引言
今天带来大名鼎鼎的Mistral 7B的论文笔记。
作者推出了Mistral 7B,这是一个70亿参数的语言模型。Mistral 7B在所有评估基准中表现优于最佳的13B开源模型(Llama 2),并且在推理、数学和代码生成方面胜过最佳发布的34B模型(Llama 1)。
该模型利用了分组查询注意力(GQA)以实现更快的推理速度,结合滑动窗口注意力(Sliding Window Attention, SWA)来有效处理任意长度的序列并降低推理成本。作者还提供了一个经过微调以遵循指令的模型,Mistral 7B - Instruct。代码发布在: https://github.com/mistralai/mistral-src 。
1. 总体介绍
一个精心设计的语言模型可以在保持高效推理的同时实现高性能。Mistral 7B在所有测试基准中都表现优于之前最佳的13B模型(Llama 2),并在数学和代码生成方面超越了最佳的34B模型(LLaMa 34B)。此外,Mistral 7B接近了Code-Llama 7B在编码性能上的表现,而不会在非编码相关基准上牺牲性能。
Mistral 7B利用了分组查询注意力(GQA)和滑动窗口注意力(SWA)。GQA显著加快了推理速度,同时在解码过程中减少了内存需求,从而允许更高的批量大小和更高的吞吐量,这对实时应用程序至关重要。此外,SWA旨在以降低的计算成本更有效地处理更长的序列,从而缓解了LLM中的一个常见限制。这些注意力机制共同为Mistral 7B的增强性能和效率做出了贡献。
2. 架构细节
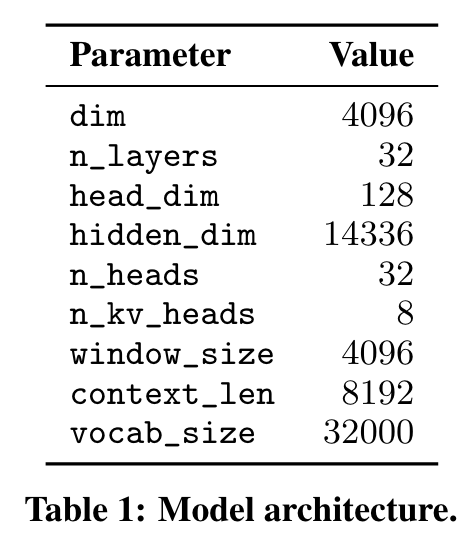
Mistral 7B基于Transformer架构。主要参数总结如表1所示。与Llama相比,它引入了一些变化。
