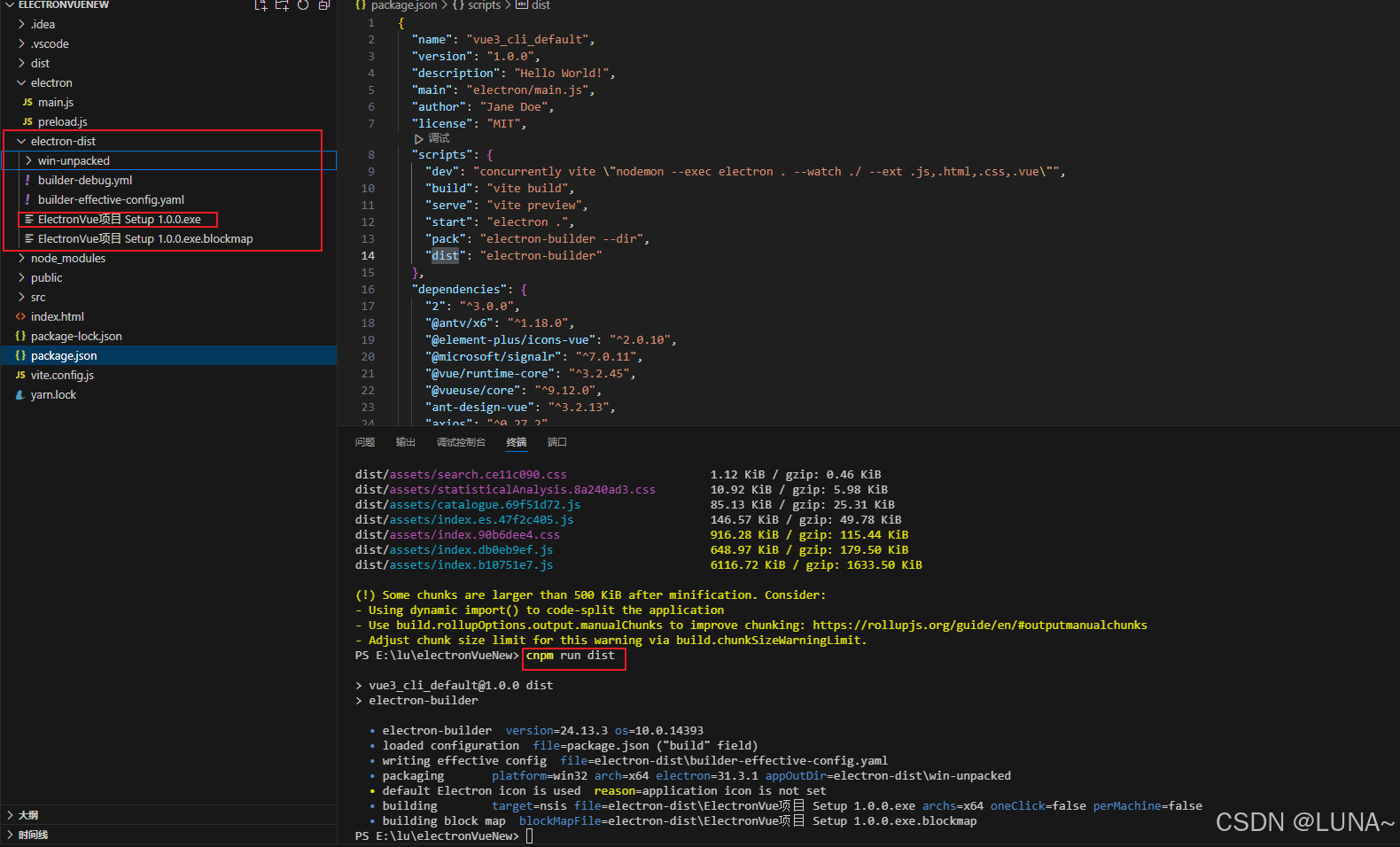
在这篇博客中,我们将通过一个实际的Python爬虫项目,详细讲解如何抓取网页数据。本次选择的实战项目是抓取天猫超市商品信息,通过这个项目,你将学会如何使用Python编写爬虫,从网页中提取有用的商品数据。
一、项目准备
在开始之前,确保你已经安装了Python和以下几个关键的库:
- requests:用于发送HTTP请求和获取网页内容。
- Beautiful Soup:用于解析HTML内容,提取数据。
- pandas:用于数据处理和分析。
你可以通过以下命令安装这些库:
pip install requests beautifulsoup4 pandas二、项目步骤
-
分析网页结构
首先,我们需要打开天猫超市的网页,并分析其HTML结构,找出我们需要抓取的商品信息的位置和标签。
-
发送HTTP请求
使用
requests库发送GET请求,获取网页的HTML内容。import requestsurl = 'https://chaoshi.tmall.com/' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' } response = requests.get(url, headers=headers) -
解析网页内容
使用
Beautiful Soup库解析HTML内容,提取商品的信息。from bs4 import BeautifulSoupsoup = BeautifulSoup(response.text, 'html.parser')# 通过分析HTML结构,找出商品信息所在的标签和类名 product_list = soup.find_all('div', class_='product') -
提取数据
遍历解析后的网页内容,提取商品的名称、价格等信息,并存储到列表或字典中。
products_data = [] for product in product_list:name = product.find('p', class_='productTitle').text.strip()price = product.find('p', class_='productPrice').text.strip()products_data.append({'name': name,'price': price}) -
数据处理与存储
最后,可以将提取到的商品数据存储到CSV文件或者数据库中,或者进行进一步的数据分析和处理。
import pandas as pddf = pd.DataFrame(products_data) df.to_csv('tmall_products.csv', index=False, encoding='utf-8')
三、总结
通过这个项目,我们学习了如何使用Python编写简单的网页爬虫,从天猫超市抓取商品信息。在实际项目中,你可以根据需求扩展功能,例如加入数据存储、异常处理、反爬虫机制等。同时,务必遵守网站的使用规则和法律法规,爬取数据时要尊重网站的服务协议。