说明
我前一篇博客《使用共振峰提取元音音素/从声音生成口型动画》探索了使用共振峰分析元音,然后从元音音素映射到视位的口型驱动方案。当时我就在想,如果能用深度学习法方法从音频直接生成音素流,然后转换成对应视位,不就很容易做口型动画了吗。通过网络检索,发现Visemenet这个方案就是我要的,而且被引用还蛮多的。算是用深度学习生成音素的经典文章。通过阅读论文和代码,我初步熟悉了它的思路。这里来纪录下。
什么是JALI
JALI是英文单词下巴(JAW)和嘴唇(LIP)的合并简写,也是一个动画工具的名字,他们的官网是:https://jaliresearch.com/
看官网资料,他们主要是做口型动画的,他们的主要方法和概念在论文《JALI: An Animator-Centric Viseme Model for Expressive Lip Synchronization》里有介绍。他们通过观察发现,人们发音时的动作有两个重要维度,一是下巴骨骼的运动,二是嘴部肌肉的运动。而不同的说话"风格",可以通过调整这两个维度从而捕捉到更有表达力的口型。
比如同一个人用不同的情绪来发同一个音素,其口型差距巨大。不同的发音方法对应的嘴唇宽度和下巴位移量都不一样。
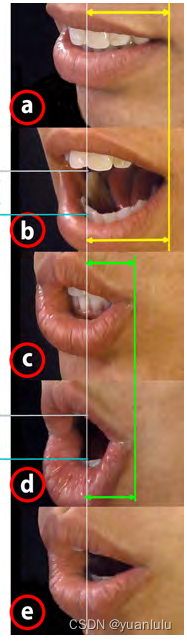
在JALI的坐标轴中,五种风格的发音分布如下。其横坐标是下巴位移,纵坐标是嘴唇形变。
