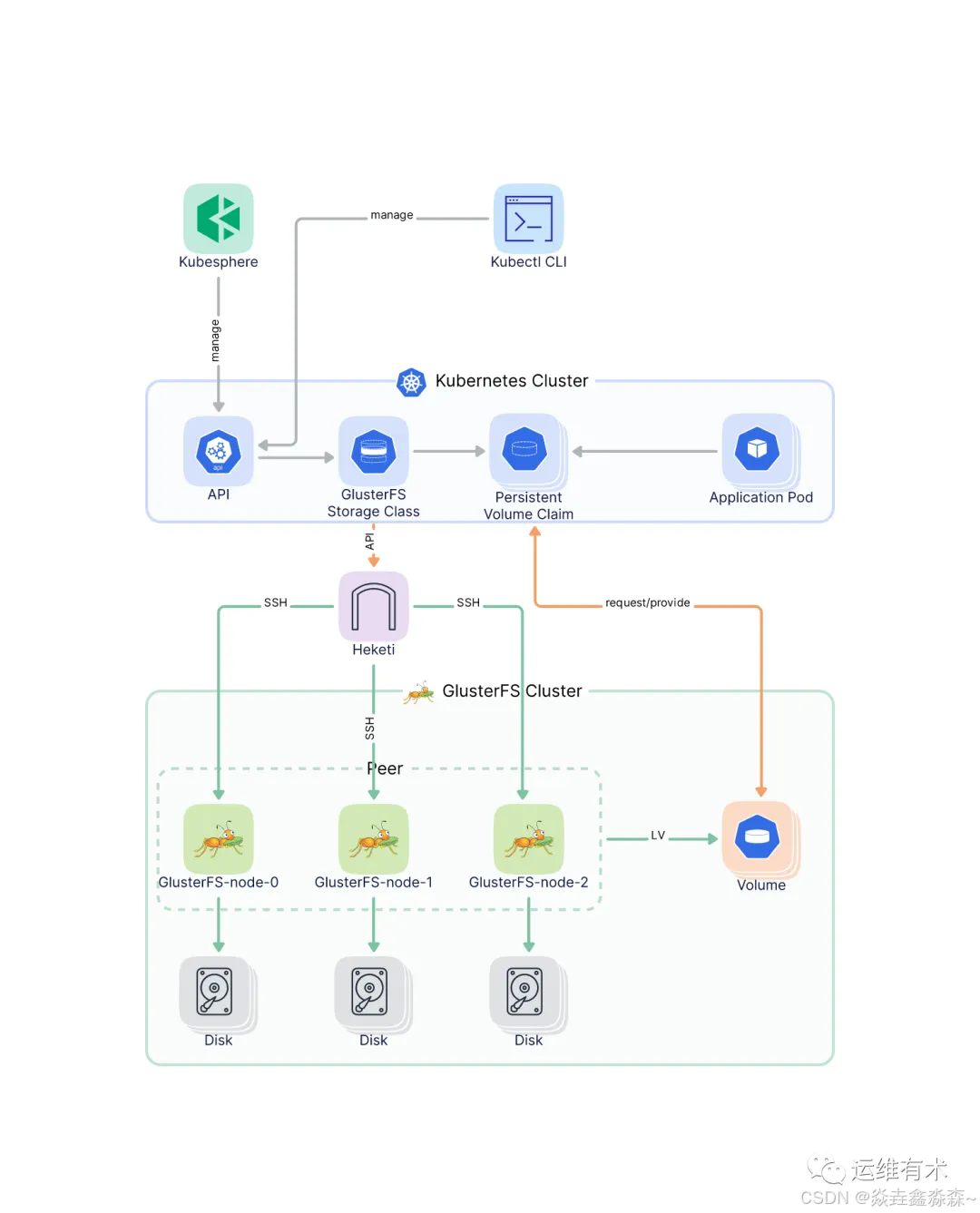
领域自适应语义分割是指在一个领域上训练的语义分割模型能够有效地应用到另一个不同但相关的领域。主动学习是通过智能选择最有价值的数据进行标注,以提高模型的性能和效率。将这两者结合起来,可以实现高效的领域自适应语义分割。
以下是实现主动学习和领域自适应语义分割的详细步骤:
1. 数据准备
- 源领域数据:包含大量已标注的训练数据。
- 目标领域数据:包含未标注或部分标注的训练数据。
2. 预训练源领域模型
在源领域数据上训练初始的语义分割模型。可以使用诸如DeepLab、FCN、U-Net等经典的语义分割网络。
import torch
import torchvision.transforms as transforms
from torchvision.models.segmentation import deeplabv3_resnet50# 定义数据集和数据加载器
# 假设你已经准备好了数据集 DataLoader# 初始化模型
model = deeplabv3_resnet50(pretrained=False, num_classes=num_classes)# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)# 训练模型
for epoch in range(num_epochs):model.train()for images, labels in source_dataloader:outputs = model(images)['out']loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()
3. 领域自适应
使用目标领域的数据进行领域自适应训练。这里我们使用无监督领域自适应技术,如对抗性训练。
from torch.autograd import Variable
from torchvision.models.segmentation import deeplabv3_resnet50# 假设已经有了预训练的模型
model = deeplabv3_resnet50(pretrained=False, num_classes=num_classes)
model.load_state_dict(torch.load('pretrained_model.pth'))# 定义对抗性训练的判别器
discriminator = Discriminator()# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer_model = torch.optim.Adam(model.parameters(), lr=1e-4)
optimizer_discriminator = torch.optim.Adam(discriminator.parameters(), lr=1e-4)# 领域自适应训练
for epoch in range(adaptation_epochs):model.train()discriminator.train()for source_images, source_labels, target_images in zip(source_dataloader, target_dataloader):source_outputs = model(source_images)['out']target_outputs = model(target_images)['out']# 对抗性训练optimizer_discriminator.zero_grad()source_loss = criterion(discriminator(source_outputs), torch.ones_like(source_outputs))target_loss = criterion(discriminator(target_outputs), torch.zeros_like(target_outputs))discriminator_loss = (source_loss + target_loss) / 2discriminator_loss.backward()optimizer_discriminator.step()# 训练模型optimizer_model.zero_grad()seg_loss = criterion(source_outputs, source_labels)adv_loss = criterion(discriminator(target_outputs), torch.ones_like(target_outputs))total_loss = seg_loss + adv_losstotal_loss.backward()optimizer_model.step()
4. 主动学习策略
主动学习选择最有价值的目标领域数据进行标注。常用的策略包括不确定性采样和多样性采样。
import numpy as npdef uncertainty_sampling(model, target_dataloader):model.eval()uncertainties = []with torch.no_grad():for images in target_dataloader:outputs = model(images)['out']prob = torch.nn.functional.softmax(outputs, dim=1)uncertainty = -torch.max(prob, dim=1)[0]uncertainties.append(uncertainty.cpu().numpy())uncertainties = np.concatenate(uncertainties)uncertain_indices = np.argsort(uncertainties)[-num_samples_to_label:]return uncertain_indicesdef diversity_sampling(features, num_samples_to_label):# 使用K-means或者其他聚类算法进行多样性采样from sklearn.cluster import KMeanskmeans = KMeans(n_clusters=num_samples_to_label)kmeans.fit(features)return kmeans.cluster_centers_# 选择样本进行标注
uncertain_indices = uncertainty_sampling(model, target_dataloader)
diverse_samples = diversity_sampling(target_features, num_samples_to_label)
5. 标注和迭代训练
根据主动学习策略选择的样本进行标注,并将其添加到训练集中,重新训练模型。
# 假设我们已经选择了需要标注的样本
labeled_target_images, labeled_target_labels = label_samples(target_dataloader, uncertain_indices)# 将标注的样本添加到训练集中
combined_dataloader = combine_dataloaders(source_dataloader, labeled_target_dataloader)# 迭代训练
for epoch in range(adaptation_epochs):model.train()for images, labels in combined_dataloader:outputs = model(images)['out']loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()
总结
通过上述步骤,可以实现主动学习和领域自适应的语义分割。首先在源领域数据上预训练模型,然后通过无监督领域自适应技术调整模型,使其能够在目标领域上表现良好。最后,使用主动学习策略选择最有价值的样本进行标注,不断迭代和优化模型。这种方法可以在最小化标注成本的情况下,显著提高模型在目标领域上的表现。