模板虚拟机安装配置见博文:https://blog.csdn.net/weixin_66158110/article/details/139236148
配置文件信息如下:https://pan.baidu.com/s/1074eD5aNVugEPcjwVvi9jA?pwd=l1xq(提取码:l1xq)
一、克隆模版虚拟机
1、克隆虚拟机
鼠标移动至虚拟机--管理--克隆,除提到页面均点击下一页即可
(1)克隆类型必须选择“创建完整克隆”

(2)编辑名称和位置
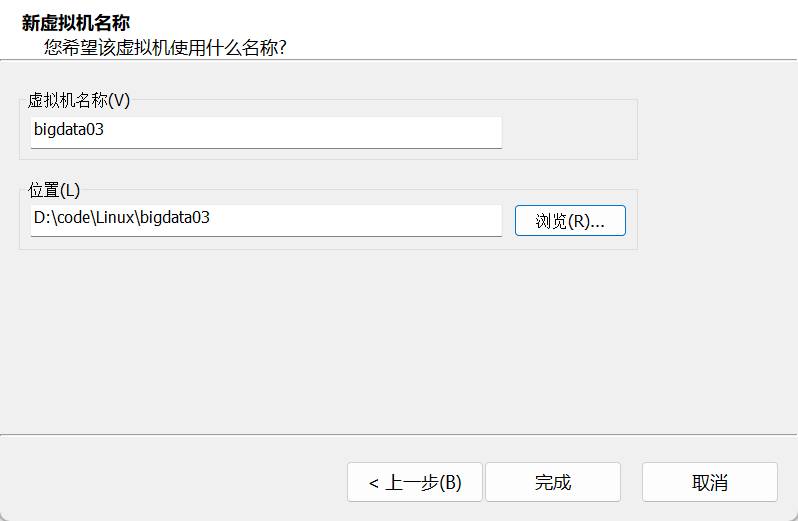
点击完成后等待
再重复上述步骤两遍,分别命名为bigdata04、bigdata05
2、修改克隆机的ip地址
(1)打开虚拟机后进入如下目录
cd /etc/sysconfig/network-scripts(2)编辑ifcfg-ens33文件内容
vi ifcfg-ens33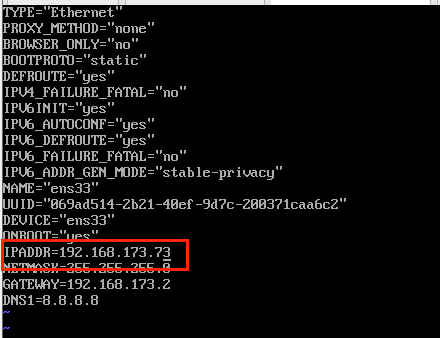
bigdata03、04、05分别改为73、74、75
3、修改克隆机的主机名称
vi /etc/hostnamebigdata03、04、05分别改为bigdata03、bigdata04、bigdata05
完成后把所有虚拟机都重启一下
二、MobaXterm连接三台虚拟机
点击Session进行如下配置
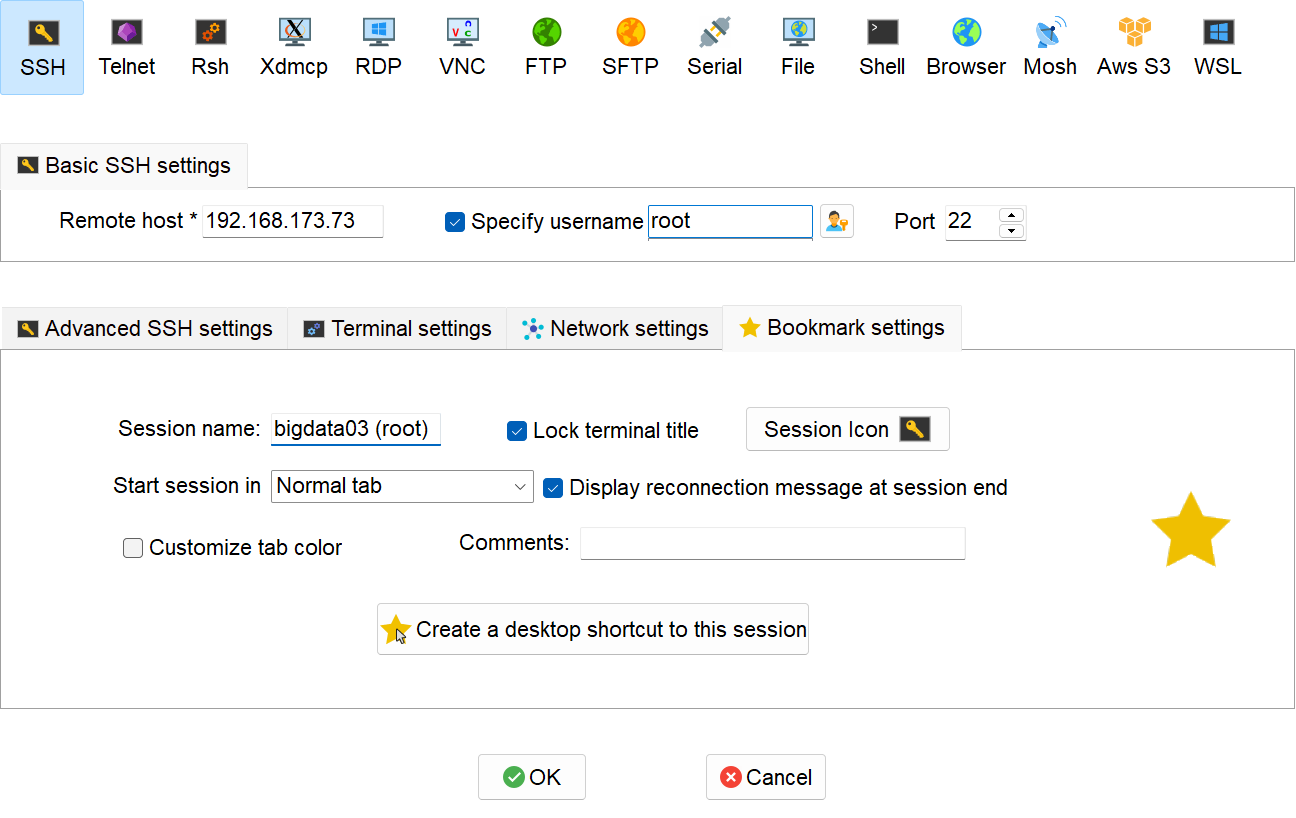
创建成功后如下图
三、在bigdata03安装hadoop
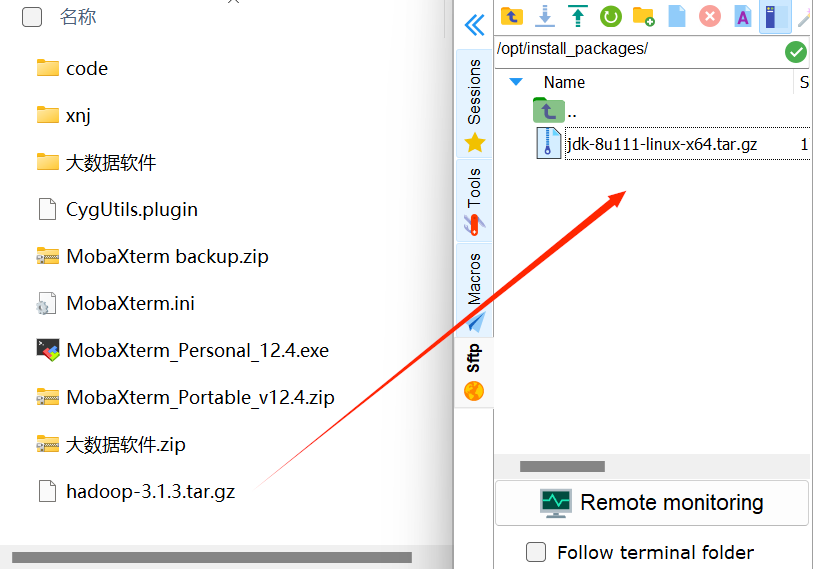
1、上传安装包
在bigdata03左边的输入框输入/opt,点击进入install_packages,将下载好的hadoop压缩包拖入