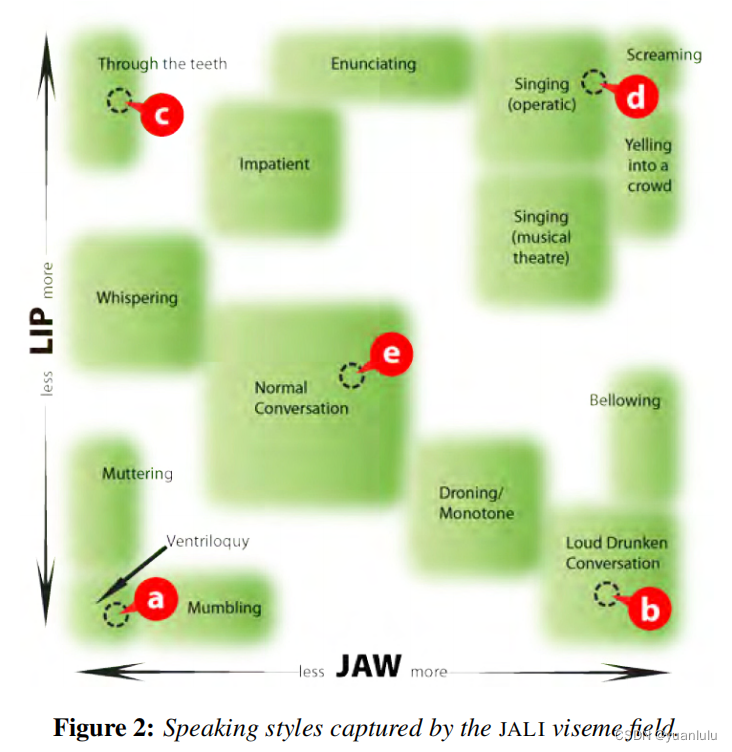
当然,除了下巴和嘴唇宽度,正常的视位口型还是需要的。
JALI的论文中貌似是使用TTS软件来识别音素,使用算法将音素和音频对齐,然后根据总结的一些协同发音的规则来制作口型的动画。
JALI技术已经在大型RPG游戏《赛博朋克2077》中有了实际运用。游戏十余种本地化配音中的每一个字,都通过JALI技术实现了从语音到面部动画与口型的同步。
但是JALI的工作流还依赖人工总结的规则,需要手工介入调整。一种更自然的方案就是让深度学习来学习音素权重及曲线,这就是Visemenet的工作。
Visemenet
Visemenet主要是用深度学习的方法端到端生成JALI绑定模型口型的参数,较少人员的介入。
JALI的论文最后面,它说它使用的音素和苹果的开发文档里一致,我搜索到苹果的因素定义,不知道有多少个。Visemenet使用了因素组,因为多个因素对应的视位口型差不多,就将它们分为一类,减少动画建模的工作量。Visemenet使用了20个音素组:
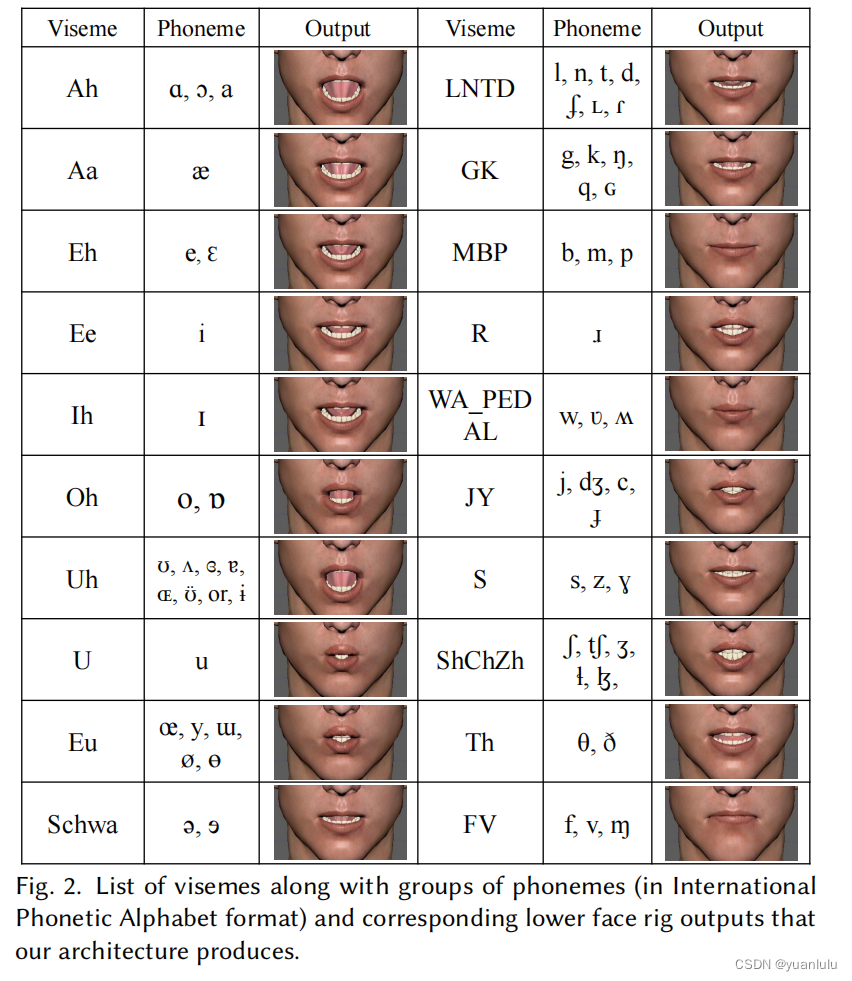
此外,Visemenet还会使用人脸关键点作为监督。整体流程如下
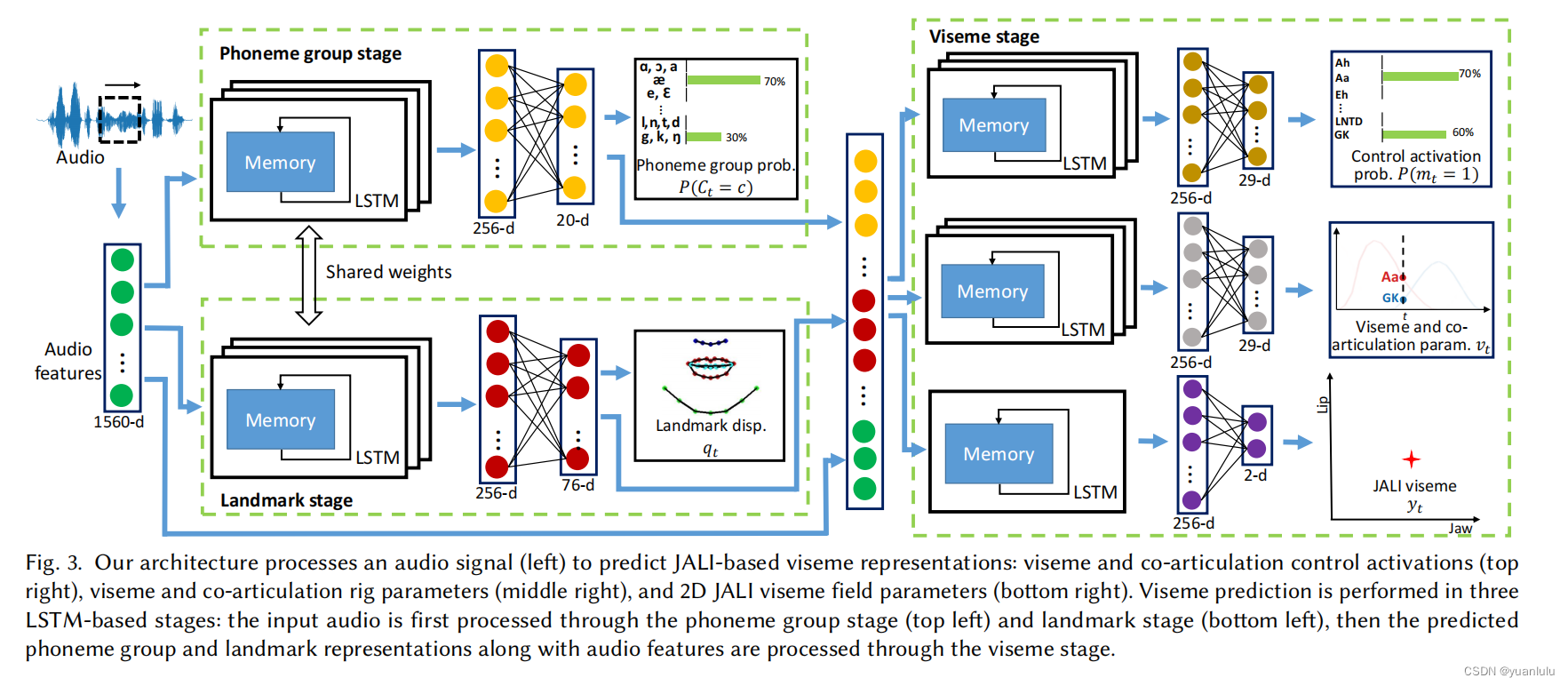
可以看到,输入就是音频,经过LSTM会生成因素组和关键点的表征,这些表征和音频数据组合在一起,最后再输出因素分类,音素权重(类似动画曲线)及JA和LI。
代码使用
关键点动画效果
github上有Visemenet第一作者开源的一份代码yzhou359/VisemeNet_tensorflow,但是代码是tf1.1版本的,很难搭环境。github上有人将它移植到tf2.的环境中,并提供了从原作者仓中冻结的模型:junhwanjang/visemenet-inference
我主要使用junhwanjang/visemenet-inference来体验使用的。体验过程中我将模型中间过程的关键点做成了视频,我传到了b站上,效果如下:
https://www.bilibili.com/video/BV19t421c777/?vd_source=8abb7f0122649239c41b4c8acf458e47
关键点的布局如下:
整体上来说,效果不是很好。为啥不好,我后面会分析。
推理代码流程
下面以一份33.45秒的视频的处理流程为例,接一下我理解的Visemenet的代码推理流程。它的采样率是16K,采样总数535200。
音频特征提取
使用python_speech_features工具包提取了logfbank, mfcc, ssc这三种特征后拼接在一起,这三种特征的帧步都是10ms,提取维度分别是26,13和26,拼接后最后一维是65.