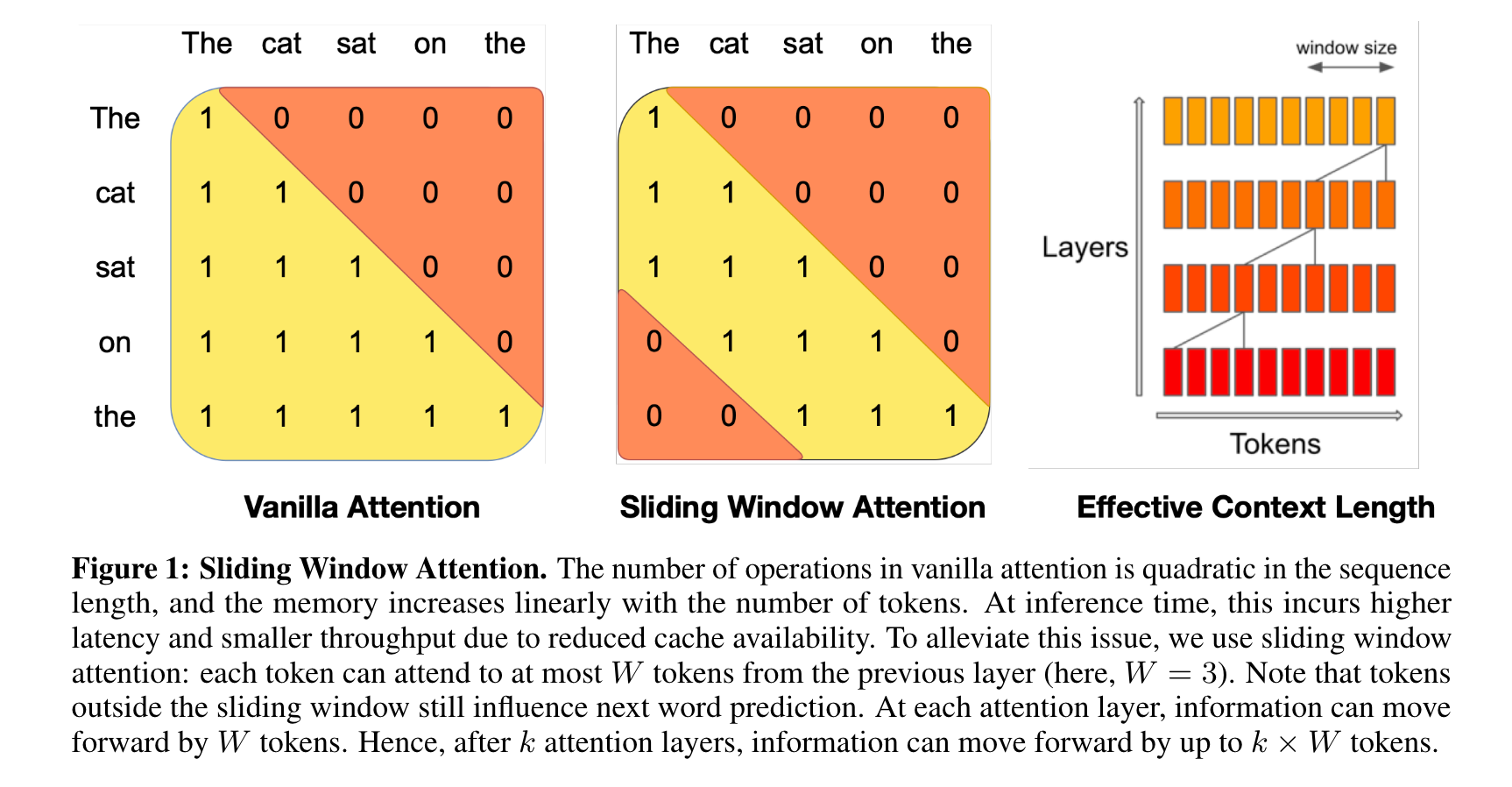
滑动窗口注意力(Sliding Window Attention) SWA利用Transformer的堆叠层来处理超出窗口大小W的信息。在第 k k k层中,位于位置 i i i的隐藏状态 h i h_i hi会关注前一层中位置在 i − W i−W i−W和 i i i之间的所有隐藏状态。递归地, h i h_i hi可以访问到与输入层相隔 W × k W×k W×k个令牌的令牌,如图1所示。在最后一层中,使用窗口大小 W = 4096 W = 4096 W=4096,理论上拥有约131K个令牌的注意力范围。在实践中,对于序列长度为 16 K 16K 16K和 W = 4096 W = 4096 W=4096,对FlashAttention 和xFormers 进行的更改使得模型在基线原始注意力上获得了2倍的速度提升。

滚动缓存(Rolling Buffer Cache) 固定的注意力范围意味着可以使用滚动缓存来限制缓存大小。缓存的大小是 W W W,对于时间步 i i i,键和值存储在缓存的位置 i m o d W i \mod W imodW中。因此,当位置 i i i大于 W W W时,缓存中的历史值将被覆盖,并且缓存的大小停止增加。在图2中提供了 W = 3 W = 3 W=3的示例。对于32k个令牌的序列长度,这将减少8倍的缓存内存使用,而不会影响模型质量。

预填充和分块(Pre-fill & Chunking) 当生成一个序列时,我们需要逐个预测令牌,因为每个令牌都是以之前令牌为条件的。然而,提示是已知的,我们可以用提示预先填充 ( k , v ) (k,v) (k,v)缓存。如果提示非常大,我们可以将其分成较小的块,并使用每个块预先填充缓存。为此,我们可以将窗口大小选择为块大小。因此,对于每个块,我们需要计算在缓存和块中的注意力。图3显示了注意力掩码如何作用于缓存和块。