2、输入命令解压
tar -zxvf /opt/install_packages/hadoop-3.1.3.tar.gz -C /opt/softs/3、重命名文件夹
进入到softs目录下
cd /opt/softs修改文件夹名称
mv hadoop-3.1.3/ hadoop3.1.3/4、配置环境变量
(1)编辑配置文件
vim /etc/profile(2)在配置文件末尾加入如下内容
#HADOOP_HOME
export HADOOP_HOME=/opt/softs/hadoop3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbinexport HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root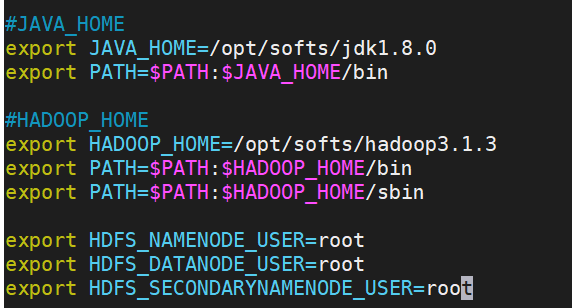
(3) 使配置文件生效
source /etc/profile(4)验证环境变量配置是否生效
echo $HADOOP_HOME显示如下图没问题

四、配置三台虚拟机的映射
1、编辑hosts文件
vim /etc/hosts在文件末尾加上如下代码
192.168.173.73 bigdata03
192.168.173.74 bigdata04
192.168.173.75 bigdata05
2、将编辑好的hosts文件远程传输给bigdata04、bigdata05
scp /etc/hosts root@bigdata04:/etc/
scp /etc/hosts root@bigdata05:/etc/
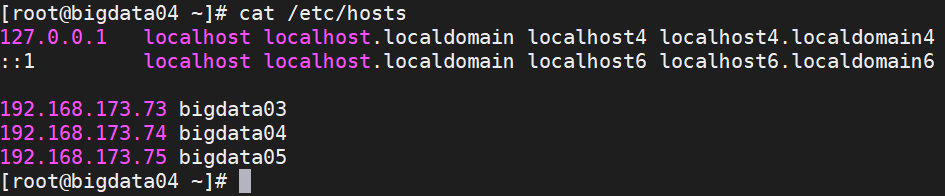
