🐶原文: Preventing Content Cloning in NFT Collections
🐶写在前面: 这是一篇 2023 年的 CCF-C 类,本博客只记录其中提出的方法。
NFT_and_Blockchains_with_Native_Support_of_NFTs_7"> F C o l l N F T \mathbf{F_{CollNFT}} FCollNFT and Blockchains with Native Support of NFTs
为了促进 NFT 集合 c o l l e c t i o n \mathsf{collection} collection 的发展,一些区块链技术,如 A l g o r a n d \mathsf{Algorand} Algorand,通过第 0 层 l a y e r 0 \mathsf{layer\ 0} layer 0 的功能实现 NFT 的交易。
区块链层次结构参考:
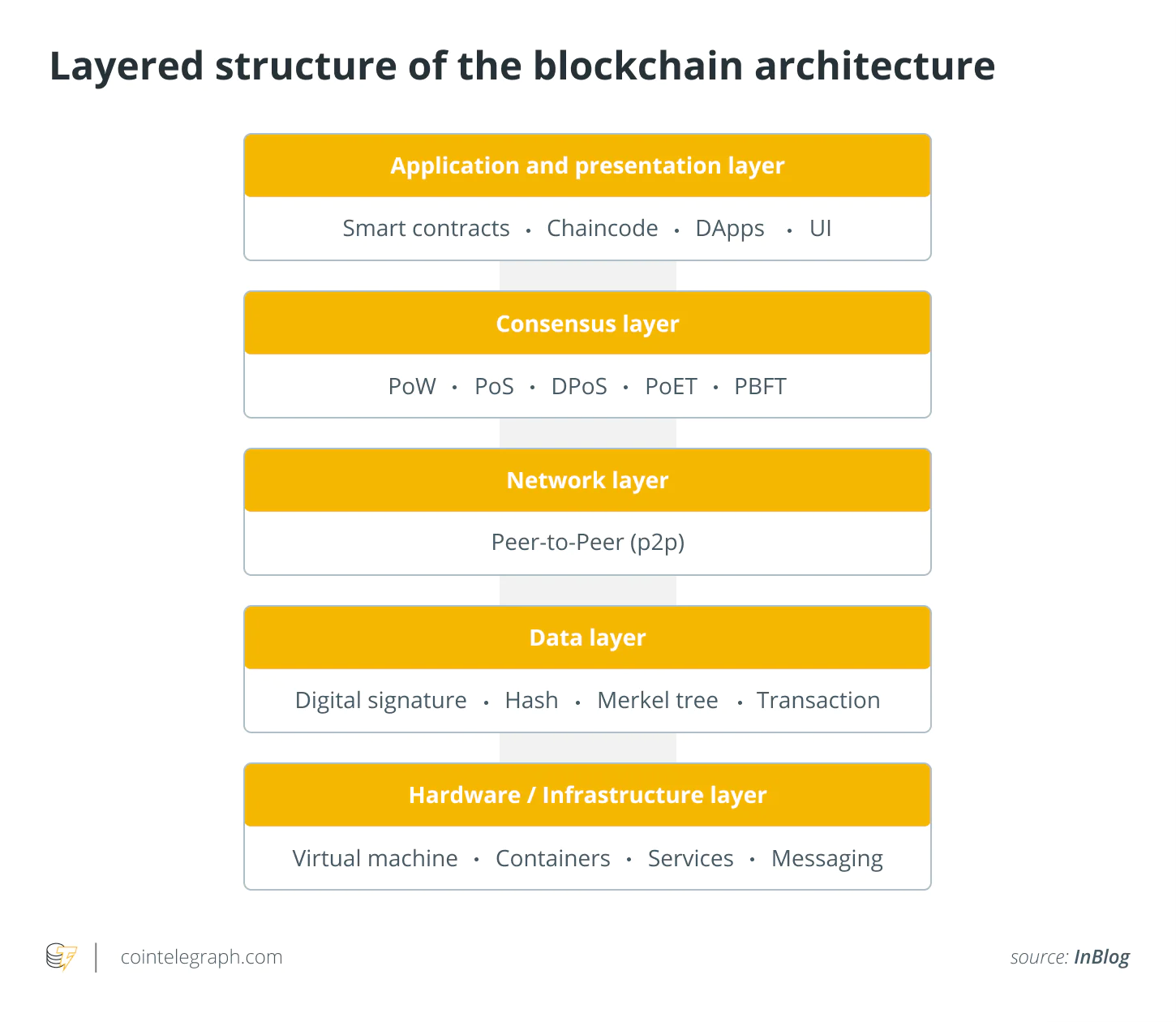
关于区块链如何分层这件事,网上的博客各有各的说法。根据后文采用的 Merkle Tree 方案,文中的第 0 层可能指的是上图中的 D a t a L a y e r \mathsf{Data\ Layer} Data Layer 数据层😇
与基于以太坊的区块链不同,后者在账本中只存在两种类型的交易:
- 由用户发行 i s s u e \mathsf{issue} issue 的交易;
- 由智能合约发行 i s s u e \mathsf{issue} issue 的交易;
A l g o r a n d \mathsf{Algorand} Algorand 设计并提供了更多类型的交易,其中包括创建代币、转让代币、修改代币的交易。每个区块链用户都可以是自己 NFT 集合 c o l l e c t i o n \mathsf{collection} collection 的发行者,或者一组用户可以联合起来发行由智能合约仲裁的公共 NFT 集合。
开发者可以编写智能合约,以确保只有位于发行者授权名单中的用户才能进行铸币操作,从而拒绝来自非授权用户的铸币交易。遵循 P 1 \mathbf{P1} P1 原则。 P 2 \mathbf{P2} P2 原则也是成立的,因为只有在产生交易的区块链用户拥有该代币时,代币转让交易才会成功。
然而,与 ERC-721 的情况不同,代币的管理并不是由智能合约逻辑控制的,而是由区块链共识控制的,它检查各种类型交易的有效性。因此,代币(如 A l g o r a n d \mathsf{Algorand} Algorand 中的 ASA)在系统中是通过在创建时由共识分配的数值索引唯一标识的。这个索引是由区块链验证者处理的一个计数器。因此,不能保证 i d \mathsf{id} id 不同的两个代币一定代表不同的数据。
