Day 20 RNN 2 实际使用和其他应用
在实际的学习(training)过程中是如何工作的?
step 1 Loss
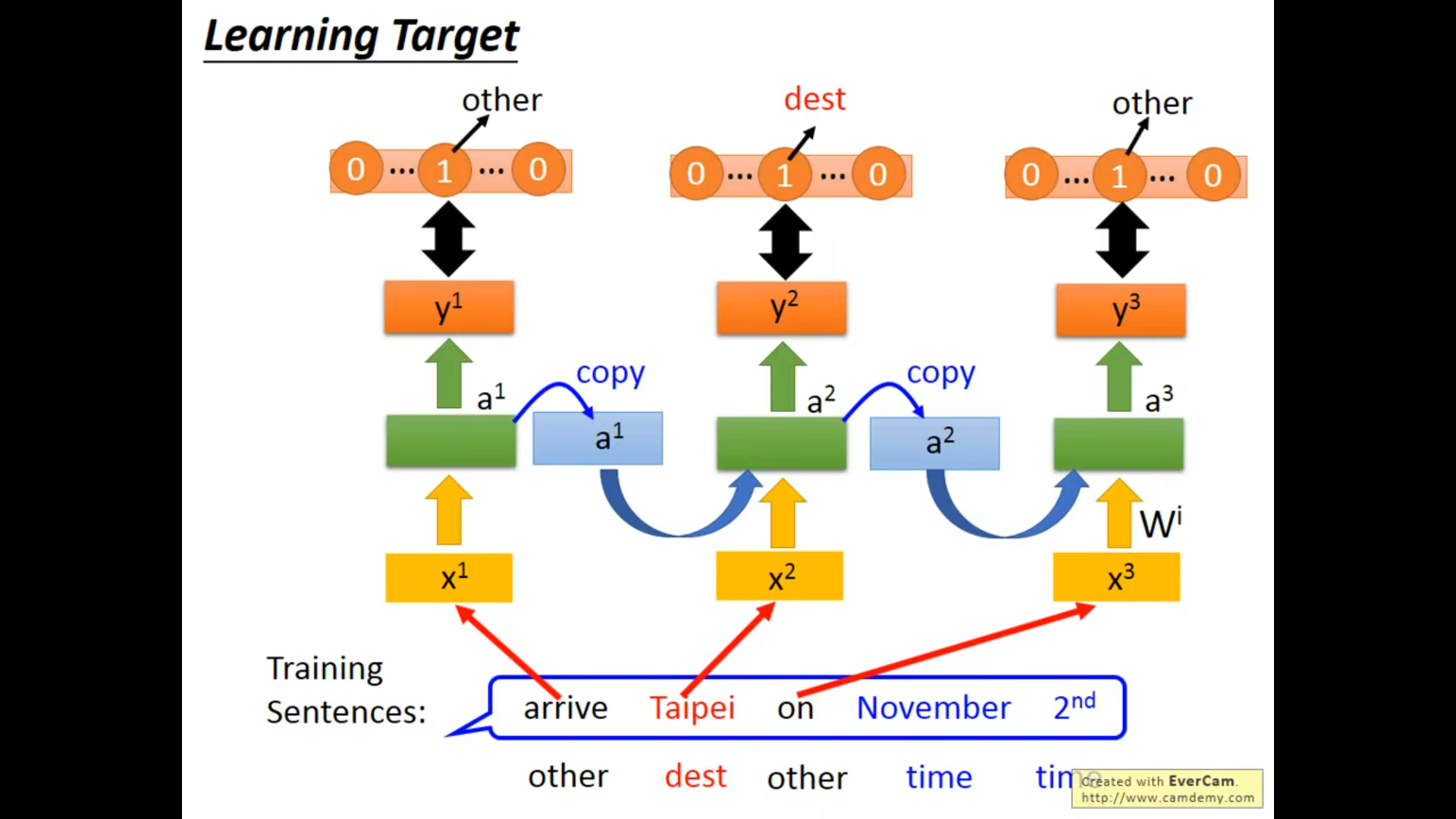
step 2 training
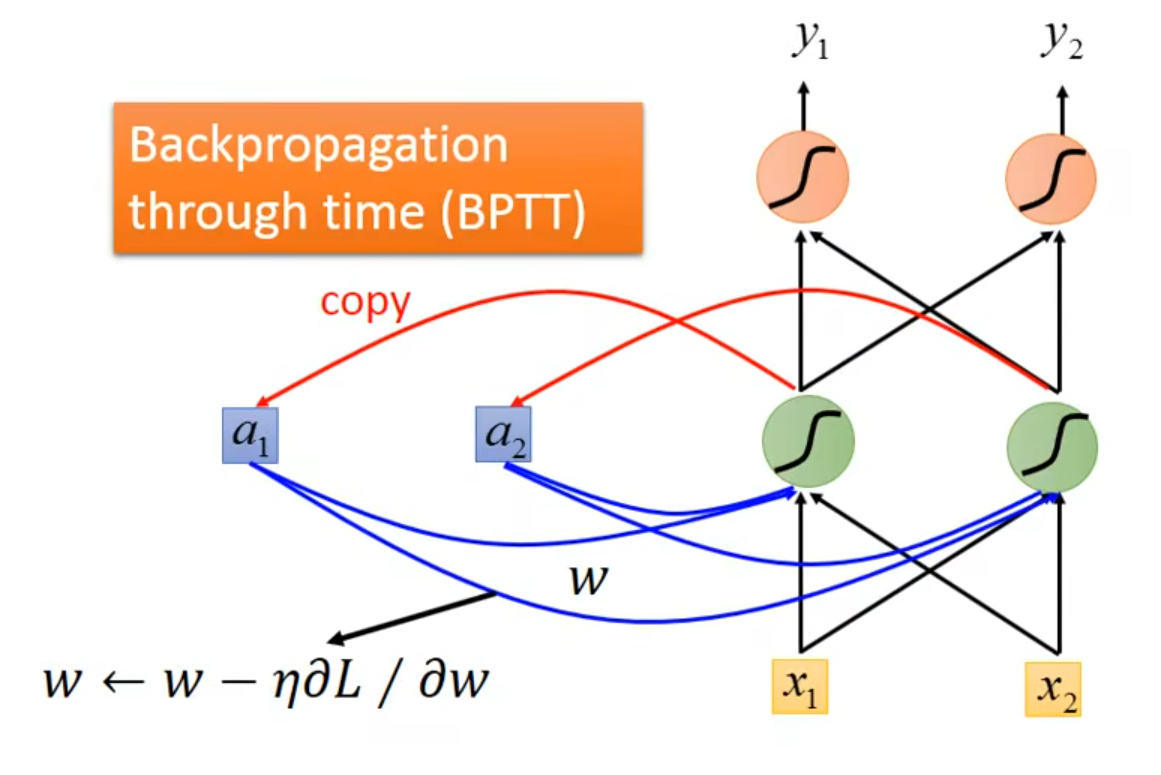
Graindent Descent
反向传播的进阶版 – BPTT

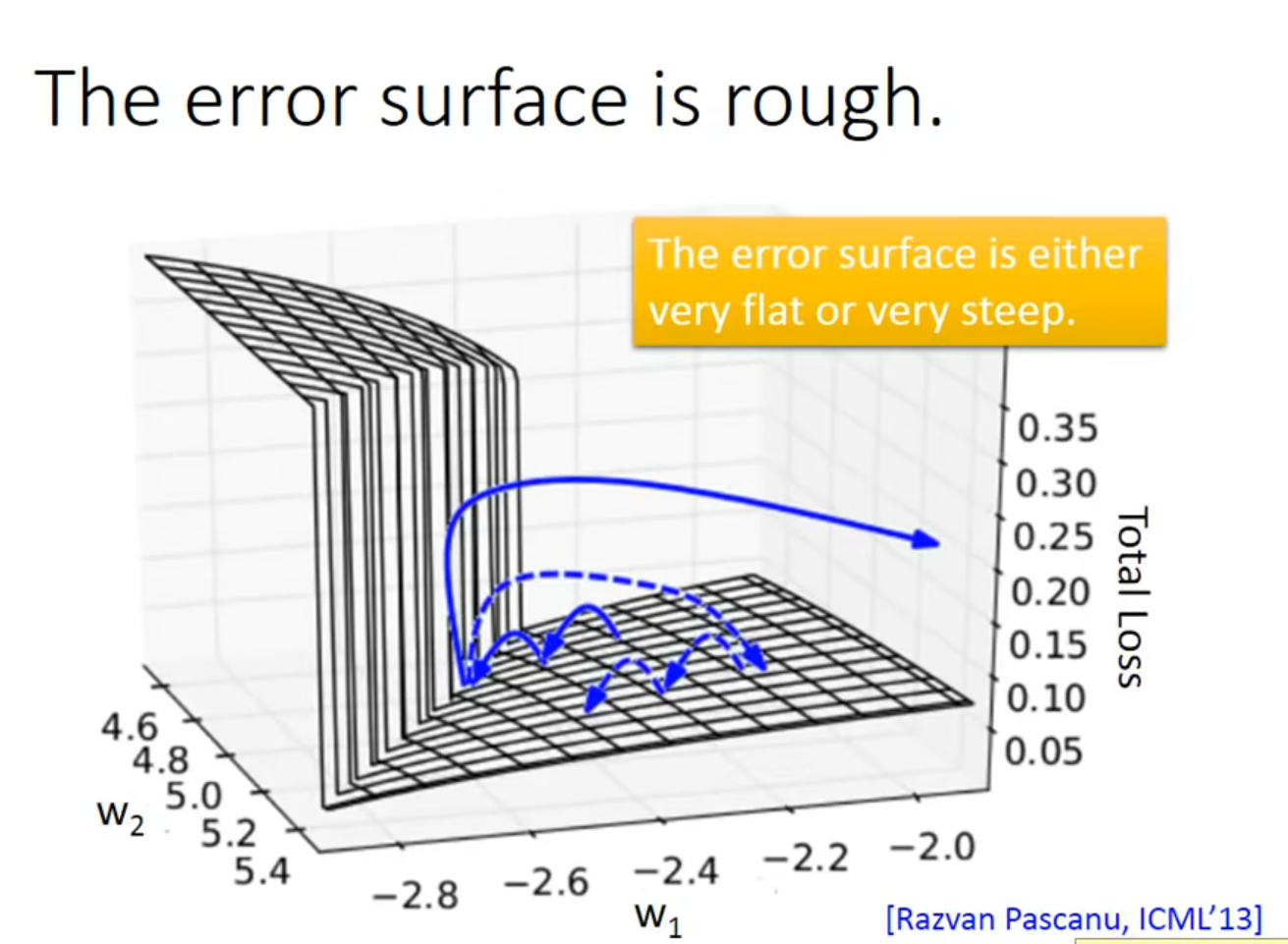