3、检查是否传输过去
在bigdata04中输入如下命令
cat /etc/hosts显示如下图成功
五、设置免密登录
以下步骤在bigdata03、bigdata04、bigdata05上均要各自手动执行一次,共执行三次。
1、切换目录
cd /root2、查看隐藏内容
ls -al3、进入.ssh目录
cd .ssh4、生成免密登录的公钥和私钥
ssh-keygen -t rsa命令执行后,回车三次,可以完成公钥和私钥的生成
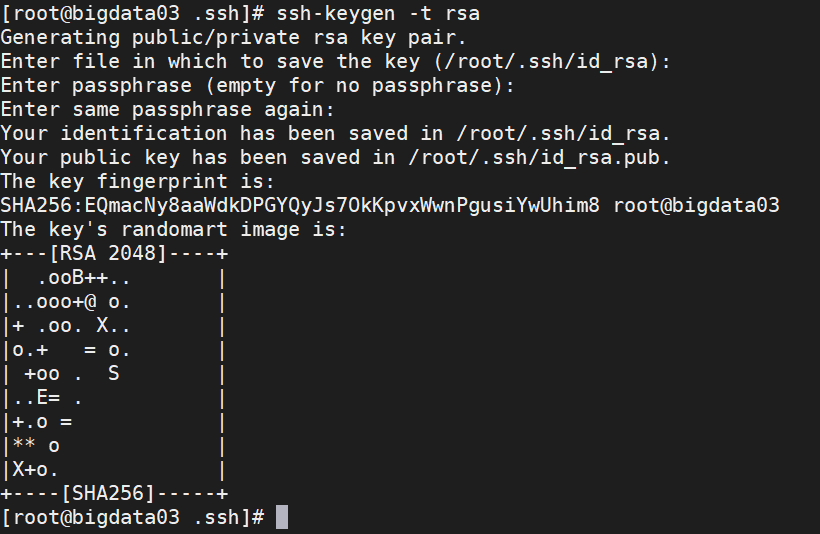
5、将公钥和私钥发送到要免密的虚拟机上
ssh-copy-id bigdata03ssh-copy-id bigdata04ssh-copy-id bigdata05六、集群规划
| bigdata03 | bigdata04 | bigdata05 | |
| HDFS | NameNode DataNode | SecondNameNode DataNode | DataNode |
| YARN | NodeManager | NodeManager | ResourceManager NodeManager |
集群规划时有两个注意点:
- hdfs中的NameNode和SecondNameNode不要安装在同一个节点上
- yarn中的ResourceManager不要和NameNode和SecondNameNode在同一个节点上
1、在bigdata03中根据集群规划修改配置文件
(1)跳转到配置文件目录下
cd /opt/softs/hadoop3.1.3/etc/hadoop(2)修改hadoop-env.sh
