📖 前言:在实际开发中,有时候需要将HDFS或Hive上的数据导出到传统关系型数据库中(如MySQL、Oracle等),或者将传统关系型数据库中的数据导入到HDFS或Hive上,如果通过人工手动进行数据迁移的话,就会显得非常麻烦。为此,可使用Apache提供的Sqoop工具进行数据迁移。
目录
- 🕒 1. Sqoop概述
- 🕘 1.1 Sqoop简介
- 🕘 1.2 Sqoop原理
- 🕒 2. Sqoop安装配置
- 🕒 3. 课后习题
🕒 1. Sqoop概述
🕘 1.1 Sqoop简介
Sqoop是Apache的一款开源工具,Sqoop主要用于在Hadoop和关系数据库或大型机之间传输数据,可以使用Sqoop工具将数据从关系数据库管理系统导入(import)到Hadoop分布式文件系统中,或者将Hadoop中的数据转换导出(export)到关系数据库管理系统。
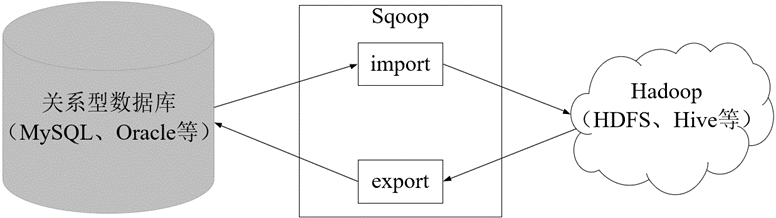
目前Sqoop主要分为Sqoop1和Sqoop2两个版本,其中版本号为1.4.x属于Sqoop1,版本号为1.9.x属于Sqoop2。这两个版本的定位方向不同,体系结构具有很大的差异,它们之间互不兼容。Sqoop1相对于Sqoop2来说结构简单,易于部署和使用。
🕘 1.2 Sqoop原理
Sqoop是关系型数据库与Hadoop间进行数据同步的工具,其底层利用MapReduce并行计算模型以批处理方式加快数据传输速度,并且具有较好的容错性功能,以实现数据的导入和导出。在数据同步的过程中,MapReduce通常只涉及MapTask的处理,并不会涉及ReduceTask的处理,这是因为数据同步时,只涉及数据的读取与加载,并不会涉及到数据合并的操作。
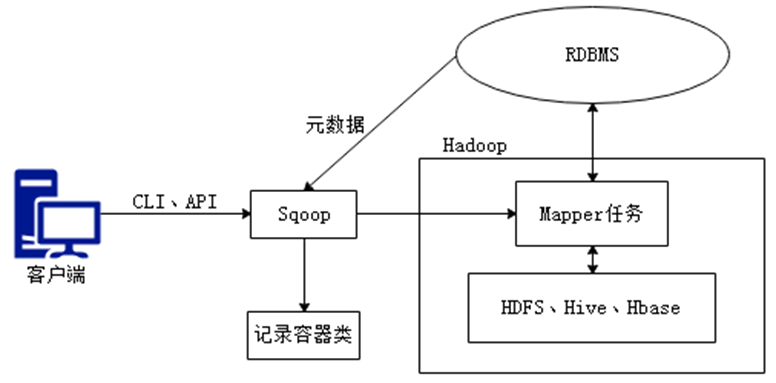
导入原理:在导入数据之前,Sqoop使用JDBC检查导入的数据表,检索出表中的所有列以及列的SQL数据类型,并将这些SQL类型映射为Java数据类型,在转换后的MapReduce应用中使用这些对应的Java类型来保存字段的值,Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。
导出原理:在导出数据前,Sqoop会根据目标表的定义生成一个Java类,这个生成的类能够从文本中解析出记录数据,并能够向表中插入类型合适的值,然后启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析出记录,并且执行选定的导出方法。
🕒 2. Sqoop安装配置
1、Sqoop的下载
在Ubuntu下打开官网:🔎 Sqoop官网 进行下载,建议下载稳定版本 🔎 sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
2、解压安装包sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 至路径 /opt,命令如下:
sudo tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt
sudo mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop
sudo chown -R hadoop:hadoop sqoop
4、修改配置文件
将/opt/sqoop/conf目录下的配置文件sqoop-env-template.sh复制一份,重命名为sqoop-env.sh,命令如下:
cd /opt/sqoop/conf
cp sqoop-env-template.sh sqoop-env.sh
sudo vim sqoop-env.sh
5、使用vim编辑器编辑sqoop-env.sh文件,找到Hadoop环境变量的配置说明,根据自己Hadoop和HBase路径,添加如下配置信息:
#Set Hadoop-specific environment variables here.