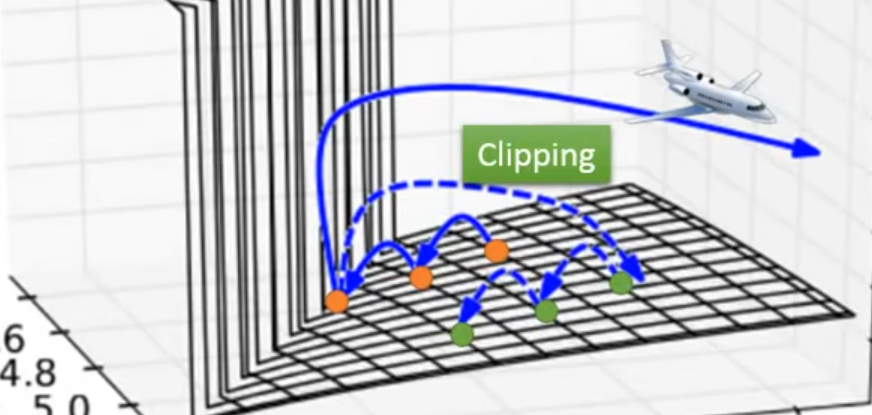
CLIpping 设置阈值~ 笑死昨天刚看完关伟说的有这玩意的就不是好东西
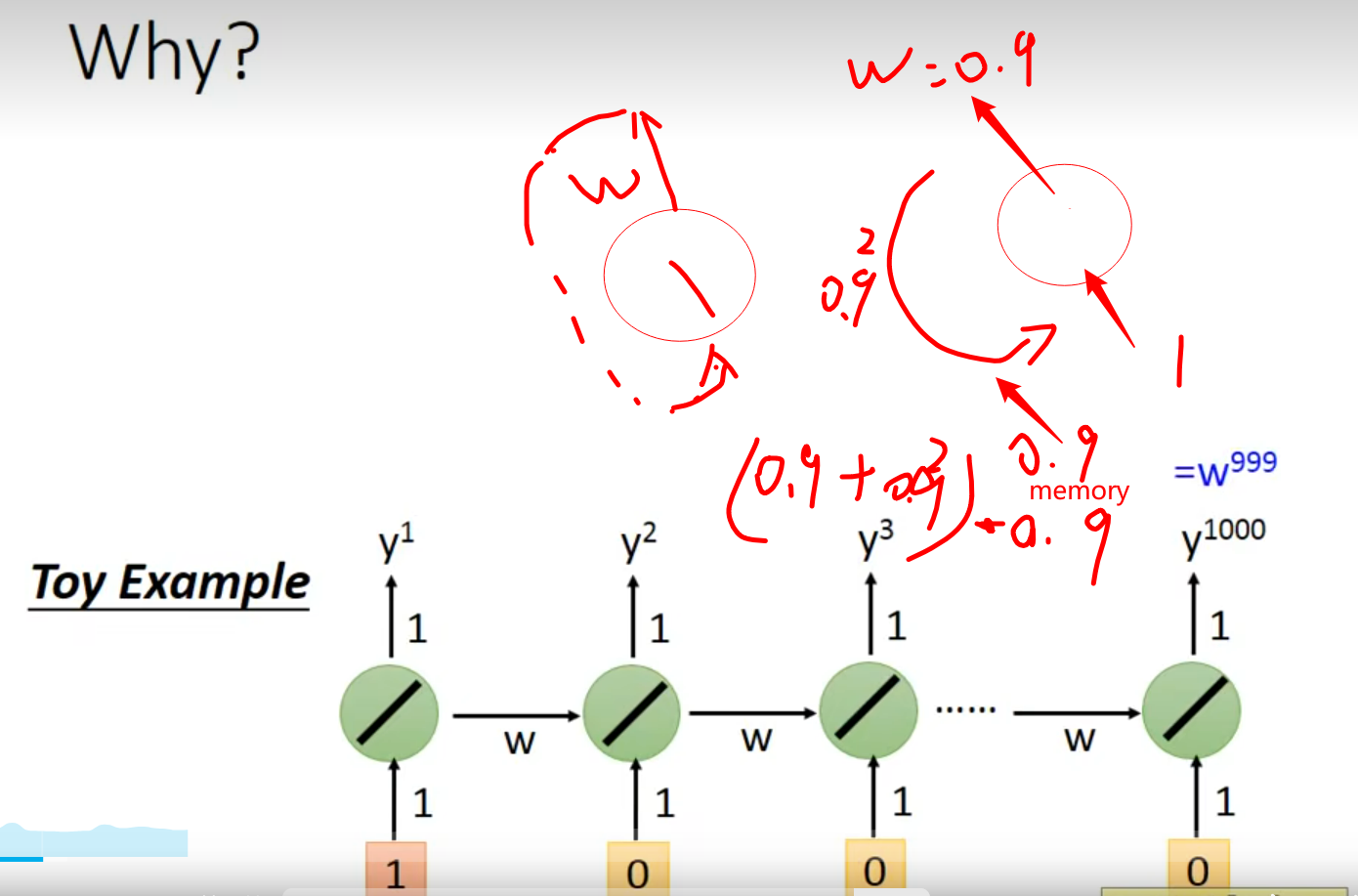
Why?出现了梯度steep or flat

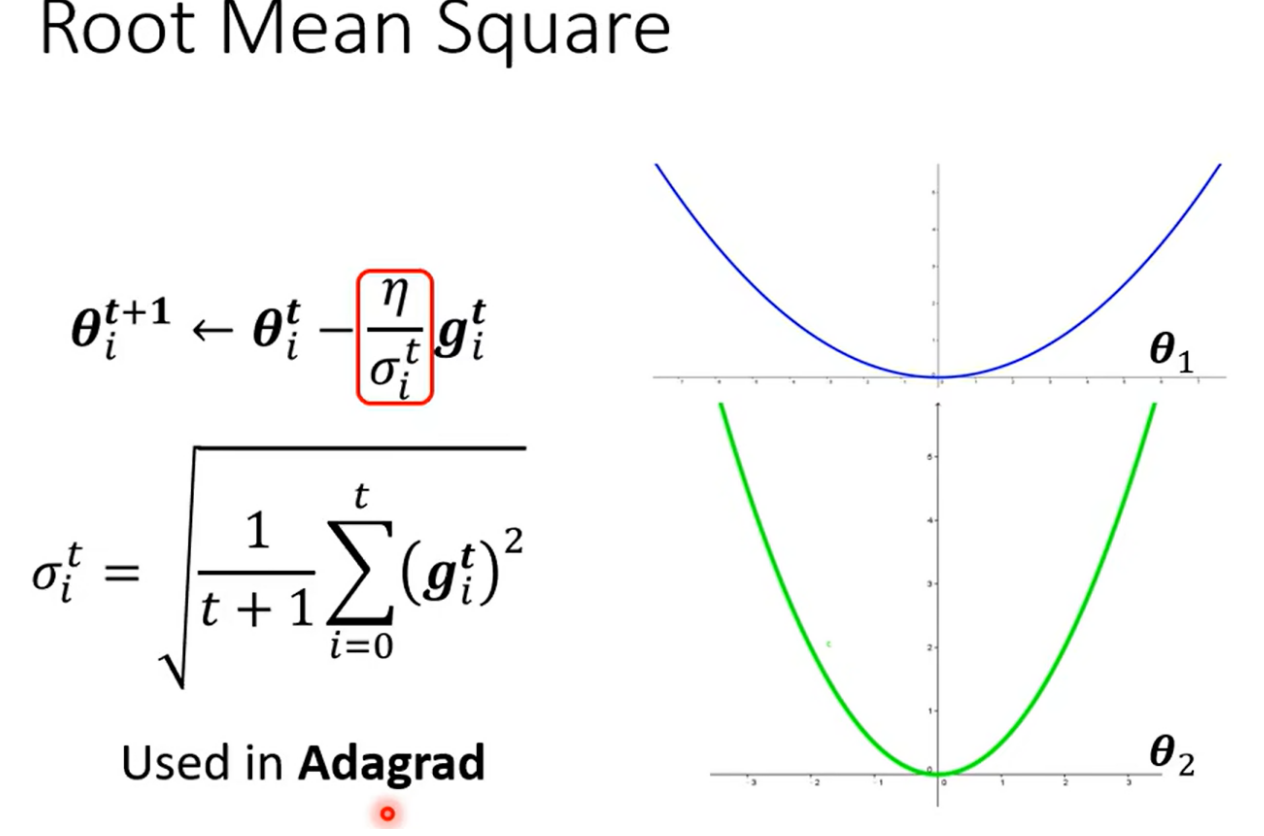
这里为什么不可以用Adagrad(RMS)或者 Adam(RMSPROP + momentum)?