vim hadoop-env.sh输入/JAVA_HOME检索位置,修改第三个位置的JAVA_HOME

(3)将4个xml文件拖到/opt/softs/hadoop3.1.3/etc/hadoop目录下
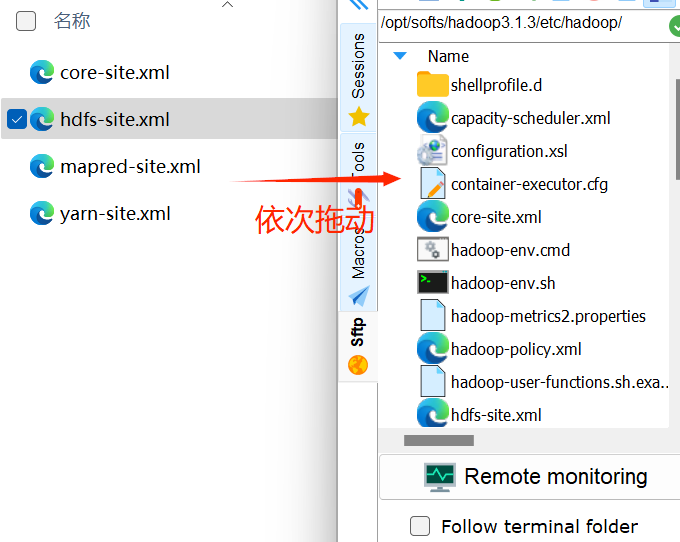
(4)编辑workers
vim workers输入如下内容(一个一行不要并行)
bigdata03
bigdata04
bigdata05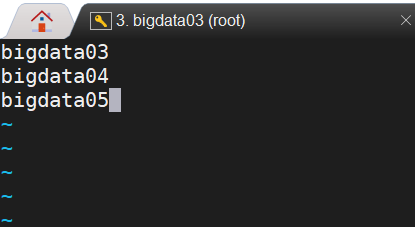
2、将hadoop3.1.3目录传输给bigdata04和05
在bigdata03中执行把东西远程传输过去就行
scp -r /opt/softs/hadoop3.1.3/ root@bigdata04:/opt/softs/scp -r /opt/softs/hadoop3.1.3/ root@bigdata05:/opt/softs/3、将profile文件传输给bigdata04和05
scp /etc/profile root@bigdata04:/etc/scp /etc/profile root@bigdata05:/etc/在bigdata03中传输完后记得在bigdata04和bigdata05中使profile文件生效
source /etc/profileTips:到这里集群的安装就完成了,剩下的内容属于集群初始化
七、在NameNode所在节点(bigdata03)进行初始化
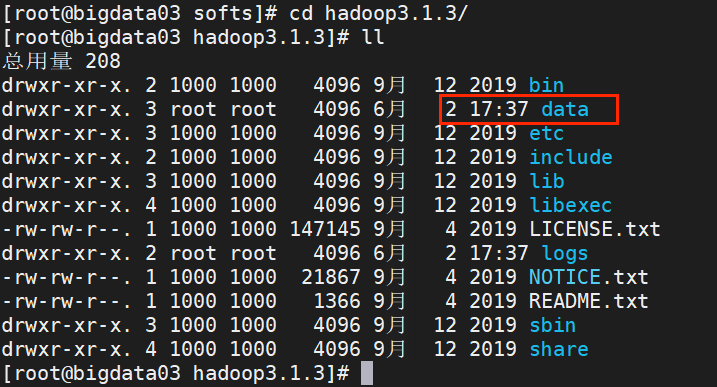
在bigdata03上执行如下语句
hdfs namenode -format完成后/opt/softs/hadoop3.1.3目录下会出现data目录
八、启动hdfs