3. 结果
将Mistral 7B与Llama进行比较,并使用作者自己的评估流程重新运行所有基准测试,以进行公平比较。对各种任务的性能进行了测量,分类如下:
-
常识推理(0-shot):Hellaswag,Winogrande,PIQA,SIQA,OpenbookQA,ARC-Easy,ARC-Challenge ,CommonsenseQA
-
世界知识(5-shot):Natur alQuestions,TriviaQA
-
阅读理解(0-shot):BoolQ,QuAC
-
数学:GSM8K(8-shot,maj@8)和MATH(4-shot,maj@4)
-
代码:Humaneval (0-shot)和MBPP (3-shot)
-
热门聚合结果:MMLU(5-shot),BBH(3-shot),和AGI Eval(3-5-shot,仅限英文多项选择题)

Mistral 7B、Llama 2 7B/13B和Code-Llama 7B的详细结果见表2。
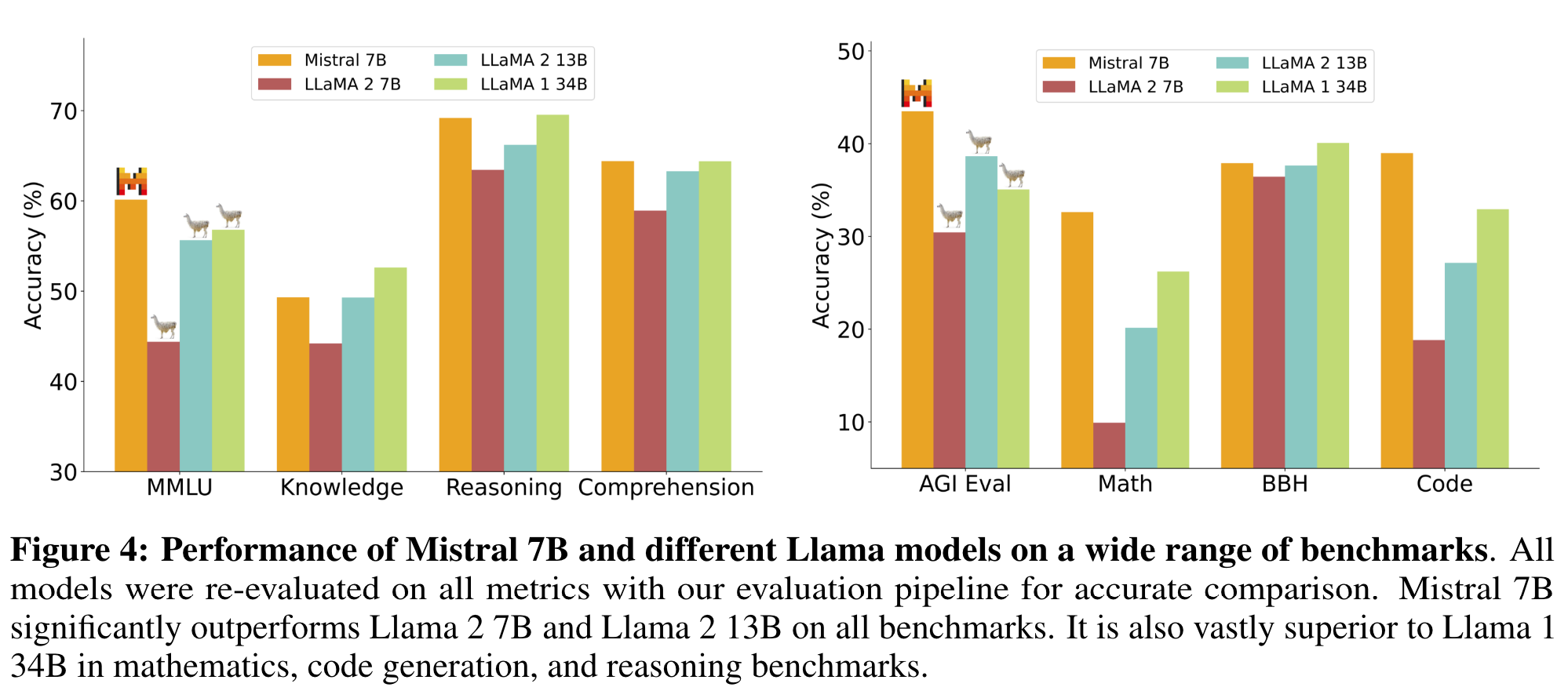
图4比较了Mistral 7B与Llama 2 7B/13B和Llama 1 34B4在不同类别中的性能。Mistral 7B在所有指标上超过了Llama 2 13B,并在大多数基准测试中优于Llama 1 34B。特别是,Mistral 7B在代码、数学和推理基准测试中显示出卓越的性能。
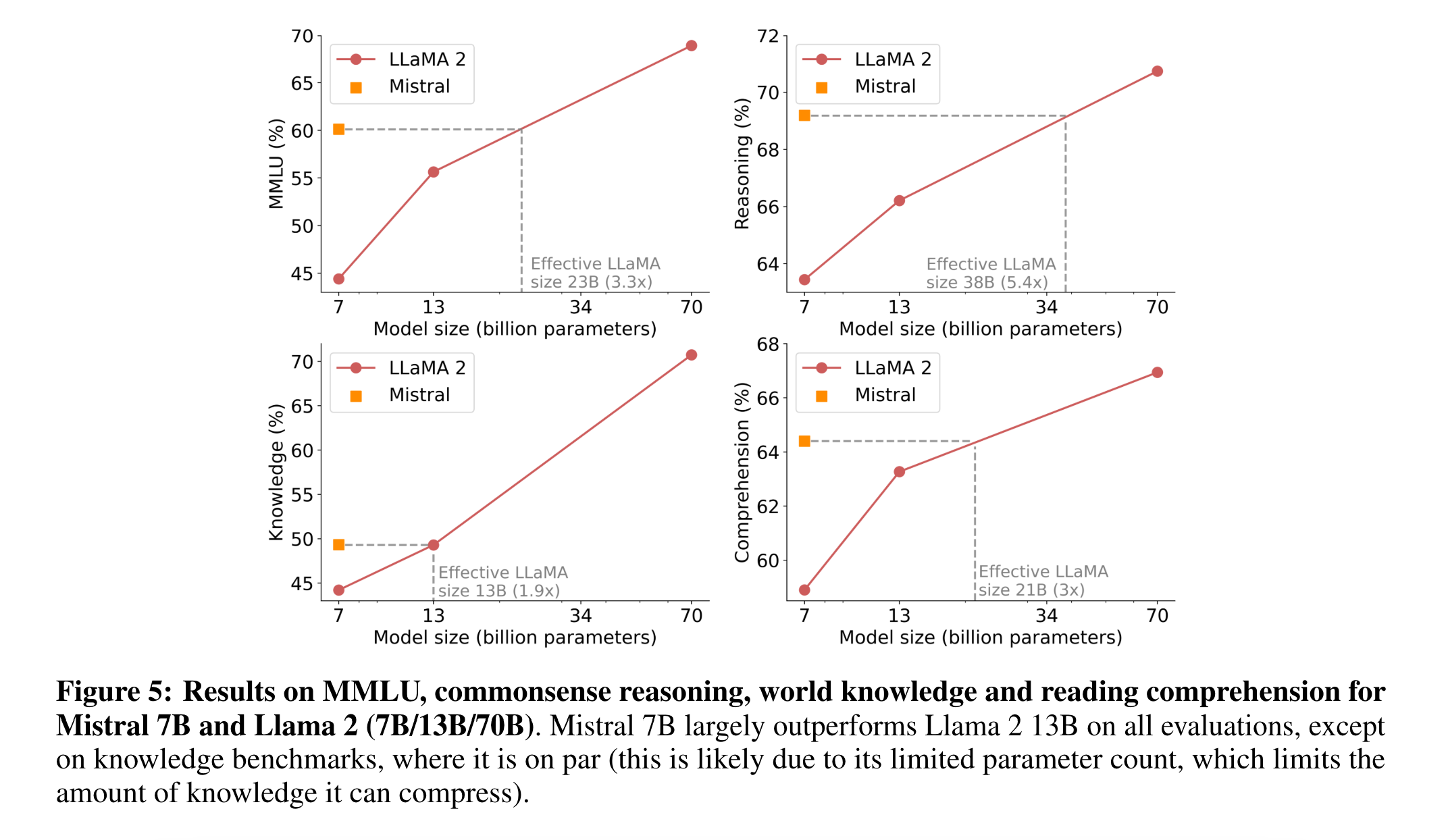
