大家好,我是苍何。
人一辈子最值得炫耀的不应该是你的财富有多少(虽然这话说得有点违心,呵呵),而是你的学习能力。技术更新迭代的速度非常快,那作为程序员,我们就应该拥有一颗拥抱变化的心,积极地跟进。
在学习 RocketMQ 的消息存储之前,我们已经学习了 topic 主题、消息模型、消息的过滤和重试等知识点。
这让我感觉自己富有极客精神,非常良好。

小伙伴们在继续阅读之前,我必须要声明一点,为一名负责任的技术博主,我是动了心的,这篇教程,小伙伴们读完后绝对会感到满意,忍不住无情地点赞,以及赤裸裸地转发。
当然了,小伙伴们遇到文章中有错误的地方,不要手下留情,可以组团过来捶我,但要保证一点,不要打脸,我怕毁容。
我们都知道,消息队列一大核心功能是削峰填谷,也就是在大流量场景下(比如 12306 春运购票),将部分业务逻辑放在 MQ,等其慢慢处理,且给用户友好提示:
“您已加入候补队列,请耐心等待!”
在 MQ 中的消息,可以有条不紊的、均匀的消费,但需要保证消息存储的可靠性。
不可能我加入候补半天,让我等,我等了 2 天,然后提示我压根没加入候补,这不是坑人吗?
所以,我们需要动员脑子里所有脑细胞,仔细思考下,MQ 中的 broker 该如何存储消息才能防止消息丢失呢?
消息可以存 MySQL 吗
要防止数据不会在持久化的时候消失,很多的做法都是将数据库直接存在 MySQL,比如 Nacos 持久化、Redis 持久化。
那 RocketMQ 可以把消息存储在 MySQL 吗?
单纯从持久化来看,没问题,但消息可不单单是做持久化,需要满足削峰填谷需求,MySQL 性能就无法满足了。
如果 MySQL 可以,那我干嘛费老半天劲把消息丢到 MQ 呢?我直接丢 MySQL 处理不就得了?
这时估计 MySQL 他老人家也会想"合着折腾半天,最后又回到我这了是吧?"
消息可以存 Redis 吗
这个时候你聪明的脑袋瓜肯定灵机一动,那要想追求高性能,存 Redis 啊,Redis 贼快,而且还可以持久化,这下可以了吧?
Redis 就像是个 mini 冰箱,虽然取东西快,但空间有限。RocketMQ可是要处理海量消息的"大胃王",用硬盘这个"大冷库"才够塞。
Redis 虽然也能持久化,但更像是给冰箱拍照。RocketMQ 需要的是 365 天 24 小时不间断运转的"冷库"级别持久化。
处于性能的考虑,Redis 读写虽然很快,毕竟还是操作内存,但要在内存和磁盘间倒腾数据就慢了。

还有一个核心问题是,如果真是把消息放 Redis 了,那又引入了第三方组件,合着,我想用个 RocketMQ,你还得硬要我搞个 Redis。Redis 要宕了,RocketMQ 也嗝屁了。
软件工程,不是越复杂越好,和生活一样,往往大道至简的东西才更优雅,故而 RocketMQ 是绝对不可能吧消息丢给 Redis 的。
消息存哪里
这时,你肯定会没耐心的对苍何想要拳打脚踢,说这么半天,那消息到底存在哪儿?
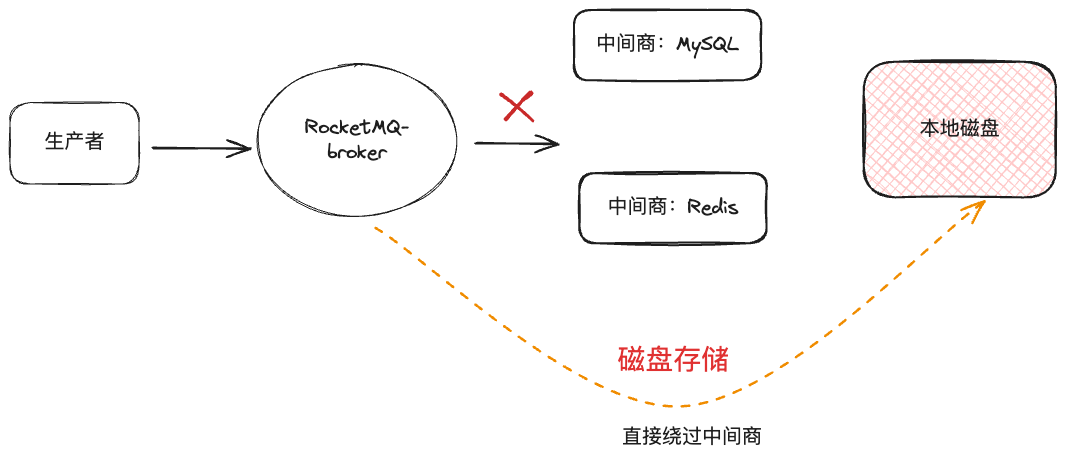
先说结论:消息存本地磁盘。
是不是简单粗暴?反正最后不管是 MySQL 还是 Redis,持久化都要存磁盘,那我直接绕过中间商,不更优雅吗?
