一、题目描述
(一) 题目
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。你应当保留两个分区中每个节点的初始相对位置。
(二) 示例
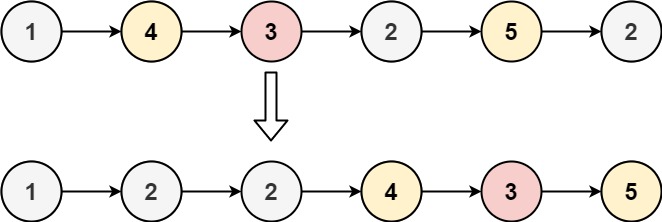
示例 1:
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1,2]
(三) 提示
- 链表中节点的数目在范围
[0, 200]内 -100 <= Node.val <= 100-200 <= x <= 200
二、代码实现
(一) 迭代
1. 解题思路
这个题不是很难,只要理解题意加上构造两个子链即可完成,链表而不是数组,构建子链不增加空间复杂度。勇敢地构造子链,无需考虑节点交换。
图解如下:
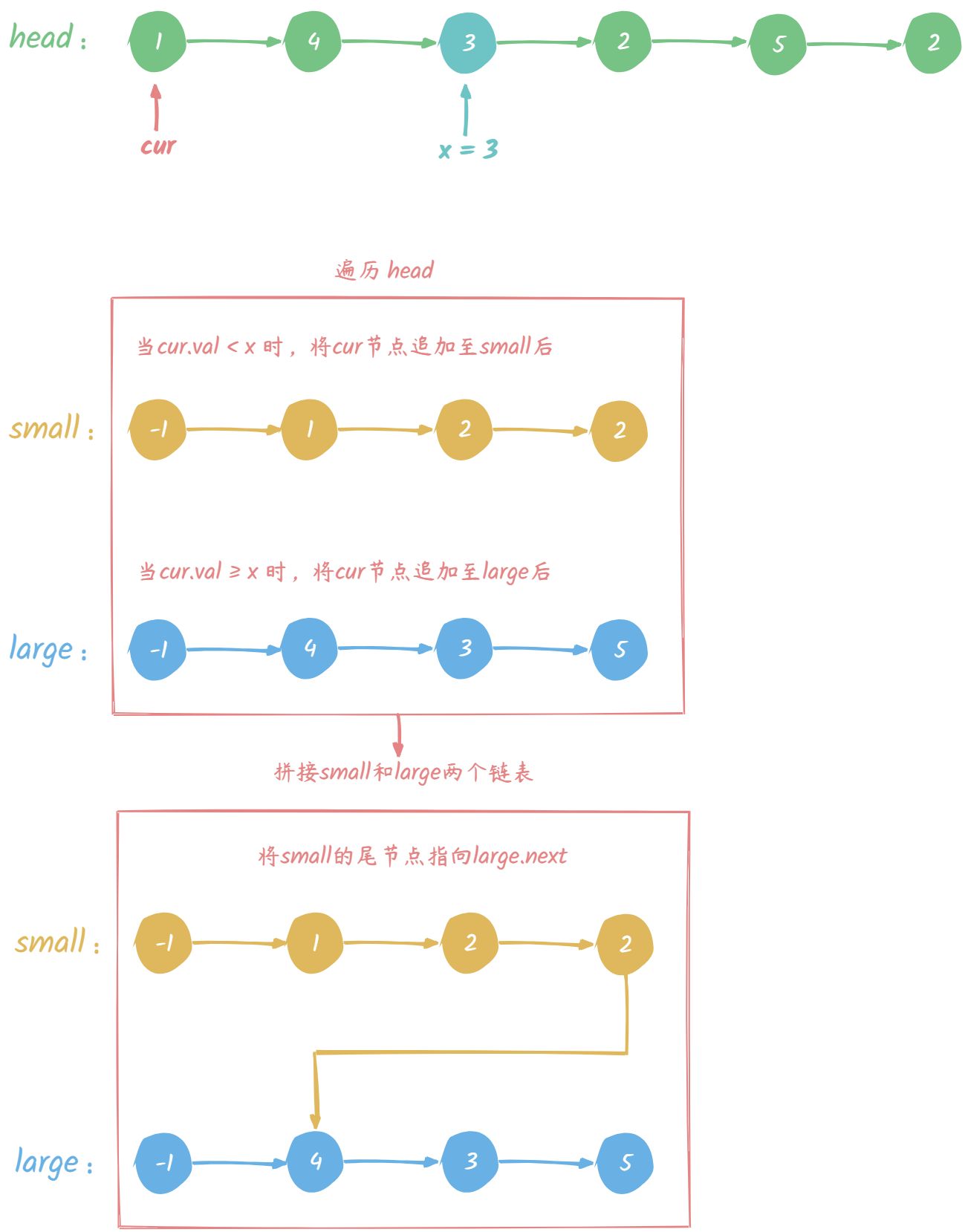
通过图解,可以了解迭代的大致流程,但是我们在 Java 代码实现时,还需要维护两个对应的指针,用来调整它的 next 指针。
为什么需要这个指针而不是直接使用构造的节点呢?原因是我们在不断的遍历中,指针会不断的下移,当我们合并完成所有的节点时,此时的指针是在最后,这时我们在获取合并后的链表就比较麻烦了。
而用指针代替节点去进行 next 指针的移动,当返回链表时,只需返回节点的 next 即可。
为什么指针节点增加后,节点链表也会变动呢?这涉及到引用问题,这里直接引用拷贝的是堆中的内存地址,也就是说指针和对应节点就是一个对象。
还有一个注意事项,遍历结束后,我们将 large 的 next 指针置空,这是因为当前节点复用的是原链表的节点,而其 next 指针可能指向一个小于 x 的节点,我们需要切断这个引用,否则可能会出现环链表。
代码实现如下:
class Solution {public ListNode partition(ListNode head, int x) {//构造两个子链表ListNode small = new ListNode(-1);ListNode large = new ListNode(-1);//构造子链表对应的指针,方便ListNode smallPointer = small;ListNode largePointer = large;while(head != null){if(head.val < x){smallPointer.next = head; //追加节点smallPointer = smallPointer.next; //指针后移}else{largePointer.next = head; //追加节点largePointer = largePointer.next; //指针后移}head = head.next; //指针后移}//当前节点复用的是原链表的节点,很可能后面还指向一个小于x的节点largePointer.next = null; smallPointer.next = large.next; //链表拼接return small.next;}
}2. 复杂度分析
| 时间复杂度 | |
| 空间复杂度 | O(1),定义的变量使用的常数大小空间。 |






