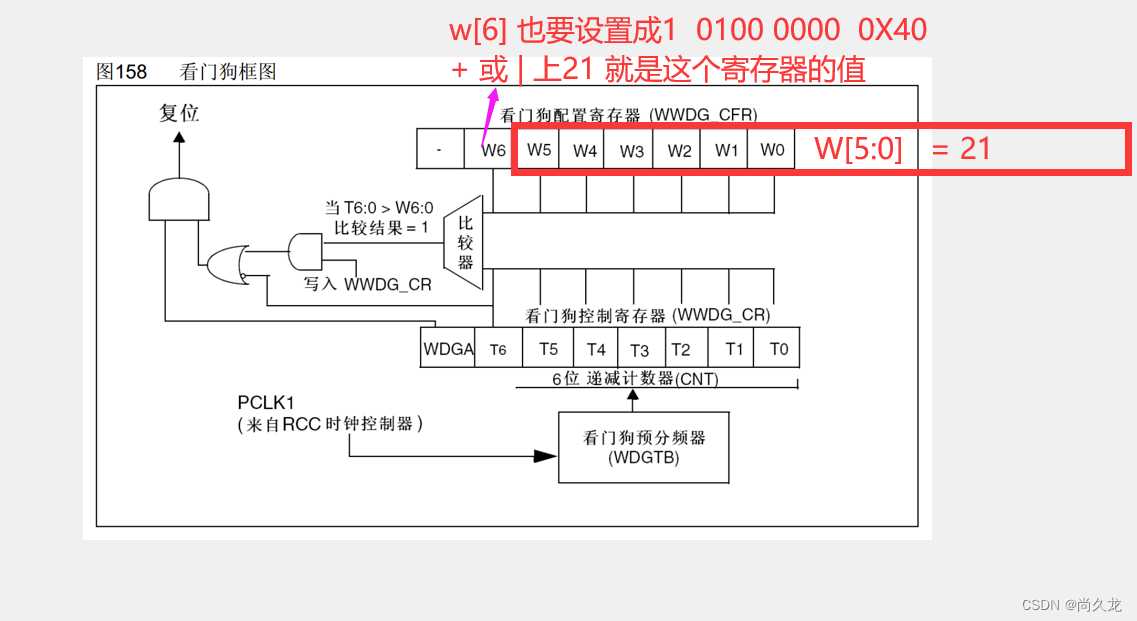
#describe()作用是计算出各个列的描述行统计量如平均数,方差,最大值,最小值,四分位数,返回类型是
#pandas.core.frame.DataFrame
import pandas as pddf = pd.read_csv("Nowcoder.csv")
print(df.describe().loc["25%",["Achievement_value", "Continuous_check_in_days"]])
print(df.describe().loc["75%",["Num_of_exercise","Number_of_submissions"]])
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print(round(Nowcoder.Num_of_exercise.var(),2))#刷题量的方差
print(round(Nowcoder.Number_of_submissions.std(),2))#提交代码次数的标准差
col1 = nk[nk['Level']==7]['Achievement_value'] ''' 从数据框中筛选出Level等于7的行,并从中选择Achievement_value列。 使用apply函数对Achievement_value列中的每个值除以该列的总和,并打印结果。 ''' print(col1.apply(lambda x:x/nk['Achievement_value'].sum()))
import pandas as pd
data = pd.read_csv('Nowcoder.csv',sep=',',dtype='object')#现在有点理解什么时候使用dtype,一般出现年份的时候
pd.set_option('display.max_rows',None)#这三行一般是在大多数数据的出现的时候需要
pd.set_option('display.max_columns',None)
pd.set_option('display.width',300)
print(data.dropna(axis=0,how='any',inplace=False))#其实使用inplace是否等于True或者False都只是想试试,没想到可以
函数形式:dropna(axis=0, how='any', thresh=None, subset=None, inplace=False
axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。
how:筛选方式。‘any’,表示该行/列只要有一个以上的空值,就删除该行/列;‘all’,表示该行/列全部都为空值,就删除该行/列。
thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。
subset:子集。列表,元素为行或者列的索引。如果axis=0或者‘index’,subset中元素为列的索引;如果axis=1或者‘column’,subset中元素为行的索引。由subset限制的子区域,是判断是否删除该行/列的条件判断区域。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。