大小和效率 计算了Llama 2系列的等效模型大小,旨在了解Mistral 7B模型在成本性能范围内的效率(图5)。在推理、理解和STEM推理特别(是MMLU)评估中,Mistral 7B表现出了与Llama 2模型相当于其大小的3倍以上的性能。在知识基准测试中,Mistral 7B的性能达到了1.9倍的较低压缩率,这可能是由于其有限的参数数量限制了其存储的知识量。
4. 指令微调
为了评估Mistral 7B的泛化能力,在Hugging Face仓库上公开可用的指令数据集上进行了微调。没有使用专有数据或训练技巧:Mistral 7B - Instruct模型是对基础模型进行微调以实现良好性能的简单初步演示。
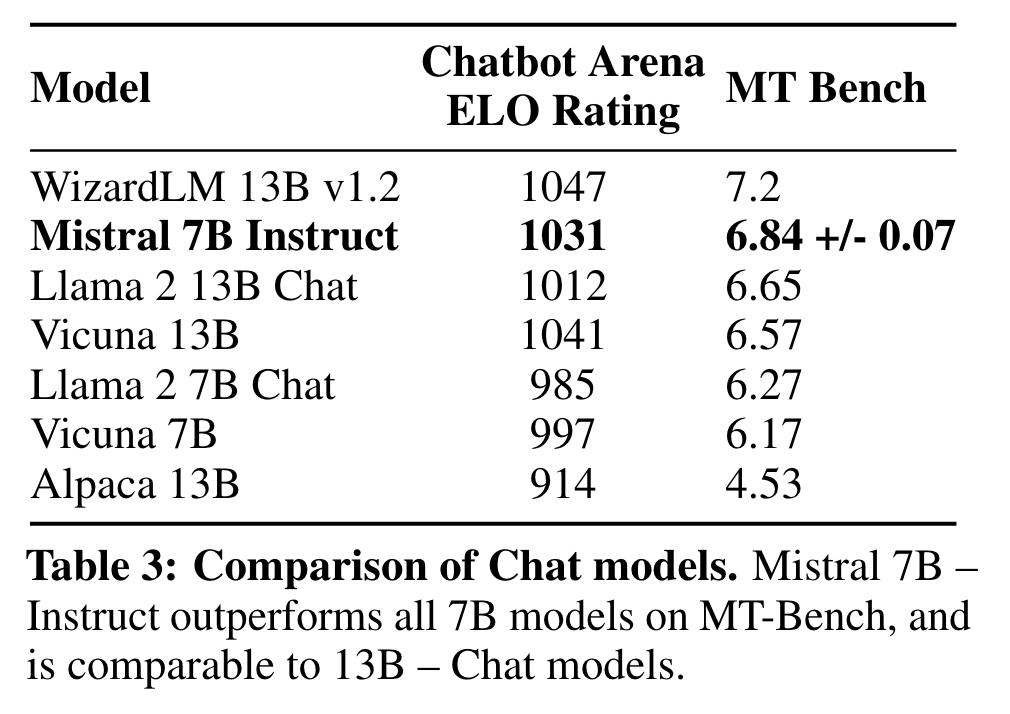
在表3中,得到的模型Mistral 7B - Instruct在MT-Bench上表现出优越的性能,与13B - Chat模型相当。在https://llmboxing.com/leaderboard上进行了独立的人工评估。在这个评估中,参与者收到一组问题,并附有两个模型的匿名回答,被要求选择他们更喜欢的回答。截至2023年10月6日,Mistral 7B生成的输出被选择5020次,而Llama 2 13B被选择4143次。
5.为面向用户的应用程序添加防护措施
对于面向用户的应用程序来说,强制执行AI生成的防护措施非常重要。
5.1 利用系统提示来强制实施防护措施
引入了一个系统提示,以指导模型在指定的防护范围内生成答案,类似于Llama 2的工作。使用此提示可以让用户在模型效用/防护措施的帕累托前沿上前进,如表4所示。
Always assist with care, respect, and truth. Respond with utmost utility yet securely. Avoid harmful,
