作为一个程序员宝爸,每天的时间很宝贵,工作之余除了辅导孩子作业,就是补充睡眠。
怎么快速高效的进行当天A股涨停板的复盘,便于第二天的跟踪。这里简单写个示例, 获取当天连涨数排序,以及所属行业排序。
python">import akshare as ak
import xlsxwriter
import pandas as pdpd.set_option('display.max_rows', None) # 设置显示无限制行
pd.set_option('display.max_columns', None) # 设置显示无限制列
pd.set_option('display.width', None) # 自动检测控制台的宽度
pd.set_option('display.max_colwidth', 50) # 设置列的最大宽度为50date ="20240509"
df = ak.stock_zt_pool_em(date)
df['流通市值'] = round(df['流通市值']/100000000)
df['换手率']=round(df['换手率'])
spath = f"./{date}涨停.xlsx"
#print(df)
df.to_excel(spath, engine='xlsxwriter')selected_columns = ['代码', '名称', '最新价','流通市值', '换手率', '连板数','所属行业']
jj_df = df[selected_columns]# 按照'连板数'列进行降序排序
sorted_temp_df = jj_df.sort_values(by='连板数', ascending=False)
# 输出排序后的DataFrame
#print(sorted_temp_df)
sorted_temp_df_path = f"./{date}涨停排序.xlsx"
sorted_temp_df.to_excel(sorted_temp_df_path, engine='xlsxwriter')# 创建一个dataframe的副本
temp_df = jj_df.copy()# 计算每个行业出现的频率,并储存在一个字典中
industry_count = temp_df['所属行业'].value_counts().to_dict()# 使用.loc操作符添加一个新列,列的值是每个行业的频率
temp_df.loc[:,'industry_count'] = temp_df['所属行业'].map(industry_count)# 按照行业数量降序排列,如果行业数量相同,按照行业名称升序排列,然后按照连板数降序排列
sorted_industry_df = temp_df.sort_values(by=['industry_count', '所属行业', '连板数'], ascending=[False, True, False])# 打印排序后的dataframe
#print(sorted_industry_df)
# 删除临时的 'industry_count' 列,以保持原始dataframe的结构
temp_df = temp_df.drop(['industry_count'], axis=1)temp_path = f"./{date}涨停行业排序.xlsx"
sorted_industry_df.to_excel(temp_path, engine='xlsxwriter')
比如2024年5月9日当天, 按照连板数排序

涨停所属行业从多到少排序,如果涨停数相同按照行业名称排序, 行业名称一致则按照连涨数排序
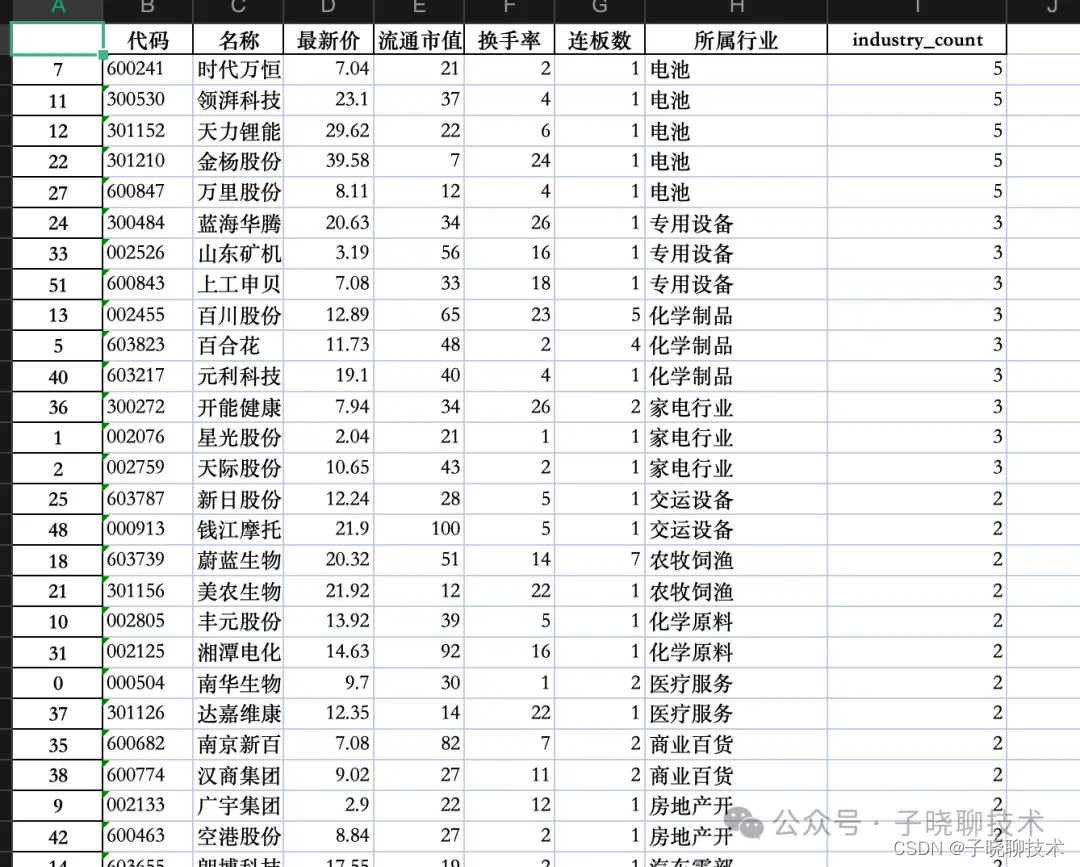
不完美的地方,由于数据缺陷, 没有获取真正涨停原因字段。 计划思路: 按照个人理解,jj_df 扩展涨停原因列,对所有涨停个股标注涨停原因,比如 当天很多个股其实是涨停 原因是合成生物。 这样代码逻辑 使用 该列替代 所属行业 梳理逻辑。
如果我的分享对你有所帮助,记得帮忙点赞给个关注
原文链接: 【Python技术】使用akshare、pandas高效复盘每日涨停板行业分析