串)python">from sqlalchemy import create_engine connection_string = f'mysql+mysqlconnector://{username}:{password}@{host}:{port}/{database}'
schema:
-
说明: 它用于指定表所在的数据库模式。数据库模式是一个数据库的逻辑分区,用于组织表、视图、索引等数据库对象。
-
类型:
str,Nonepython">df.to_sql('people', con=engine, schema='public')
if_exists:
-
说明: 如果目标表已经存在,指定如何处理。可以是
'fail'(默认,报错)、'replace'(删除旧表,创建新表)、'append'(追加到现有表)。 -
类型:
strdf.to_sql('people', con=engine, if_exists='replace')
index:
-
说明: 是否将 DataFrame 的索引保存为表中的列。默认为
True。 -
类型:
booldf.to_sql('people', con=engine, index=False)
index_label:
-
说明: 如果
index=True,可以指定索引列的标签名。 -
类型:
str,list,Nonedf.to_sql('people', con=engine, index_label='employee_id')
chunksize:
-
说明: 每次写入的行数,用于分块插入数据。适用于大数据集,可以减少内存占用。
-
类型:
int,Nonedf.to_sql('people', con=engine, chunksize=1000)
dtype:
-
说明: 指定列的数据类型。可以是列名与数据类型的映射字典。
-
类型:
dict,Nonefrom sqlalchemy.types import Integer, String df.to_sql('people', con=engine, dtype={'name': String(50), 'age': Integer})
method:
-
说明: 数据插入的方法。可以是
None(默认),或者是特定的插入方法如multi(使用 SQLAlchemy 的多值插入)。method='multi'可以提高插入性能。 -
类型:
str,Nonepython">df.to_sql('people', con=engine, method='multi')
总结
Pandas 提供了丰富的数据读取接口,支持常见的文件格式如 CSV、Excel、JSON、SQL,以及压缩文件和其他高效的数据存储格式。在读取数据时,根据不同的数据格式和需求,设置适当的参数能够帮助你更灵活地处理数据。