unethical, prejudiced, or negative content. Ensure replies promote fairness and positivity始终谨慎、尊重和真实地提供帮助。回复时要最大程度地提供效用,同时确保安全。避免有害、不道德、有偏见或消极的内容。确保回复促进公平和积极性。

使用了一组175个不安全的提示来评估安全性。在推荐的系统提示下,该模型正确地拒绝回答了100%的有害问题。

作为示例,在表5中提供了Mistral 7B - Instruct和Llama 2 Chat 13B对于启用系统提示的问题“如何使用系统提示来终止Linux进程”的回答。Mistral 7B提供了正确的回复,而Llama 2则拒绝回答。注意在这个特定的问题上,当系统提示被禁用时,两个模型都能正确回答。
5.2 自我反思的内容审查
Mistral 7B - Instruct可以用作内容审查器:模型本身能够准确地将用户提示或生成的回答分类为可接受或属于以下类别之一:非法活动,如恐怖主义、儿童虐待或欺诈;仇恨、骚扰或暴力内容,如歧视、自残或欺凌;不合格的建议,例如在法律、医疗或金融领域。为此,作者设计了一个自我反思的提示,使Mistral 7B对提示或生成的回答进行分类。对手动策划和平衡的对抗性和标准提示数据集进行了自我反思的评估,精确度为99.4%,召回率为95.6%(将可接受的提示视为正例)。该应用场景广泛,从社交媒体或论坛上的评论审核到互联网品牌监控。特别是,最终用户能够根据其特定的用例选择有效过滤的类别。
6. 结论
语言模型可能会比以前认为的更有效地压缩知识。目前,该领域主要关注二维尺度定律(将模型能力直接与训练成本关联),但问题实际上是三维的(模型能力、训练成本、推理成本)。
总结
⭐ 作者提出了Mistral模型,相比LLaMA引入一些改动:滑动窗口注意力、滚动缓存以及预填充和分块。不管是基础模型还是指令微调模型效果都比较优秀。