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/usr/local/hadoop
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/usr/local/hadoop
#set the path to where bin/hbase is available
export HBASE_HOME=
#Set the path to where bin/hive is available
export HIVE_HOME=/usr/local/hive
#Set the path for where zookeper config dir is
#export ZOOCFGDIR= # 如果自己配置了zookeeper,也需要在此配置zookeeper路径,没有就不用配置。
6、配置环境变量,使用vim编辑器打开.bashrc文件,在文件开头加入如下3行代码:
export SQOOP_HOME=/opt/sqoop
export CLASSPATH=$CLASSPASS:$SQOOP_HOME/lib
export PATH=$SQOOP_HOME/bin:$PATH
7、保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
8、添加mysql驱动程序。首先需要安装MySQL,前面章节已经完成该软件的安装,这里不再重复。然后需要将前面章节中已经下载的MySQL驱动程序mysql-connector-j-8.3.0.tar.gz解压缩后复制到$SQOOP_HOME/lib目录下。
sudo tar -zxvf mysql-connector-j-8.3.0.tar.gz
cp ./mysql-connector-j-8.3.0/mysql-connector-j-8.3.0.jar /opt/sqoop/lib
9、添加依赖包,使用Sqoop进行数据导入和数据导出的操作时,依赖于jar包commons-lang-2.6.jar和hive-common-3.1.3.jar,需要将改jar包上传到Sqoop安装目录的lib目录下。
🔎 commons-lang-2.6.jar
sudo tar -zxvf commons-lang-2.6-bin.tar.gz
cp ./commons-lang-2.6/commons-lang-2.6.jar /opt/sqoop/libcp /usr/local/hive/lib/hive-common-3.1.3.jar /opt/sqoop/lib
10、测试与MySQL的连接
首先保证MySQL服务已经启动,如果没有启动,请执行如下命令:
service mysql start
然后就可以测试Sqoop与MySql直接的连接是否成功,执行命令如下:
sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root -P
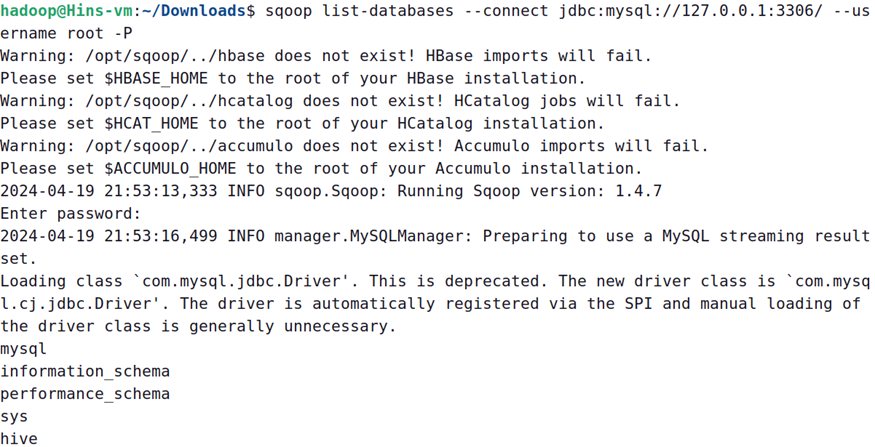
如果能够看到MySql数据库中的数据库列表,就表示Sqoop安装成功。例如,从上图给出的信息中就可以看到在最后几行包含了如下数据库列表:
mysql
information_schema
performance_schema
sys