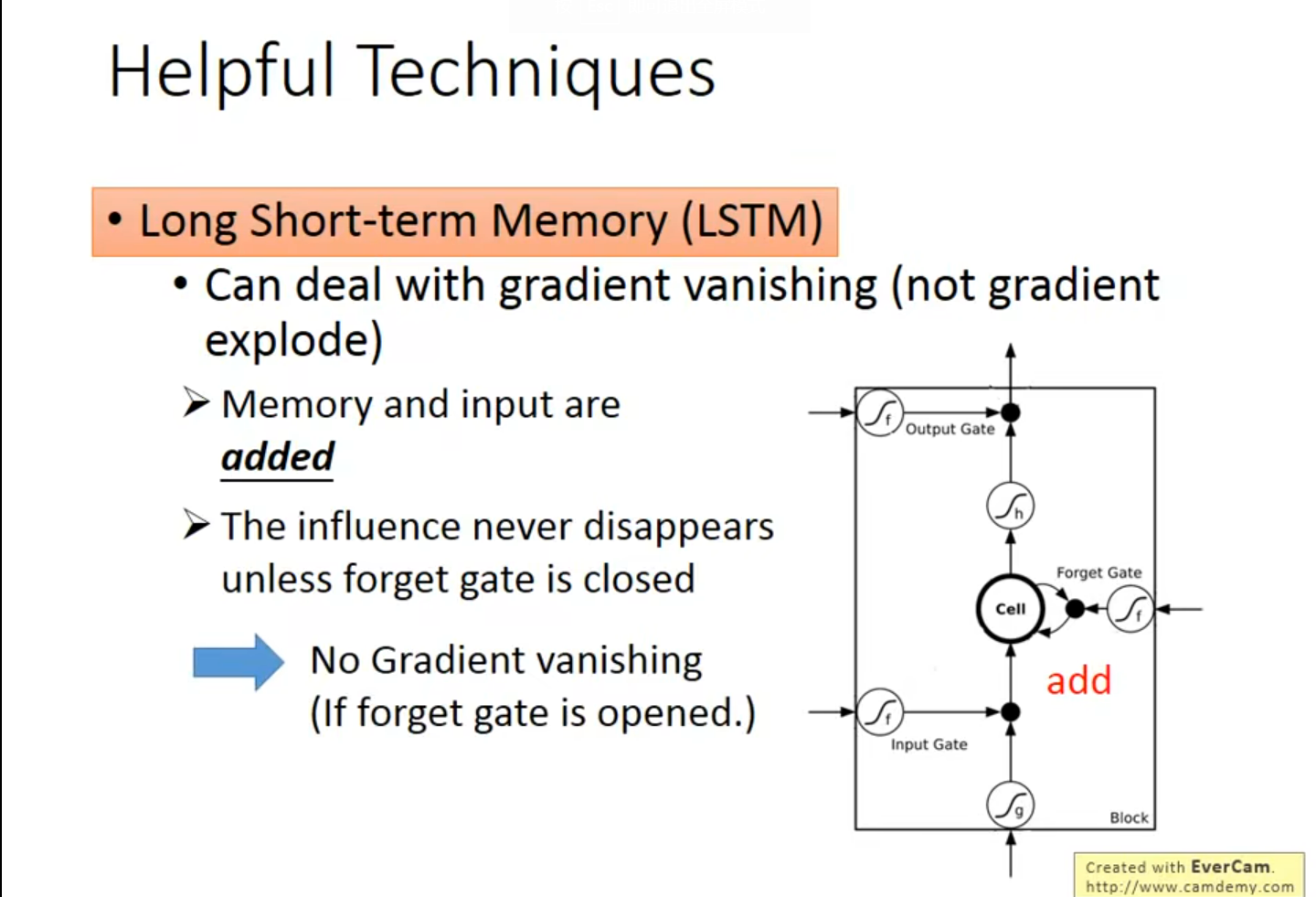
LSTM 可以解决梯度平坦的问题,但是不能解决steep,所以可以放心的将学习率设置的小一点;原理如下,凑乎看
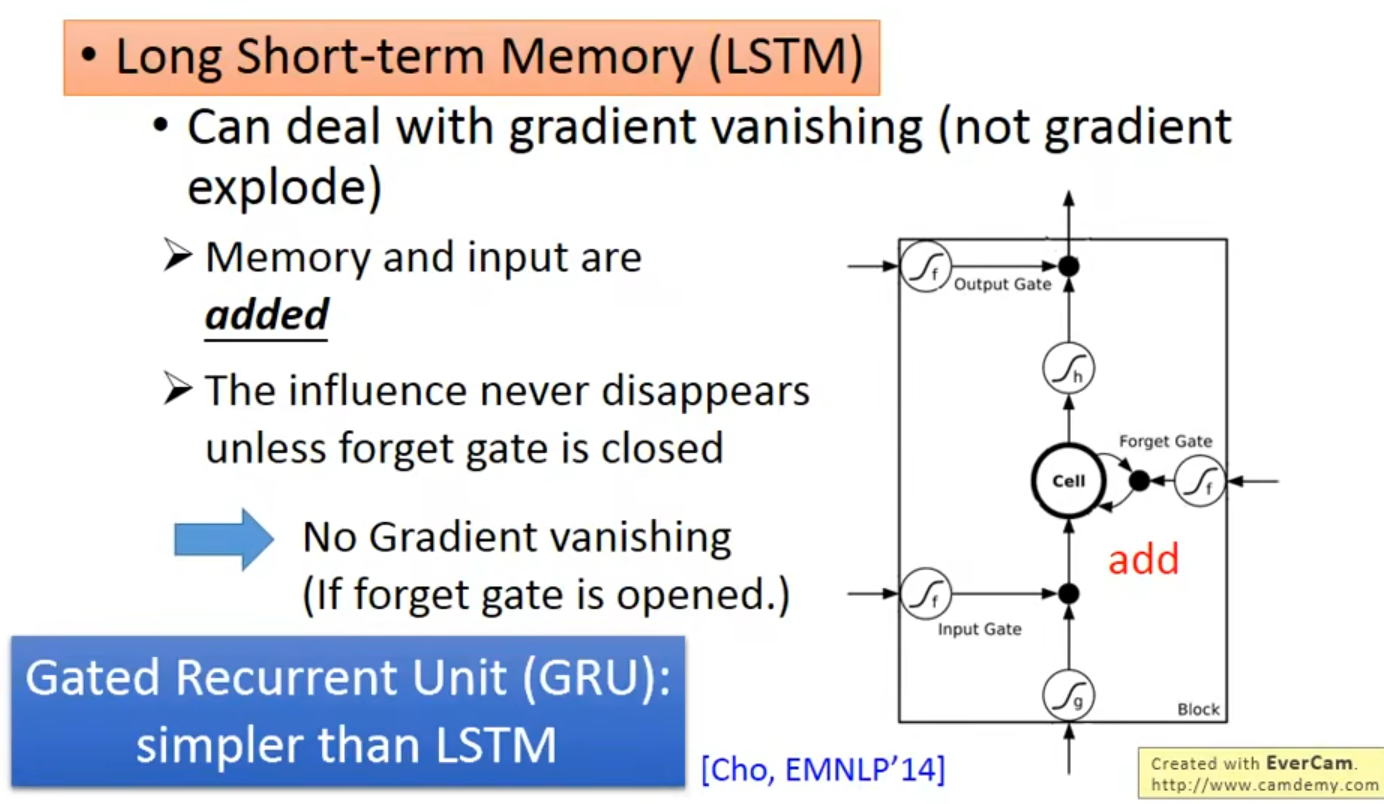
根据上面的思想,那么我可能需要保证我的forget gate 大多数情况下是开启的 (保留记忆)
Grated Recurrent Unit (GRU)Simpler than LSTM
联动forget 和 input gate 2选1
只有清除记忆新的Input 才能被放入
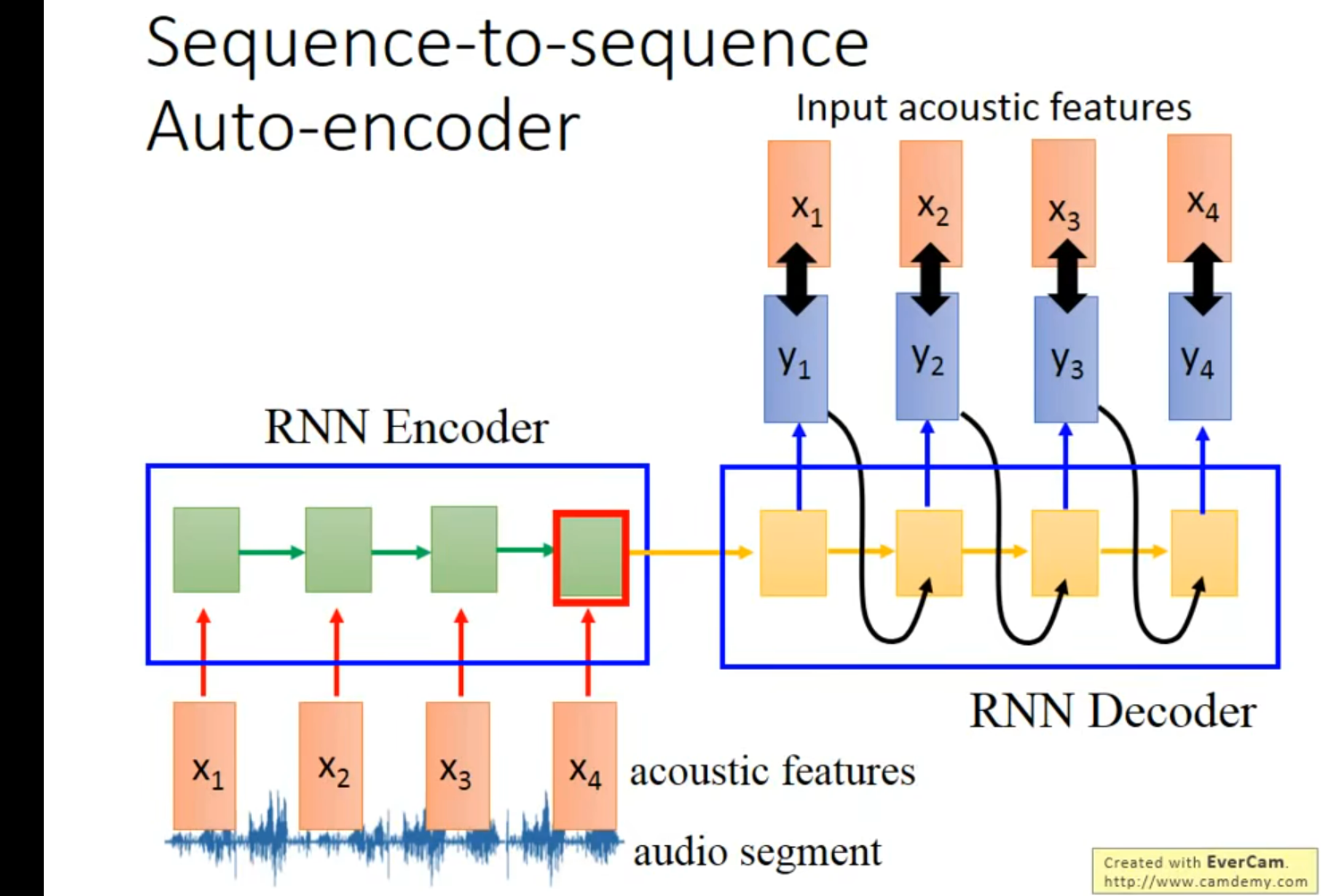
More Application