音频特征提取完,变成了形状为(3344, 65)的特征。
推理前的其它处理
进入网络前,还需要进行正则化和按照24的宽度进行窗口重排数据,最终音频数据的形状变为(3344, 8, 195),同时还要读取人脸关键点的基准位置,形状为(3344, 76)
推理
网络的输入数据除了音频特征和人脸关键点,还有phase 和dropout ,推理时这两个数据默认为0
x = self.graph.get_tensor_by_name('input/Placeholder_1:0') #音频信号x_face_id = self.graph.get_tensor_by_name('input/Placeholder_2:0') #人脸关键点默认位置phase = self.graph.get_tensor_by_name('input/phase:0') # 0dropout = self.graph.get_tensor_by_name('net1_shared_rnn/Placeholder:0') # 0## Output nodesv_cls = self.graph.get_tensor_by_name('net2_output/add_1:0')v_reg = self.graph.get_tensor_by_name('net2_output/add_4:0')jali = self.graph.get_tensor_by_name('net2_output/add_6:0')land = self.graph.get_tensor_by_name("net1_output/add_2:0") #第一阶段关键点,这是我自己加的pho = self.graph.get_tensor_by_name("net1_output/net1_pho_relu:0") #第一阶段音素,这是我自己加的print("---------------predict_outputs 6---------------")with tf.compat.v1.Session(graph=self.graph) as sess:pred_v_cls, pred_v_reg, pred_jali, pre_land, pre_pho = sess.run([v_cls, v_reg, jali, land, pho],feed_dict={x: batch_x, x_face_id: batch_x_face_id,dropout: 0, phase: 0})pred_v_cls = self.sigmoid(pred_v_cls)
为了输出第一阶段的因素组特征和人脸关键点,我加了两行代码。需要注意的是pho的形状是(3344, 256),并不是20个因素组的分类。我前面制作的关键点的动画就是用pre_land输出的结果制作的。
输出
输出的tensor有3个
pred_v_cls.shape:(3312, 20)
pred_v_reg.shape:(3312, 20)
pred_jali.shape:(3312, 2)
其中pred_v_cls表示音素组的分类概率,pred_v_reg表示音素的权重曲线,用来制作动画。pred_jali表示下巴和嘴唇的变形权重。
注意这里第一维少了32(从3344变为3312),我试了两段音频都是这个结果,不清楚是什么原因。这部分数据对应时间是320ms。
这里数据的维度和上面框架图中的29d对不上。
后处理及整体效果
后处理函数会对pred_v_cls、pred_v_reg和pred_jali进行多次滤波和平滑,最终得到一个形状为(3312, 22)的数据作为最终结果,第二维的前2个表示JA和LI的权重,后20个表示20个因素组的曲线变化。
我将JALI和音素组的曲线画出来了,可以发现效果并不好。其中JA和LI的权重基本是平的。
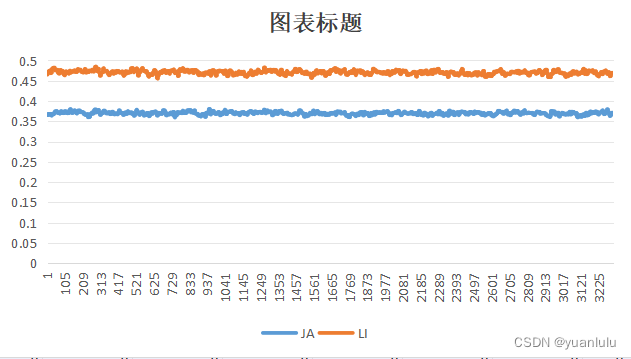
20个因素组,基本只有4-5个音素在一直表达,其它的都基本为0.通过网络中间生成的关键点来生成视频的效果也不是很好,所以我对Visemenet开源的模型效果表示不很满意。

小结
写累了,就这样吧。本来打算用visemenet做动画的,还不如我的共振峰的效果。
参考资料
JALI: An Animator-Centric Viseme Model for Expressive Lip Synchronization
VisemeNet: Audio-Driven Animator-Centric Speech Animation
语音生成口型与表情技术的演进与未来
Visemenet作者开源:yzhou359/VisemeNet_tensorflow
Visemenet可以运行的例子tf2.0:junhwanjang/visemenet-inference
使用共振峰提取元音音素/从声音生成口型动画
JALI官网:https://jaliresearch.com/