问题很多的小明又问了,磁盘也不可靠啊,不是照样会损坏?
但现在服务器上都要做 RAID,有备份在,那如果服务器直接被炸了呢?(虽然这种概率很小)
那还可以多云融合(就是多个云服务器备份),异地容灾等,这里就不展开了,总之,道高一尺,魔高一丈。
极致的可靠是不存在的,我们只能在我们能想到的合理范围内做到可靠,这就是互联网。
你可能会问,存到磁盘上,那是如何存储的呢?
假如有很多个 topic,每个 topic 又有很多个队列,是每个 topic 一个文件?还是每个队列一个文件?
commitlog
为了保证 RocketMQ 的写性能,最好是将所有消息都放在一个文件,并顺序读、顺序写。
如果不放在一个文件,硬盘的存储物理位置就不是连续的,能无法保证顺序写,这个时候写入后的物理位置其实就是随机的了。
顺序读写也是为了追求极致的性能,这个其实和 MySQL 的 redo log 有异曲同工之妙。
而这个存储消息的本地文件,就叫做 commitlog。位于 rocketmq/data 文件夹下面。
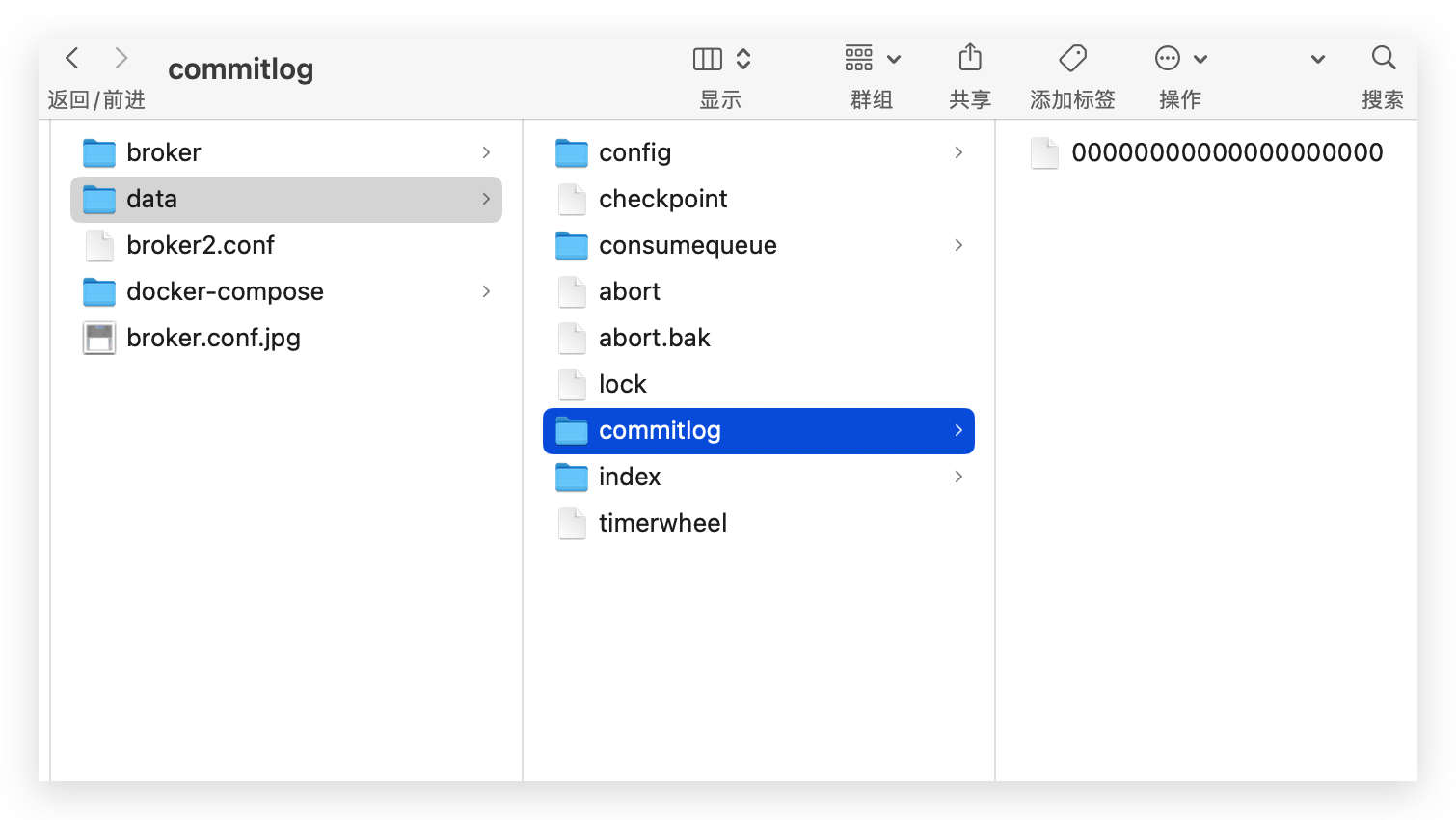
当你用你粗壮的手准备打开这个文件时,发现是个二进制文件。
这也很好理解,使用二进制存储,一来节省存储空间,二来也能提高读取性能。
要想打开读取这文件,可以借助 RocketMQ 自带的 mqadmin 来读取,比如:
# 使用rocketmq-tools查看消息
sh mqadmin queryMessageByKey -n <namesrvAddr> -t <topic> -k <messageKey>
当然也可以使用开源工具如 rocketmq-dump 来查看,小伙伴们可以亲自试试。
consumequeue
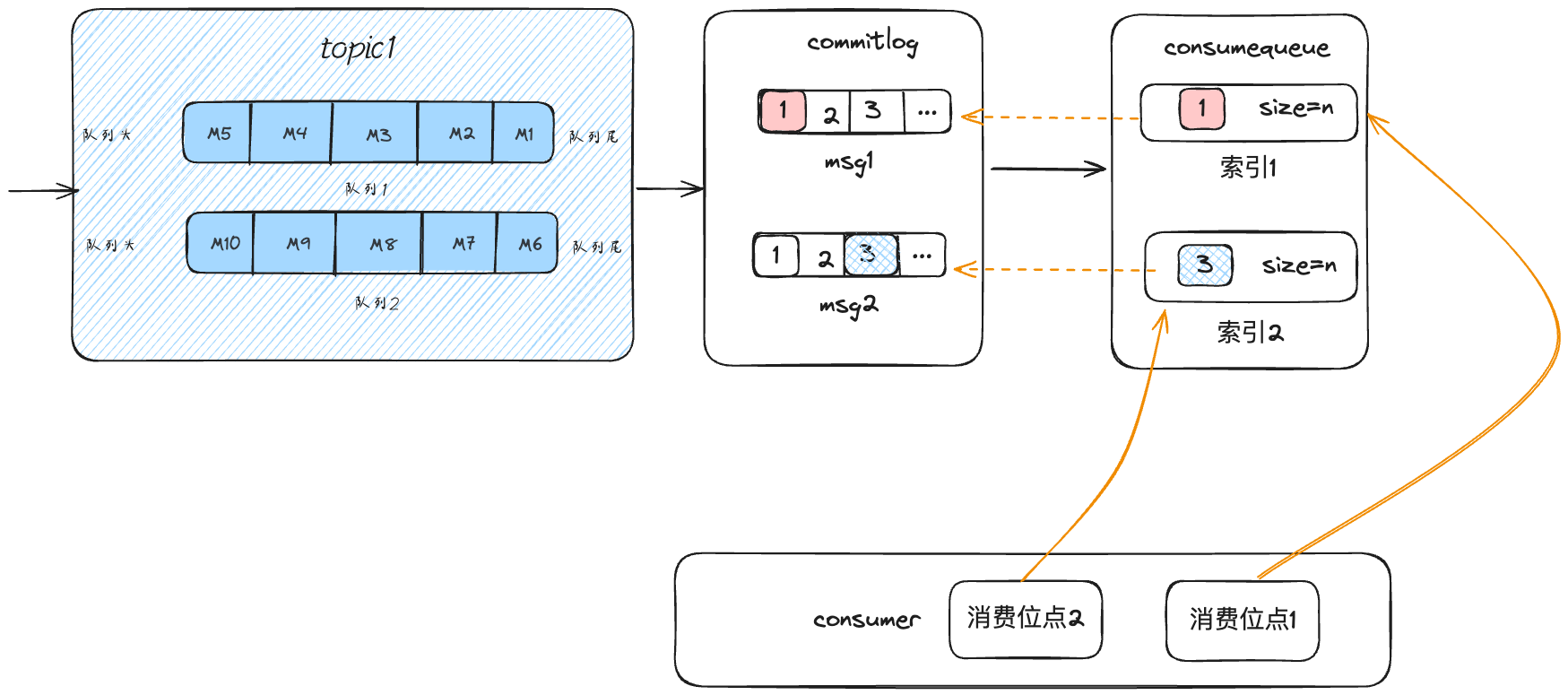
细心的小伙伴可能已经注意到除了 commitlog 还有一个文件 consumequeue,那这里面存的是啥子呢?