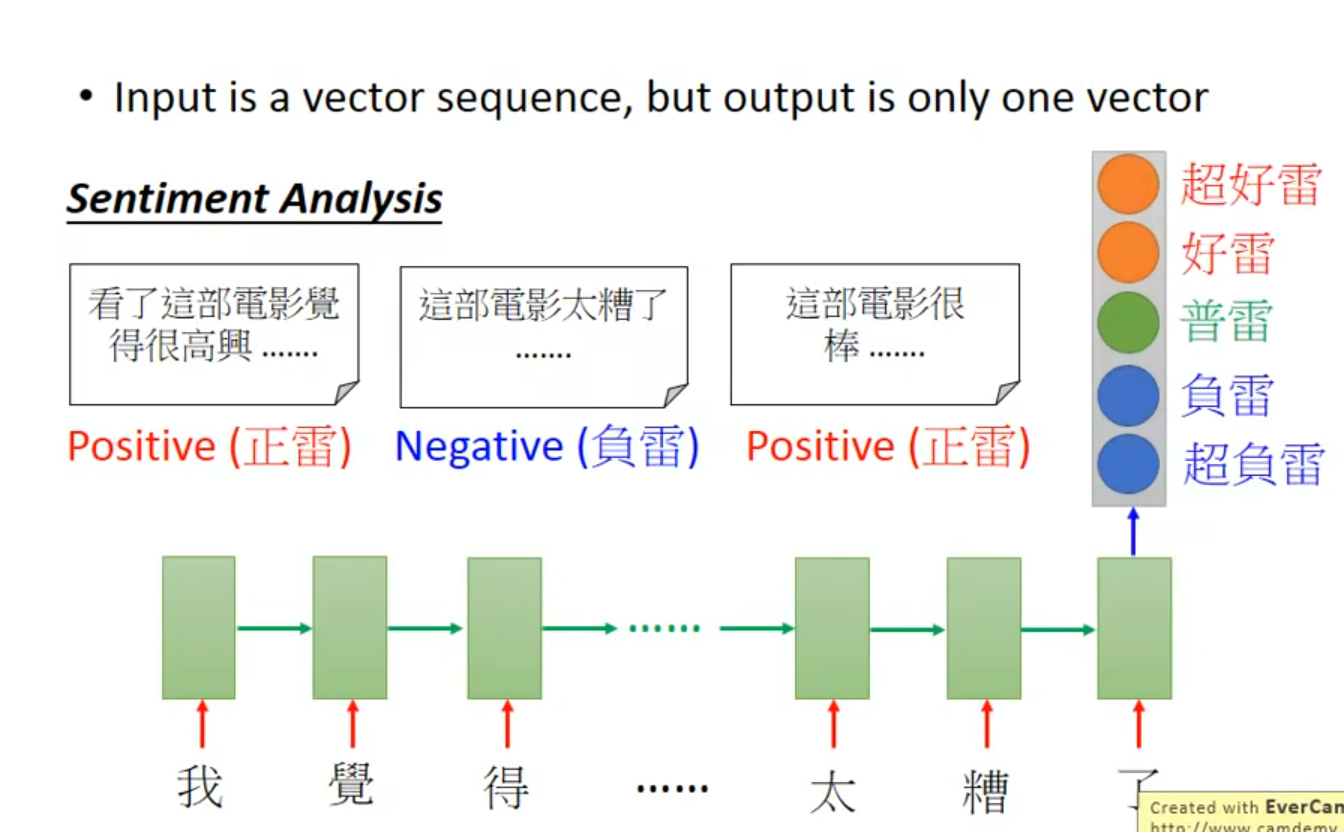
一到多
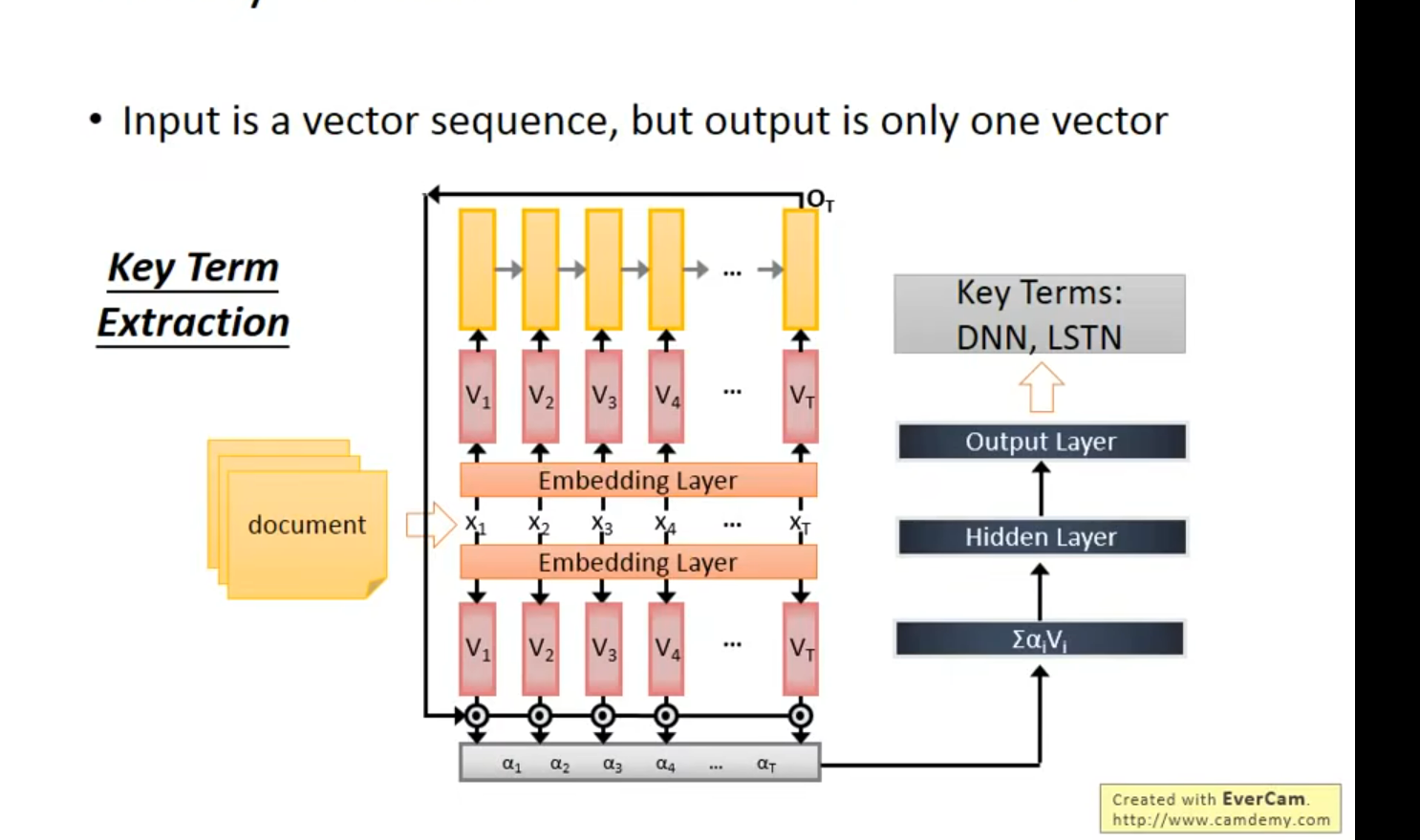
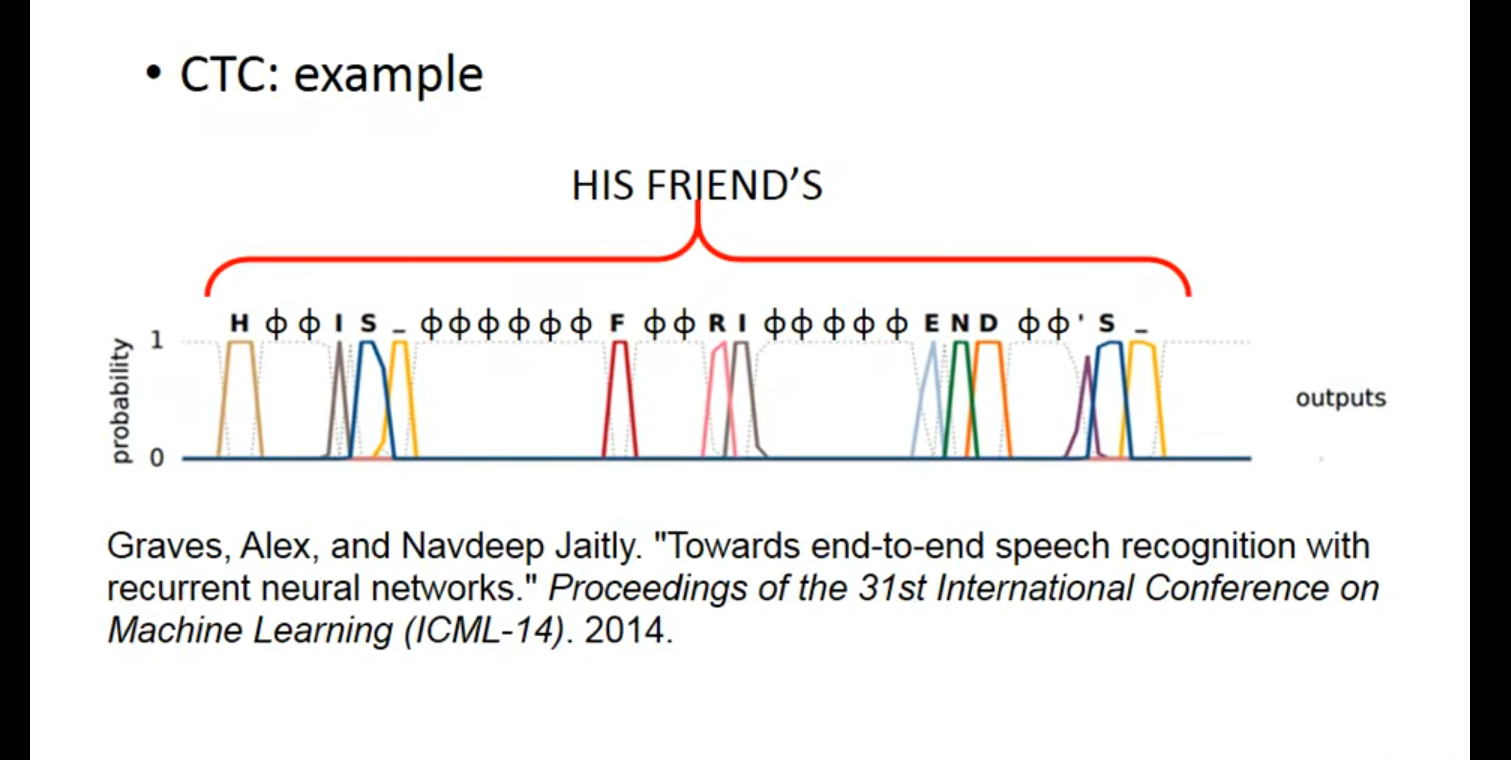
多到多(outputer is shorter) – 语音辨识 (贝叶斯)
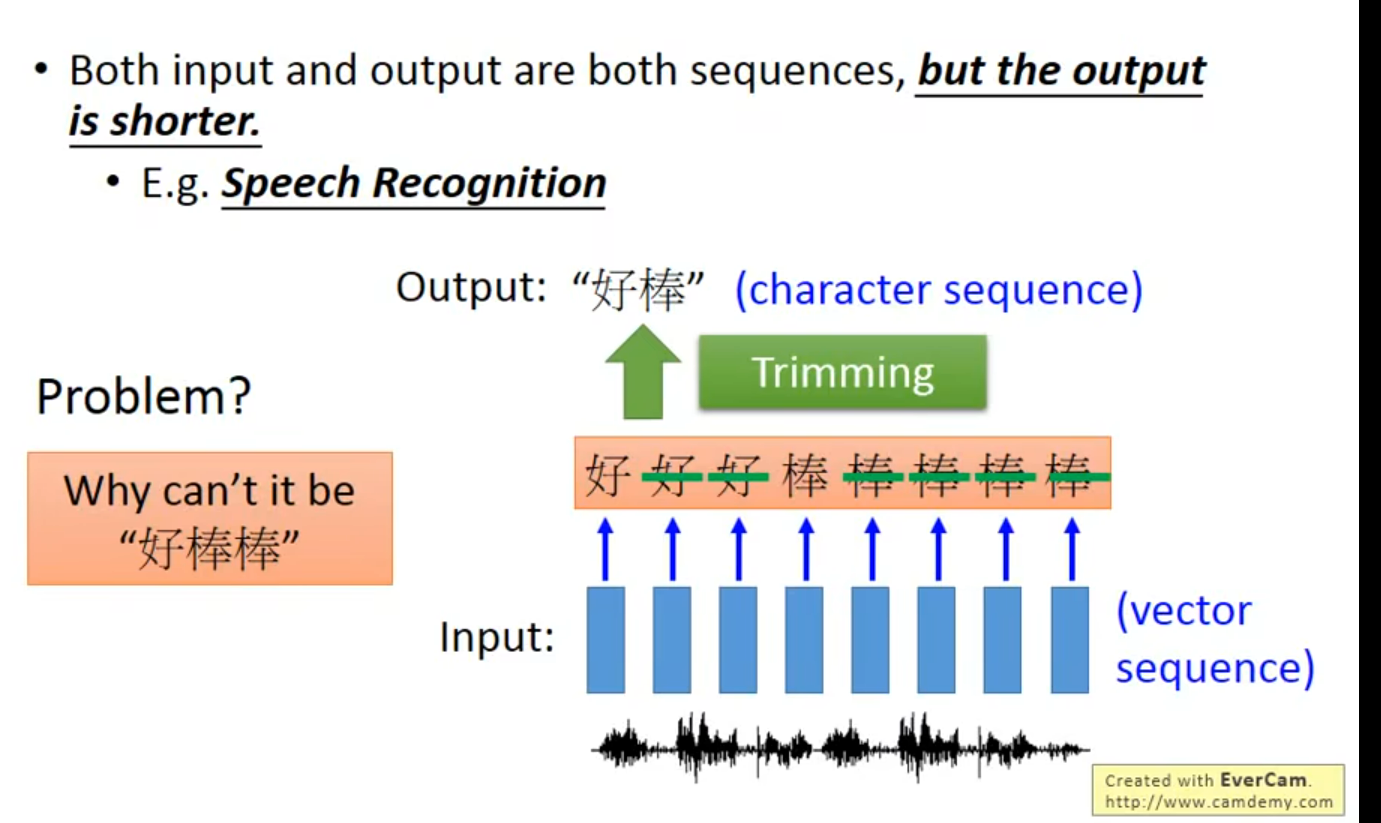
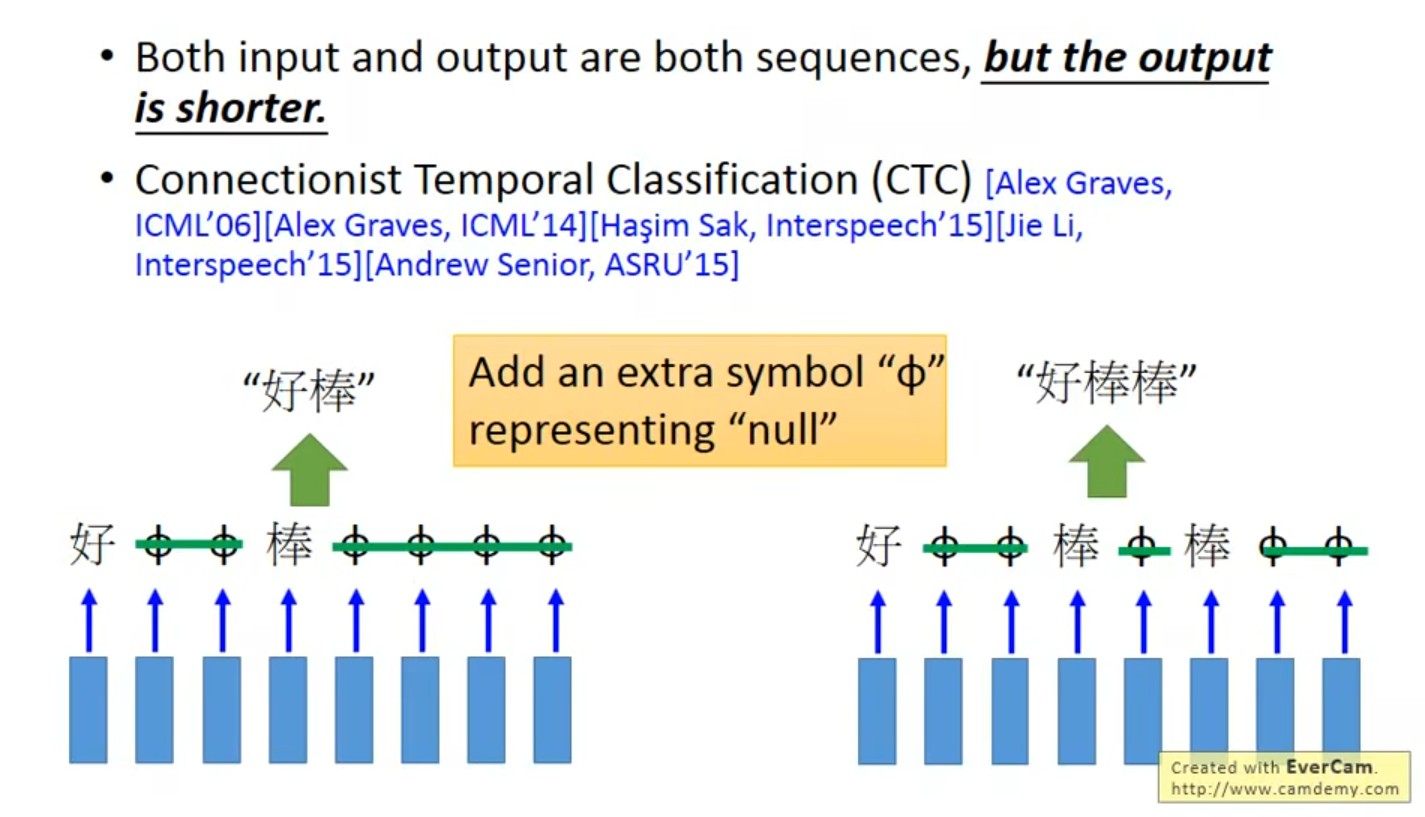
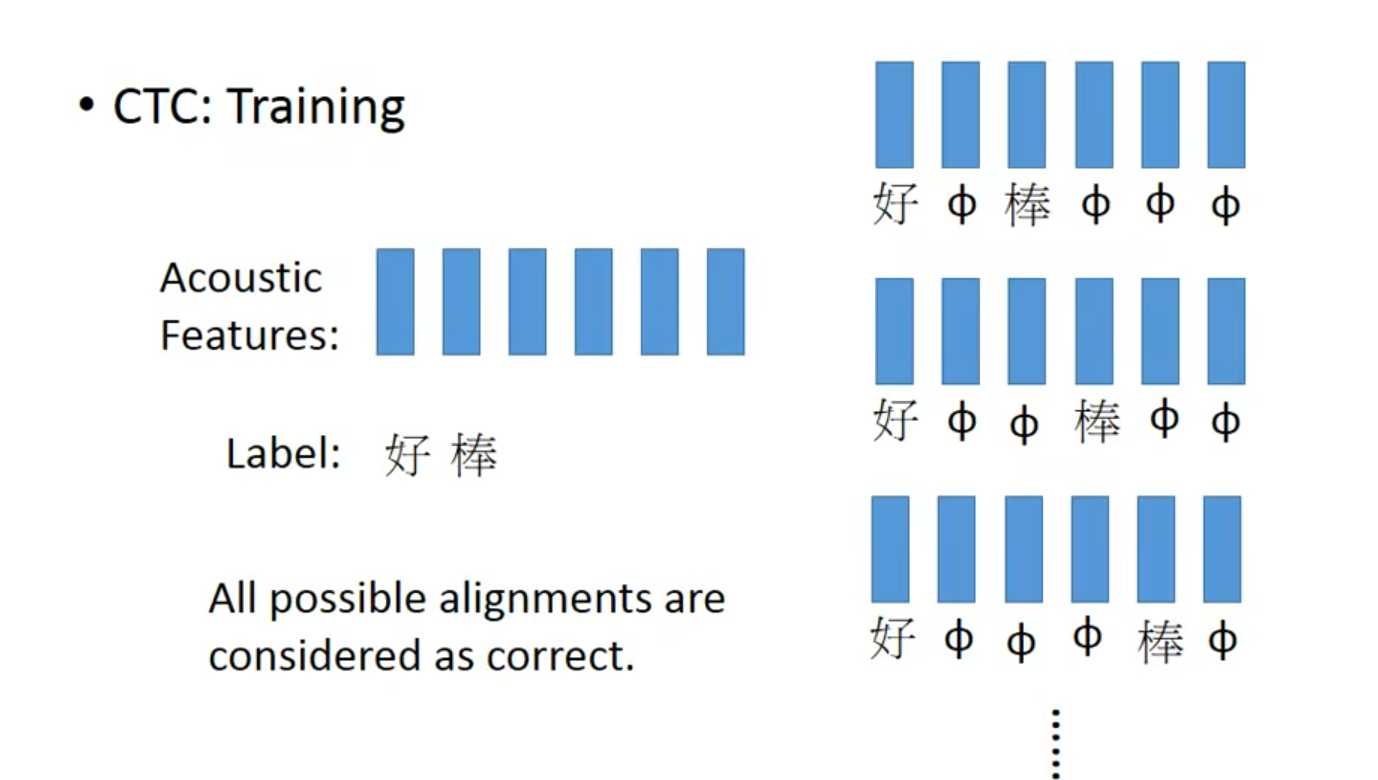
有一个好的穷举算法
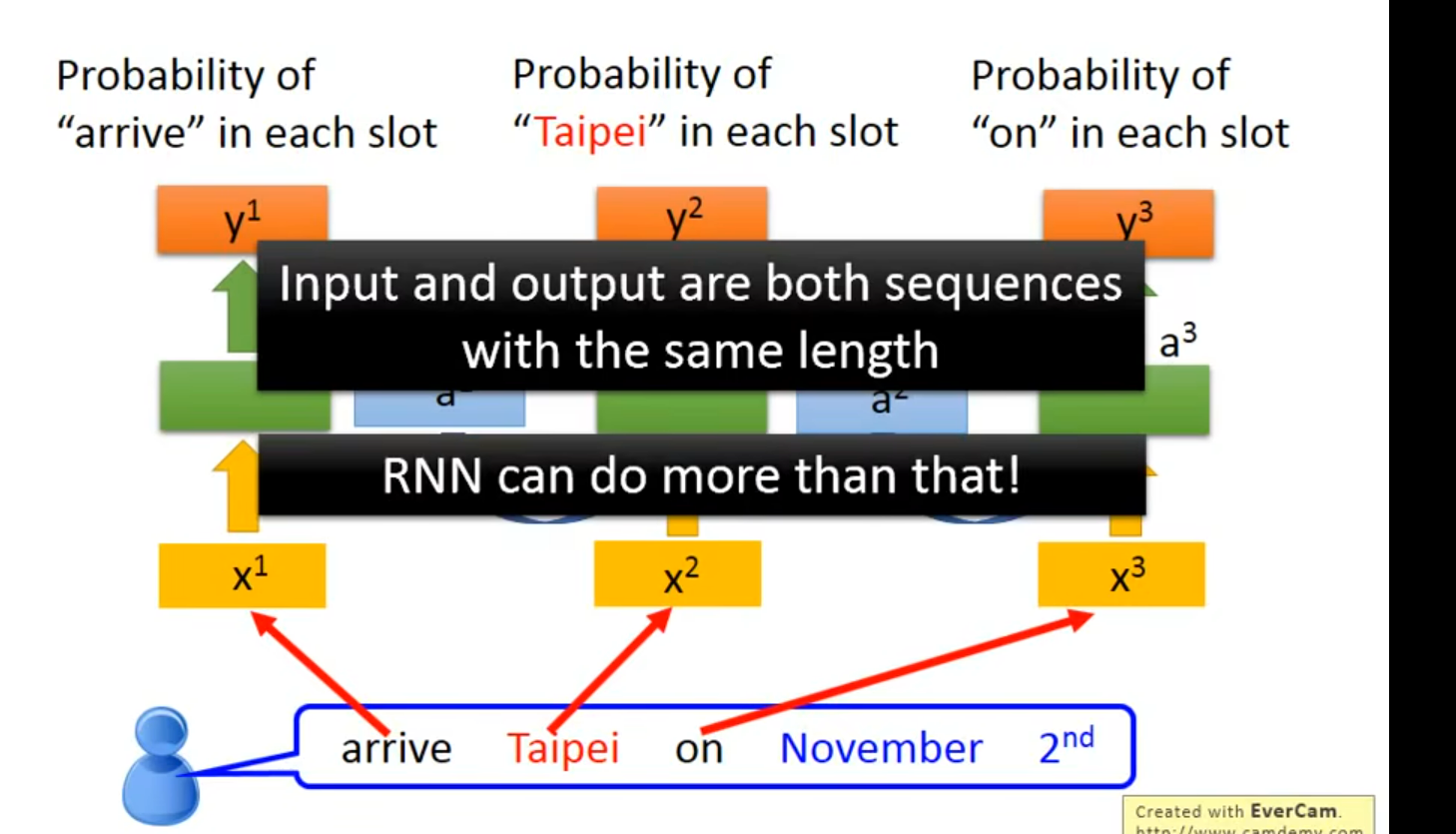
多到多(no LImitation)
翻译