hive
🕒 3. 课后习题
一、填空题
1、从数据库导入HDFS时,指定以制表符作为字段分隔符参数是_____________。
二、判断题
1、Sqoop是关系型数据库与Hadoop之间的数据桥梁,这个桥梁的重要组件是Sqoop连接器。
2、Sqoop从Hive表导出MySQL表时,首先需要在MySQL中创建表结构。
3、–target-dir参数是指定HDFS目标目录地址,因此需要提前创建目标文件。
三、选择题
1、下列选项参数是Sqoop指令的是?(多选)
A、import
B、output
C、input
D、export
2、下列语句描述错误的是()
A、可以通过CLI方式、Java API方式调用Sqoop
B、Sqoop底层会将Sqoop命令转换为MapReduce任务,并通过Sqoop连接器进行数据的导入导出操作。
C、Sqoop是独立的数据迁移工具,可以在任何系统上执行。
D、如果在Hadoop分布式集群环境下,连接MySQL服务器参数不能是localhost或127.0.0.1。
四、编程题
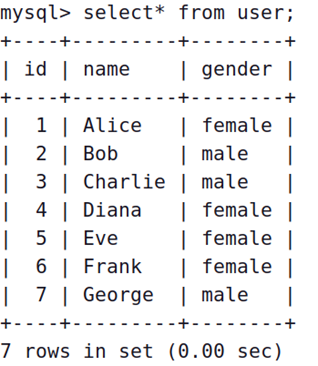
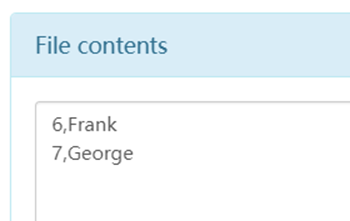
1、利用Sqoop将test数据库中的user表中id>5的用户导入到HDFS中的/user目录(user表字段:id,name)。
2、利用Sqoop将test数据库中的emp表导入Hive表hive.emp_test表中。
解答:
一、1、--fields-terminated-by '\t'
二、1、√ 2、√ 3、×
三、1、AD 2、C
四、1、
sqoop import \
--connect jdbc:mysql://127.0.0.1:3306/test \
--username root \
--password 1111 \
--target-dir /user/sqoop \
--query 'SELECT id,name FROM user WHERE id>5 AND $CONDITIONS' \
--num-mappers 1 \
--bindir /opt/sqoop/lib
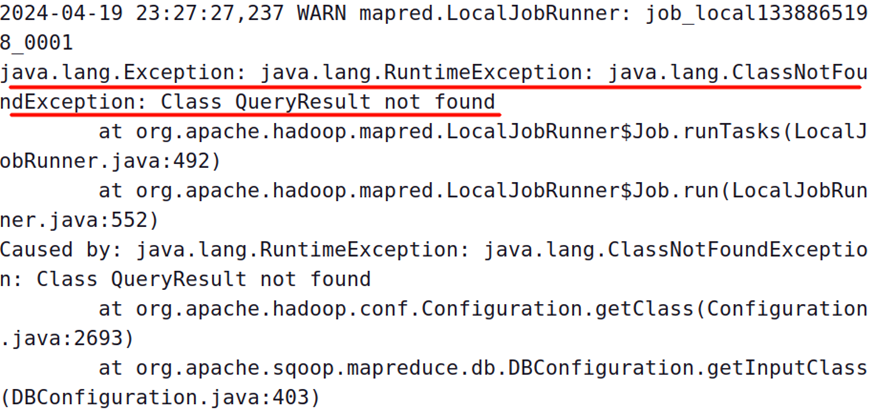
如果有如下报错,参考链接解决
🔎 使用sqoop将mysql数据上传至hdfs出现找不到类的问题
2、
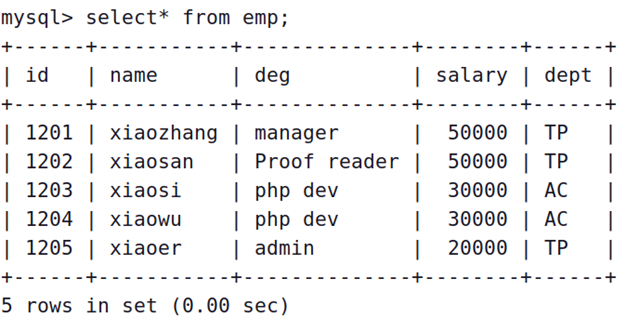
sqoop import \
--connect jdbc:mysql://127.0.0.1:3306/test \
--username root \
--password 1111 \
--table emp \
--hive-table hive_emp_test \
--create-hive-table \
--hive-import \
--num-mappers 1 \
--bindir /opt/sqoop/lib

OK,以上就是本期知识点“Sqoop数据迁移”的知识啦~~ ,感谢友友们的阅读。后续还会继续更新,欢迎持续关注哟📌~
💫如果有错误❌,欢迎批评指正呀👀~让我们一起相互进步🚀
🎉如果觉得收获满满,可以点点赞👍支持一下哟~
❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页