我们知道 commitlog 存的是消息的全量数据,那对于消费者来说,想要知道自己该消费哪条消息,我们在之前的文章中分析过,靠的是消费位点(comsumerOffset),也就是消息的记录。
这个 comsumerOffset 也是会落在磁盘持久化的。
commitlog 里面只有一个文件,里面存的是消息的全量信息,为了追求极致的性能体验,肯定是需要索引来进行查询。
consumequeue 存放的是起始偏移量和长度,相当于这个索引。
通过起始偏移量和长度可以查询 commitlog 中的全量消息信息。
为什么这么做呢?
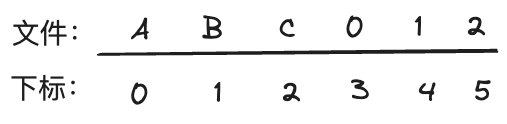
假设 commitlog 存了 2 条消息,分别是 ABC、012,那对应的文件内容是 ABC012,每个字节会对应一个下标,比如:
A:0
B:1
我们要想读到 ABC 这条消息,只需要知道起始的 A 对应的下标,以及消息的长度就可以拿到这条消息了。这个下标其实就是偏移量。
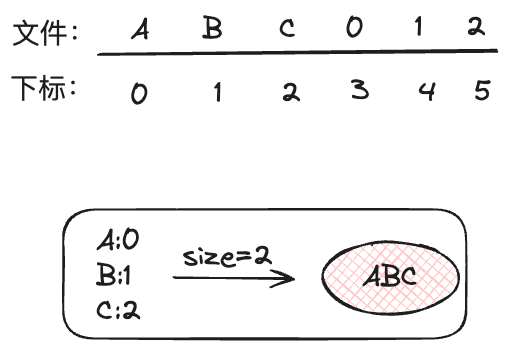
所以 consumequeue 中存的就是消息的起始偏移量和长度。
那么现在我们来梳理下消息存储的流程吧:
RocketMQ 先将消息存到 commitlog,然后通过定时任务把消息的起始偏移量和长度存到 consumequeue,然后根据这两个数据定位到消息,在 consumequeue 其实就已经按照 topic 和队列分好了,查找起来也是相当快的。
消费者消费消息的时候,通过消费位点找到 consumequeue 里面的起始偏移量和长度,通过索引找到 commitlog 对应的全量消息,然后再消费。
消息索引
细心的小伙伴可能会注意到通过起始偏移量和长度来定位消息,着实有些慢,并不能快速查找到消息。
RocketMQ 提供了消息索引机制。5. x 中是位于 index 文件夹中,存放的就是索引信息。(这个索引更快👍)
索引的内部通过数据槽来实现,感兴趣的小伙伴可以去了解下内部实现原理。
通常我们会将业务唯一 id 设置为索引,比如订单号,查询订单号就能立刻查询出当前订单的消息。
那么如何添加索引呢?
发送消息的时候,可以添加索引:
Message msg = new Message("TopicTest", "TagA", "Hello RocketMQ".getBytes());
msg.setKeys("yourKey");
broker 配置中需要做下设置:
messageIndexEnable=true
messageIndexSafe=false
最后
不得不说,一个优秀的中间件,往往会有很多精妙的设计,RocketMQ 的消息存储机制的设计就堪称完美。
当然,还有更多的细节,比如 commitlog 的加载流程、索引的存储结构,这些大家感兴趣的可以自行查阅资料哈。
好啦,今天的分享结束。
我是苍何,这是图解 RocketMQ 教程的第 8 篇,我们下篇见~