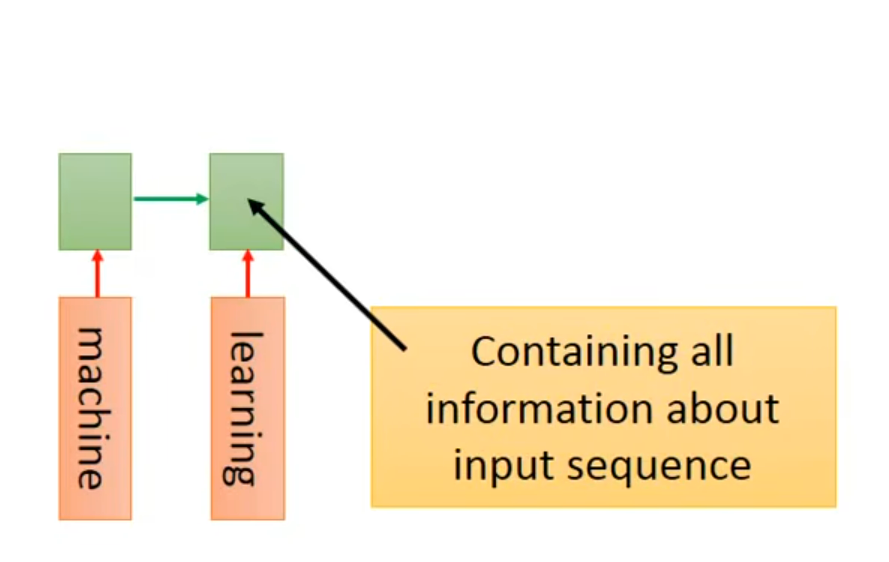
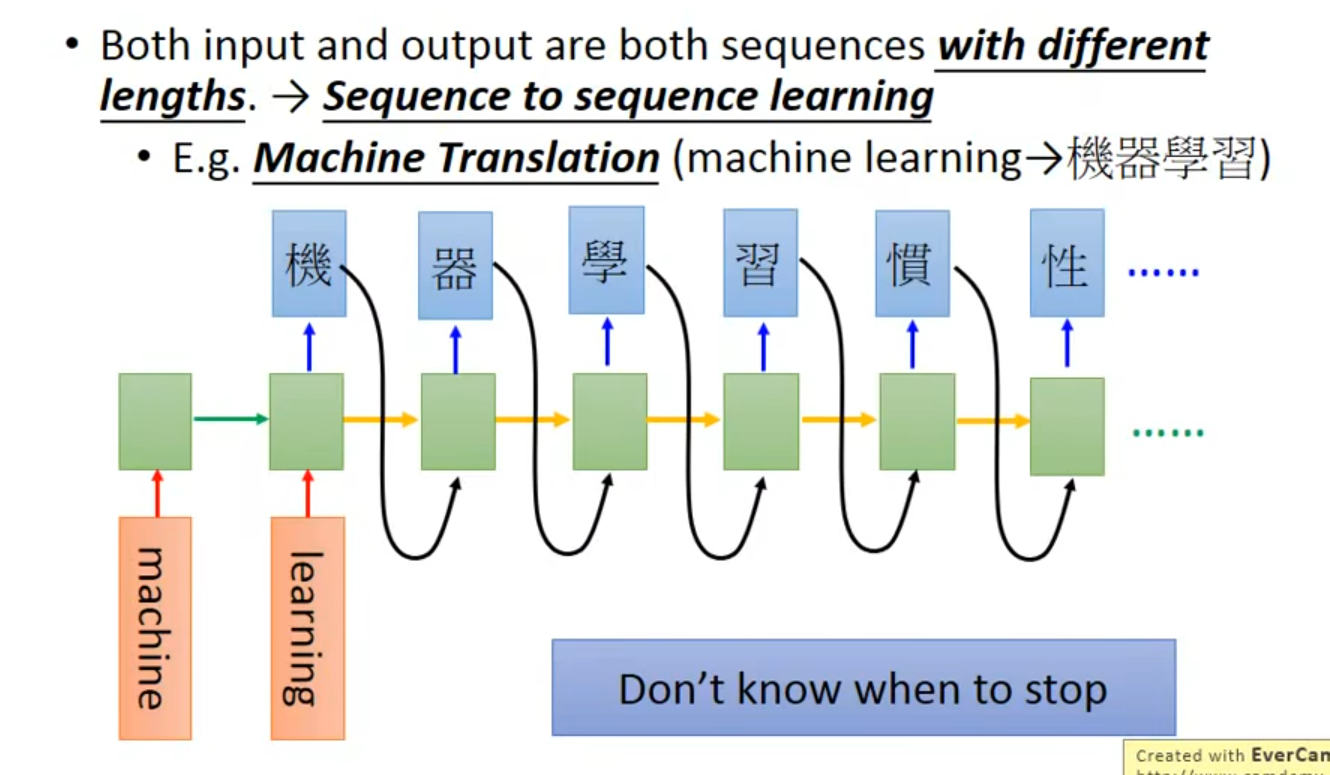
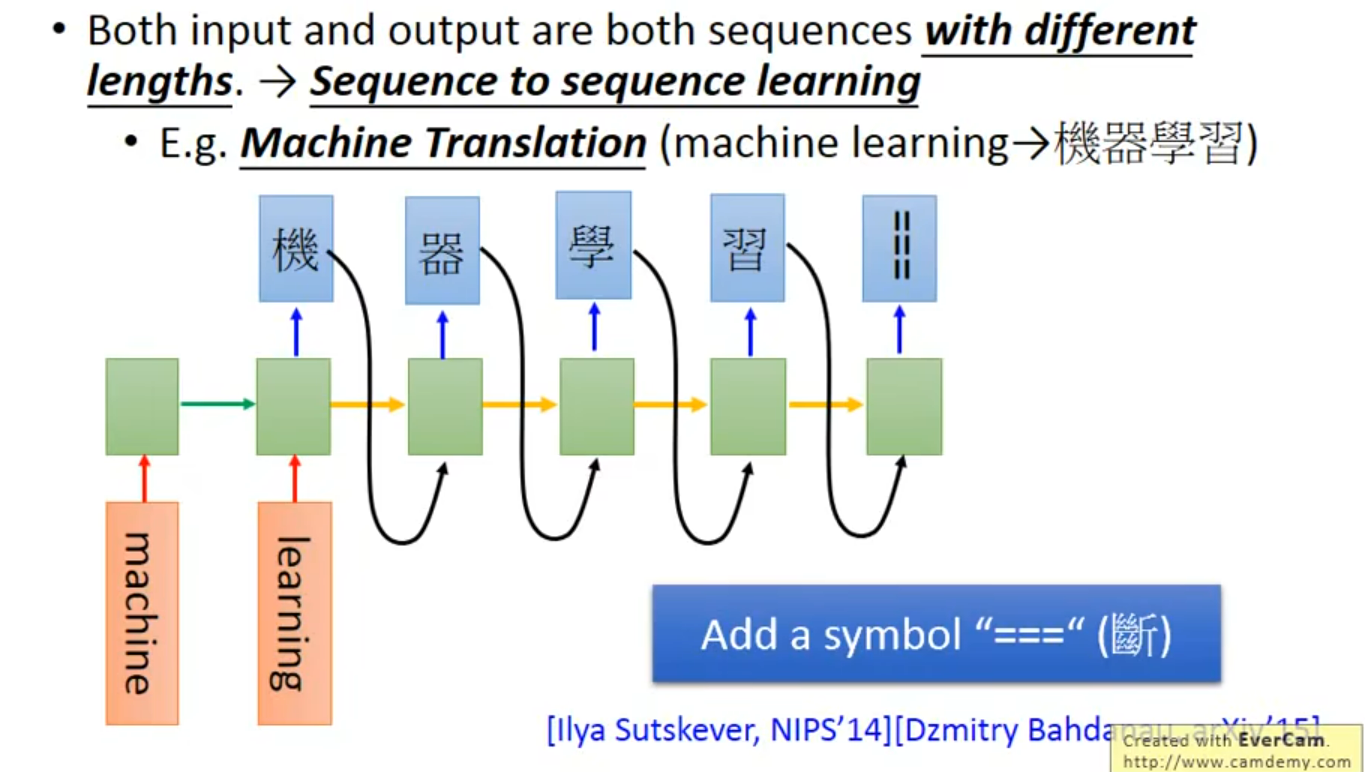
????没看懂这里,这个断是在哪里加入呢;假设在训练过程中添加了这个symbol

不仅仅 是sequence
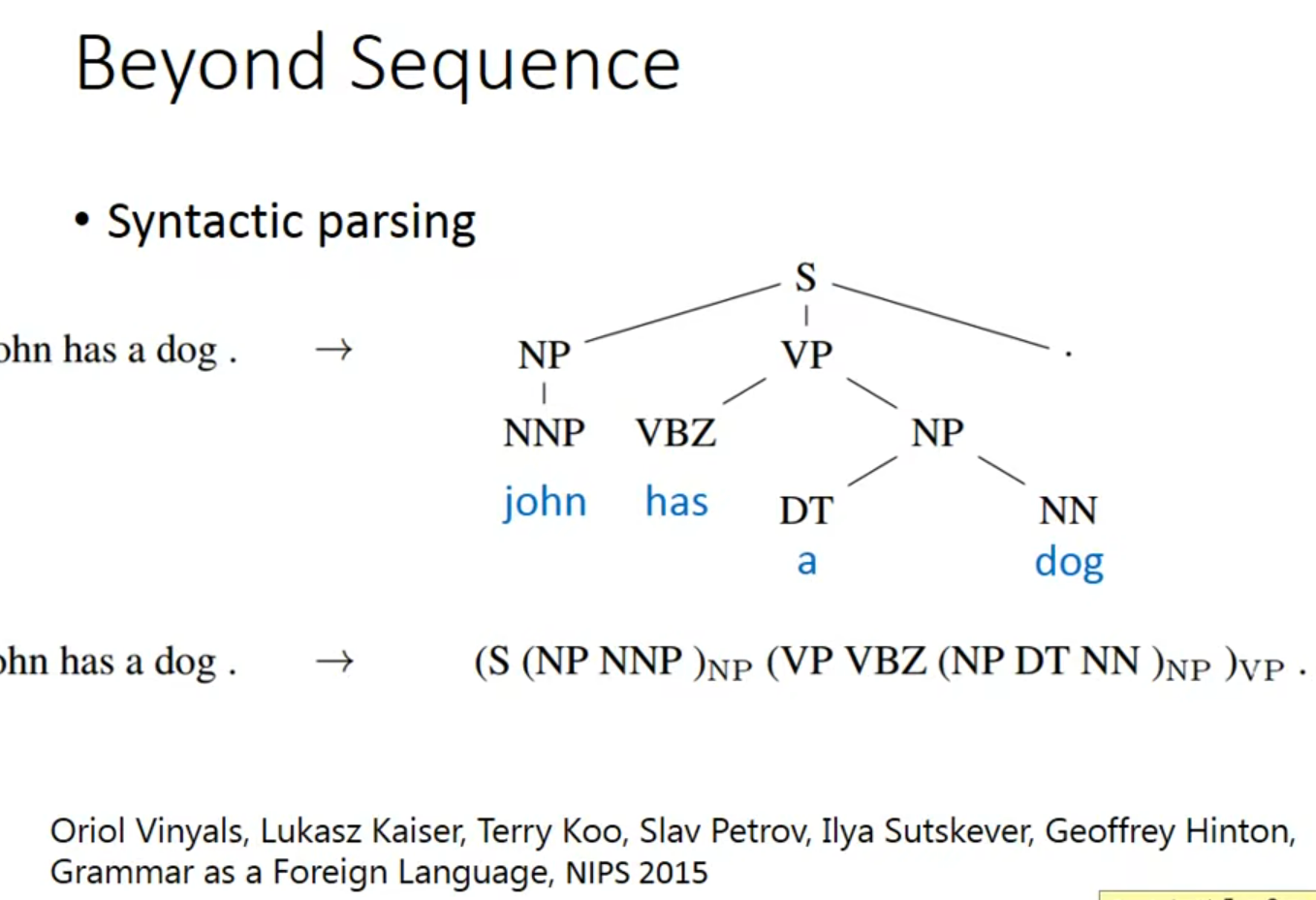
使用LSTM做句法解析时,如果输入句子有语法错误,如缺少括号,这种错误通常不会直接影响LSTM模型的解析过程,因为LSTM并不是基于规则的解析器,而是基于学习的模型。它通过从大量的标注数据中学习语言的统计特征,来预测句子的结构