综上所述, A l g o r a n d \mathsf{Algorand} Algorand 设计的方法不符合 F C o l l N F T \mathsf{F_{CollNFT}} FCollNFT,因为它不满足 P 3 \mathbf{P3} P3 原则。
1 方案一:利用修剪过的 Merkle Tree
考虑区块链上智能合约的能力,实现 F C o l l N F T \mathsf{F_{CollNFT}} FCollNFT 的一个潜在方法如下:
- 同属一个集合的代币通过一个智能合约创建;
- 该智能合约跟踪同属一个集合的、已创建的代币;
- 该智能合约在合法发行者的请求下铸造新代币;
在某些区块链中,智能合约对存储大小有约束。因此,管理 NFT 集合的智能合约应该在其状态中维护所有随时间发行的代币的简洁 s u c c i n c t \mathsf{succinct} succinct 表示。一个典型的简洁 s u c c i n c t \mathsf{succinct} succinct 表示是由 Merkle Tree 的根 r o o t \mathsf{root} root 组成的。
个人理解:智能合约属于应用层,Merkle Tree 属于数据层。我们之前是通过编写智能合约的逻辑来防止 NFT 集合的克隆,而这里是通过 Merkle Tree 查重来防止 NFT 集合的克隆。
按照以下方式将代币分配到 Merkle Tree 的各个 l e a f \mathsf{leaf} leaf 叶子节点。
考虑从根节点 r o o t \mathsf{root} root 到叶子节点 l e a f \mathsf{leaf} leaf 的路径。若当前节点是左子节点,则被分配 0 \mathsf{0} 0;若当前节点是右子节点,则被分配 1 \mathsf{1} 1。如此一来,每个叶子节点 l e a f \mathsf{leaf} leaf 都可以由一个 01 \mathsf{01} 01 字符串来表示。
个人脑补图:

如上图所示,叶子节点 C 被表示为 00,叶子节点 D 被表示为 01,叶子节点 E 被表示为 10,叶子节点 F 被表示为 11😇
当我们输入一个 01 \mathsf{01} 01 字符串时,便能在 Merkle Tree 上找到一个对应的叶子节点。
用字符串 s h a 256 ( t . d a t a ) \mathsf{sha256(t.data)} sha256(t.data) 表示代币 t \mathsf{t} t,通过使用上述程序,我们可以检查代币 t \mathsf{t} t 是否存在于 Merkle Tree 中。初始化,将树的根设置为 n i l \mathsf{nil} nil 空值,表示目前集合中还没有代币。为了添加一个新代币 t \mathsf{t} t,发行者首先必须证明 t \mathsf{t} t 不在集合中,即证明相应的叶子节点尚未被插入。