1、在NameNode(bigdata03)上输入启动命令
start-dfs.sh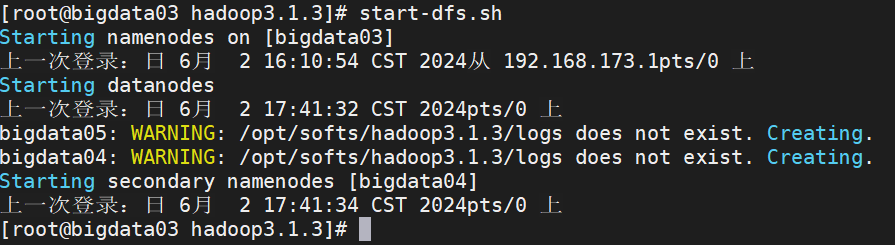
2、 在三台虚拟机上分别输入jps命令,检验输出是否与集群规划一致

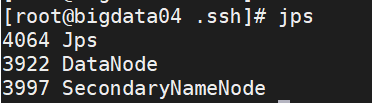

九、在ResourceManager(bigdata05)上启动yarn
1、跳转到指定目录下
cd /opt/softs/hadoop3.1.3/sbin2、启动命令
start-yarn.sh报错:
解决方法:
(1)编辑profile文件
vim /etc/profile在文件末尾添加这两行代码
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root(2)远程传输给另外两台
scp /etc/profile root@bigdata03:/etc/
scp /etc/profile root@bigdata04:/etc/(3)在三台模拟机中都输入如下命令使文件生效
source /etc/profile(4)在bigdata05中重新启动yarn
start-yarn.sh3、再次输入jps检验与集群规划是否一致
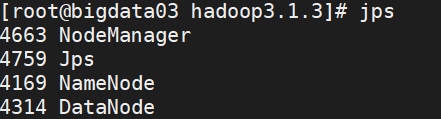
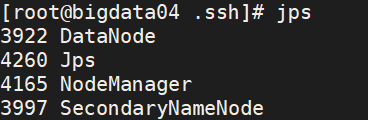
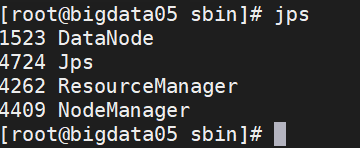
十、关闭hdfs和yarn
开启这两个后在关闭模拟机前都要记得关掉,这很重要!
stop-yarn.sh
stop-dfs.sh使用jps命令检查,只剩下jps说明关闭成功,可以关机了