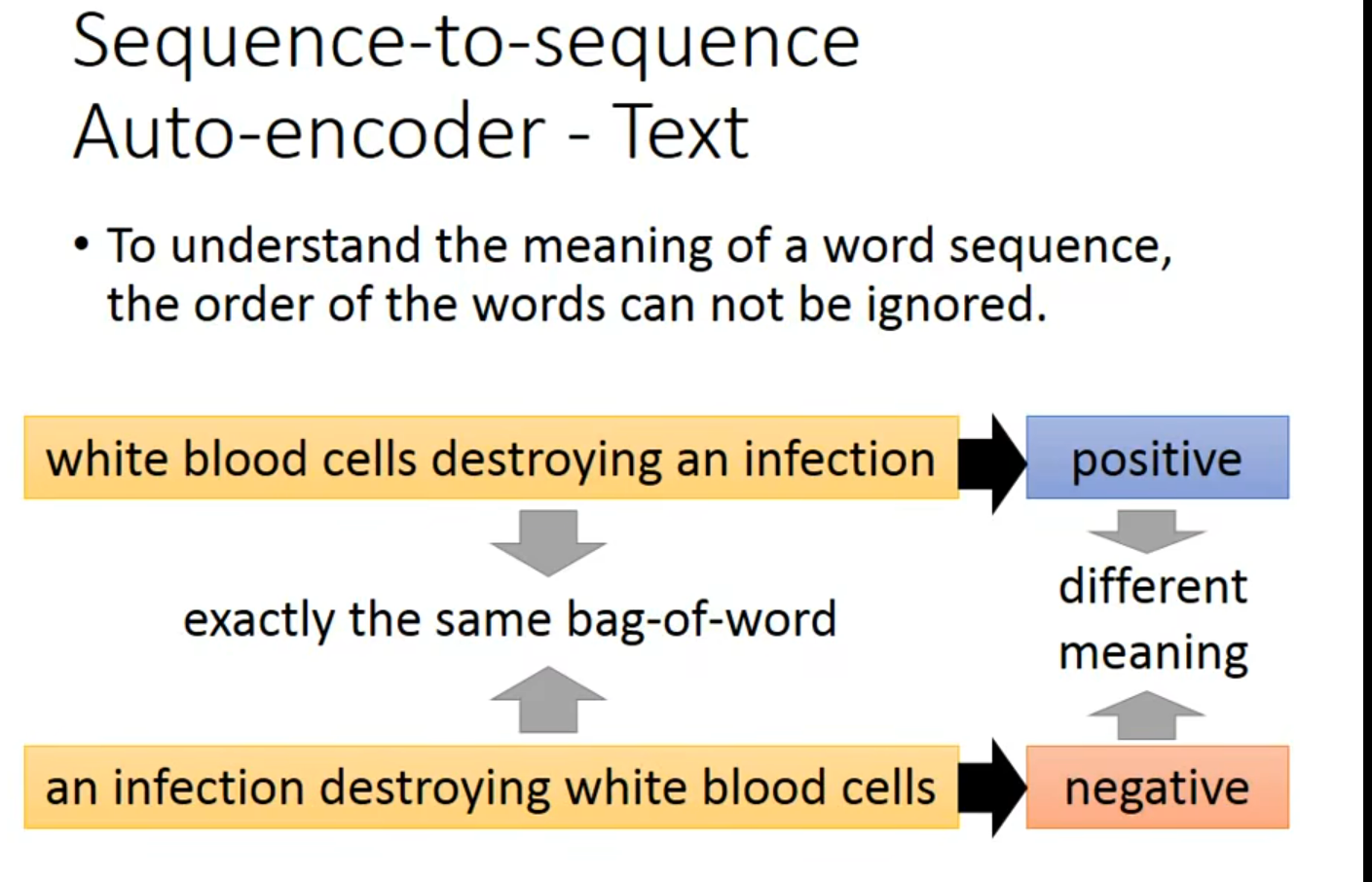
什么是词袋模型?
词袋模型(Bag of Words,简称BOW)是一种常见的文本表示方法,用于自然语言处理和信息检索领域。这种模型忽略了文本中词语的顺序和语法、句法元素,仅仅将文本(如一句话或一篇文章)转换为一个集合,其中包括了词汇表中每个词的出现次数。可以将其想象为一个词的“袋子”,只记录词的存在与频率,而不考虑其出现的顺序。
词袋模型的步骤通常包括:
- 分词:将文本分割成词语或标记。
- 构建词汇表:从所有文本数据中提取出不同的词语,构成一个词汇表。
- 计数:对于每一个文本,计算词汇表中的词语在该文本中出现的次数。
可以把一个document 变成一个 vector
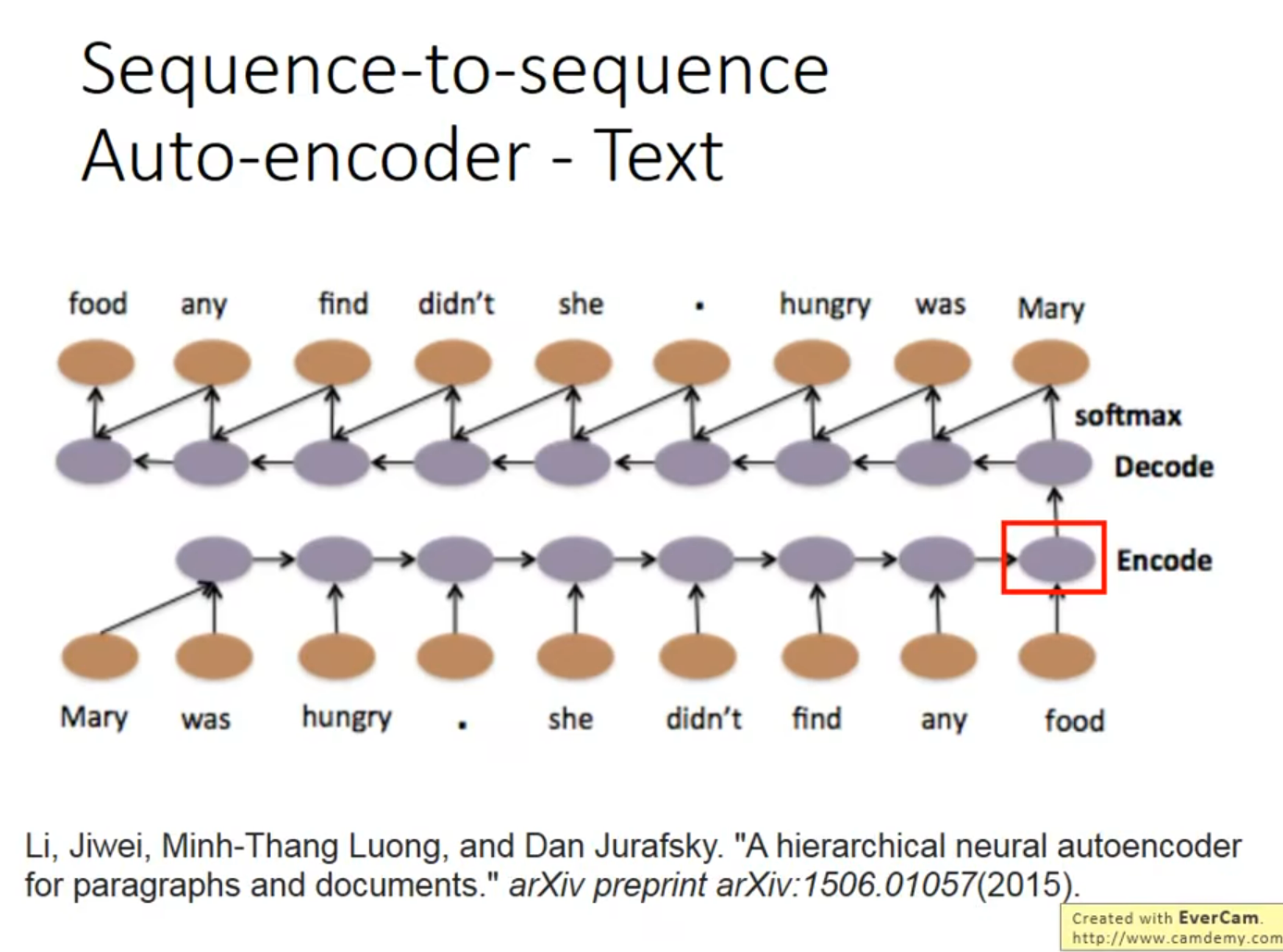