相应的叶子节点是指由字符串 s h a 256 ( t . d a t a ) \mathsf{sha256(t.data)} sha256(t.data) 标识的那个位置。
这很容易实现,只需从根开始按照 s h a 256 ( t . d a t a ) \mathsf{sha256(t.data)} sha256(t.data) 字符串所代表的路径行走,直至遇到 n i l \mathsf{nil} nil 空值才结束。 n i l \mathsf{nil} nil 空值代表路径中的下一子节点尚不存在。换句话说,发行者提供了一个证明,证明了从根到 s h a 256 ( t . d a t a ) \mathsf{sha256(t.data)} sha256(t.data) 的路径中有一个 n i l \mathsf{nil} nil 空值。如果代币可以被添加,那么智能合约将添加它并相应地更新 Merkle Tree 的根。
个人认为:字符串 s h a 256 ( t . d a t a ) \mathsf{sha256(t.data)} sha256(t.data) 既能代表相应的叶子节点,又能代表从根到该叶子节点的路径。
请注意,这并不是一个纯粹的 Merkle Tree,因为整个子树被修剪掉了。这实际上是出于效率考虑,因为我们无法计算完整的二叉树。具体来说,由于字符串 s h a 256 ( t . d a t a ) \mathsf{sha256(t.data)} sha256(t.data) 的长度是 256 位,因此叶子节点的数量将是 2 256 \mathsf{2^{256}} 2256 个!
什么叫做 “整个子树被修剪掉了”?原文貌似也没有讲。难道是不需要存储叶子节点吗🫠
对于某些区块链,如 A l g o r a n d \mathsf{Algorand} Algorand,实现此类过程的预期工作量可能是不切实际的。确实,一个智能合约似乎最大程度只能管理一个高度为 15 \mathsf{15} 15 的 Merkle Tree 。
个人理解:方案一要求的 Merkle Tree 岂不是高度要为 256?
NFT__75">2 方案二:在共识层防止 NFT 集合的克隆
由于通过智能合约编码来防止 NFT 集合克隆可能很有挑战性,特别是当底层区块链对智能合约的功能施加限制时,因此我们转而考虑该问题与区块链交易的有效性的关系。
实际上,防止克隆与在逻辑上判定某些交易无效是紧密联系的。所谓无效交易,是那些违反了区块链状态规则的交易。因此,对于那些支持 NFT 管理 m a n a g e m e n t \mathsf{management} management 交易的区块链(比如 A l g o r a n d \mathsf{Algorand} Algorand 中的 ASA),一个可行的策略是在共识层实施机制,拒绝那些试图铸造与集合中已有 NFT 相同的 NFT 的交易。为了实现这一目标,区块链的验证者可以采用类似以太坊中用于存储集合状态的数据结构(如键值映射)来进行验证。