这个听不懂,让gpt试试
《A Hierarchical Neural Autoencoder for Paragraphs and Documents》探讨了如何利用长短期记忆网络(LSTM)自编码器生成长文本。核心思想是通过建立层级LSTM模型,将文本(如段落或文档)编码成向量,然后再解码重构原文本。这种层级模型能在不同层次上捕捉文本的组合性,如单词间、句子间的关系,从而在重构时保持文本的语义、句法和篇章的连贯性。实验表明,这种模型能有效重构输入文档,并且在维持原文结构顺序方面表现良好。
层级LSTM(Hierarchical LSTM)模型通过构建不同层级的LSTM结构来处理文本数据,其中每个层级对应文本的不同组成部分(如词、句子和段落)。在编码阶段,每个词首先通过词级LSTM(LSTM_word_encode)转换为词向量,这些词向量再通过句子级LSTM(LSTM_sentence_encode)组合成句子表示。同理,所有句子表示再通过一个更高层级的LSTM转换为整个文档或段落的表示。解码阶段与此类似,但过程是逆向的,从文档表示开始逐步解码出句子和词。这种层次化方法有助于模型捕捉文本数据的内在结构和复杂性。
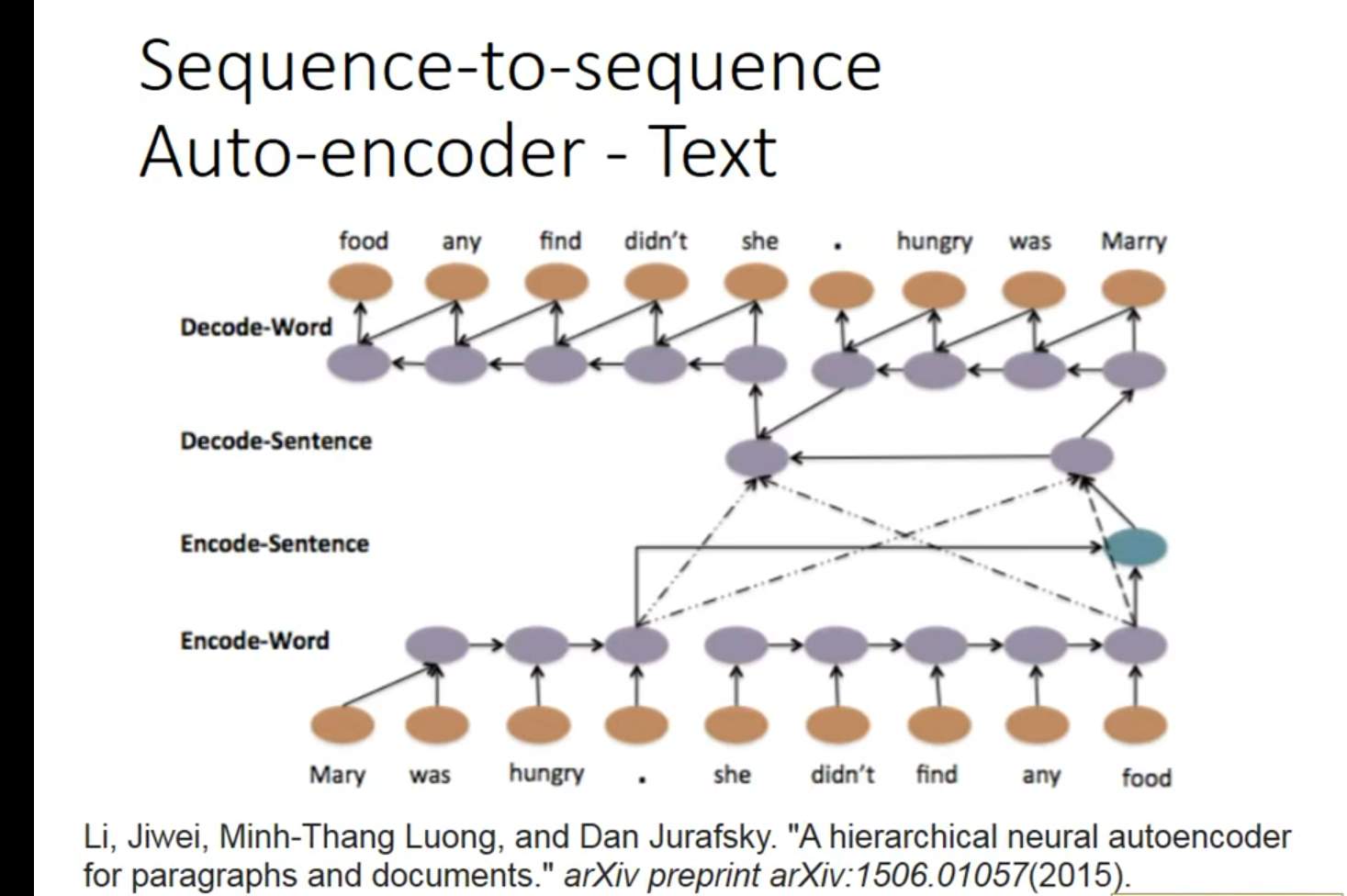
词语 – 句子 - 文档 反解回;
感觉这个可以拿来试试做论文翻译
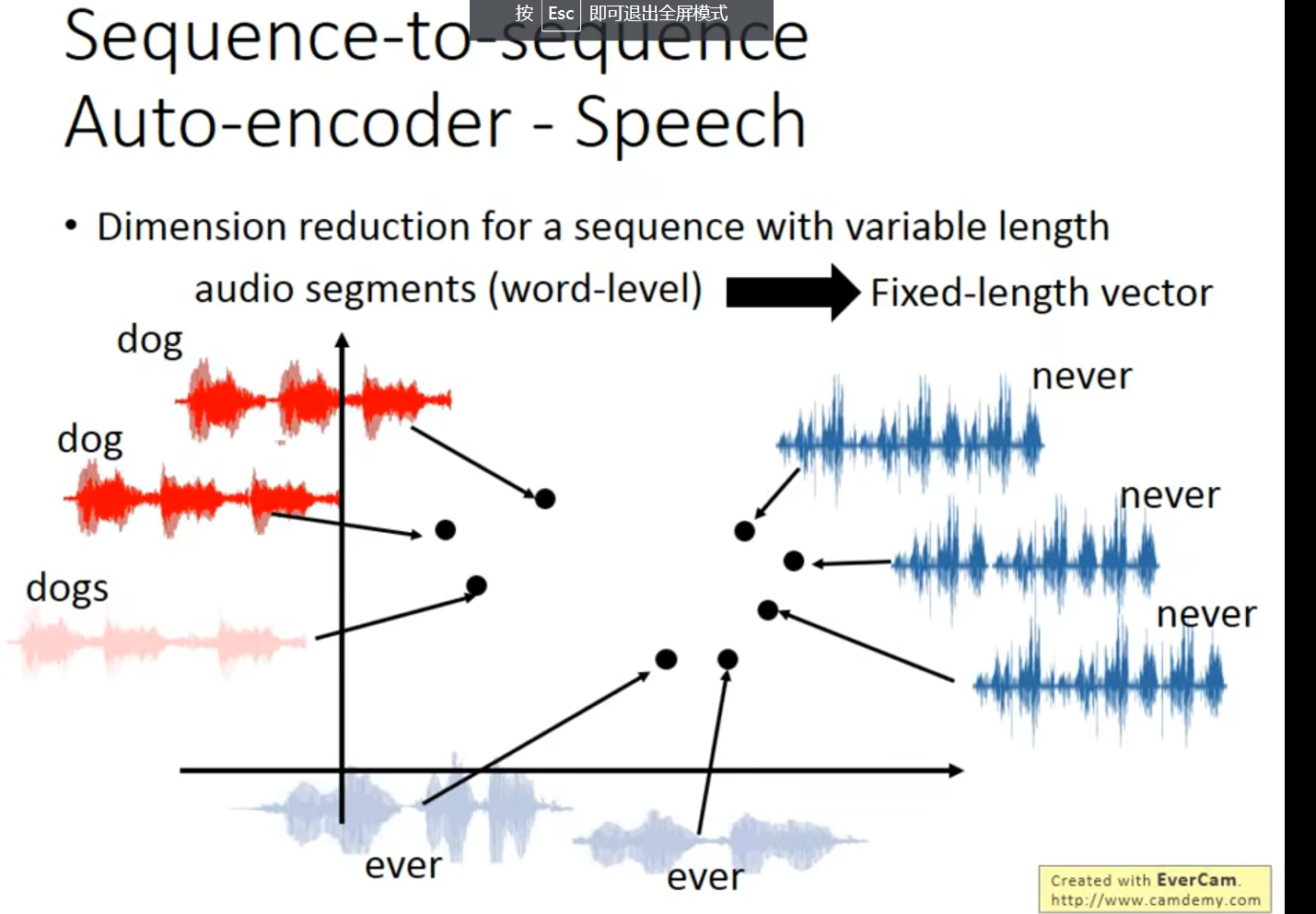
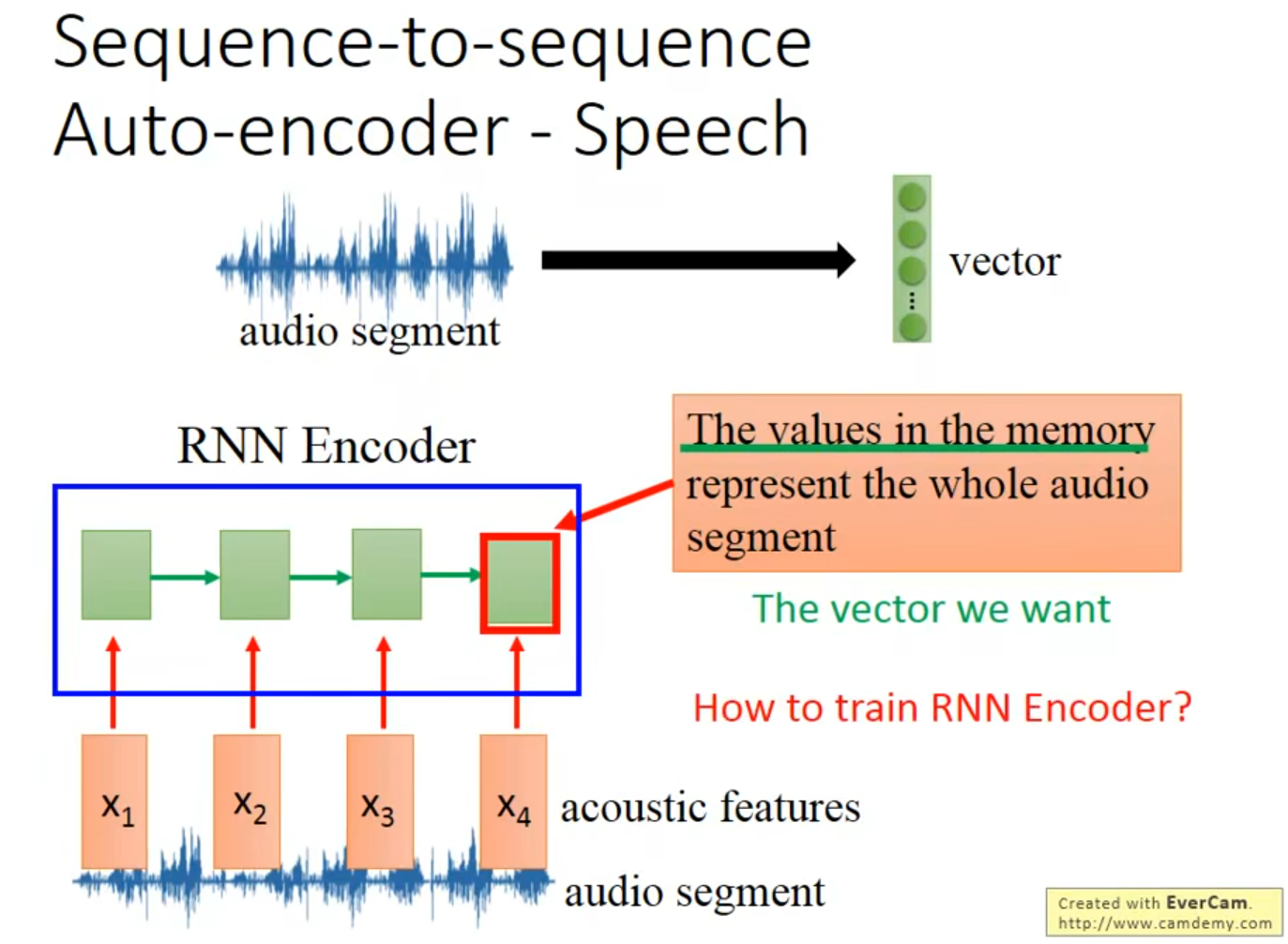
如果能处理视频就好了,这样监控就再也不用人去看了