1、and 和 or的并列运用[先看and]
条件1 OR 条件2 AND 条件3
执行顺序是先执行AND操作符(先看条件2和3),再根据其结果判断是否需要执行OR操作符,并最终返回整个表达式的逻辑结果。
条件1 and 条件2 or 条件3
执行逻辑是先执行AND操作符,并根据其结果再判断是否需要执行OR操作符,最终返回整个表达式的逻辑结果。
2、条形图vs直方图
直方图是看数据分布的,坐标之间是连续的,组距基本相同,高度是(频数/频率)/组距。面积=频数/频率
条形图和柱状图一个横一个竖,长短或高低表征数量。
3、堆积面积图
EX:不同活跃频次的用户贡献的APP时长的比例变化
4、经典假阳题
题目:假设有一种病毒,它的携带率为1/2000。有一种化验方法可以精准地检测到这种病毒,也就是说,如果一个人携带这种病毒,一定可以被检测出来。但是该项化验的假阳性率为1%,即健康人接受该项化验,会有1%的可能性被误诊为病毒携带者。假设从人群中随机选择一人进行检测,化验结果为阳性(阳性意味着受检者可能是该病毒携带者)。那么,在不考虑其它变量的情况下,此人携带该病毒的概率接近:5%
| 真阳 | 真阴 | |
| 测阳 | m | 20m |
| 测阴 | 0 | 1980m |
| m | 2000m |
5、正负样本不均衡(正10万负100万)
对正样本进行重复抽
从100万负样本中随机抽取10万
正样本的权重设置为10,负样本权重设置为1
将所有数据加入训练集,充分利用全部数据【错】
6、问答题——创作者与粉丝关系强度
题目:创作者和粉丝的关系是社区内的比较重要的关系,我们需要对这些关系进行研究,作用在内容分发上,让社区创作者和用户获得更好的体验。 不同粉丝与作者之间的关系强度会有很大差异,我们可以通过他们之间的行为、特征来刻画关系强度。 如果是你,你会如何划分关系的强弱:包括选择什么特征,为什么,如何划分强度,如果涉及到模型/算法,也请对模型的基本原理和步骤进行简要阐述。
回答:
对于创作者和粉丝之间的关系强度划分,我会选择以下特征并结合机器学习算法进行建模:
1. **互动频率**:包括粉丝对作者发表内容的评论、点赞、分享等行为频率。互动频率高的关系可能更为密切。
2. **关注持续时间**:粉丝对作者的关注时间长短可以反映出关系的稳定程度。
3. **内容亲和度**:粉丝对作者发表内容的喜好程度,可以通过对粉丝喜欢的内容主题、创作者风格等进行分析。
4. **社交网络交互**:粉丝与作者之间是否有共同的关注对象或社交圈子,共同的社交网络可能促进关系的建立。
为了划分关系的强度,可以使用机器学习算法如决策树、随机森林、逻辑回归等进行建模和预测。具体步骤如下:
1. 数据采集:收集创作者和粉丝之间的互动数据、关注数据、内容喜好等特征数据。
2. 数据预处理:对数据进行清洗、去噪、特征选择等处理,保证数据质量和特征的有效性。
3. 模型训练:将数据集划分为训练集和测试集,选择适合的机器学习算法,对模型进行训练,并调优模型参数。
4. 模型评估:通过评价指标如准确率、召回率、F1值等来评估模型的性能和效果。
5. 关系划分:根据模型预测结果和关系特征,可以将创作者和粉丝之间的关系划分为强、中、弱等不同强度。
通过对创作者和粉丝关系的强度进行划分和分析,社区可以更好地了解用户兴趣和需求,提供更加个性化和优质的内容推荐和体验,从而增加用户黏性和社区活跃度。
mememe:
关于创作者和粉丝的关系强度的划分
一、特征选择
创作者的粉丝对其发帖数进行点赞收藏阅读的数量占其总发帖数的比例在一定程度上可以衡量关系强度。
二、如何划分强度
根据粉丝对其发帖数进行点赞收藏阅读的数量占其总发帖数的比例可以衡量关系强度,但这应当会考虑到创作者本身的发帖数量,
对于发帖频率较高的人来说,可能这个比例不需要那么高;对于发帖频率比较低的创作者来说,这种比率要高一点才能够说明关系强度较强。
除了考虑发帖频率以外,还要考虑时间的问题,有些粉丝在最初关注创作者的时候可能关系强度较强,可是可能在之后的时间就可能变得并不活跃,因而时间方面关注近期可能更合理一点。
三、模型选择与基本步骤的阐述
1、按照近三个月的发帖数量,将排名在前30%的创作者定义为发帖频率高;后30%的定义为发帖频率低;其余40%定义为发帖频率中等。
2、对于发帖频率高、中、低的创作者人群分别计算每位分析近3个月内对其发帖数进行点赞收藏阅读的数量占其总发帖数的比例,对3类人群分别计算均值,如果该创作者的比例均值大于其所属人群的比例均值,则可理解为关系强;否则可记为关系强度弱。由此便可对每位创作者给出关系强度强弱的指标。
7、问答题——业务场景与指标
问题:请基于知乎 app 中 3 个业务场景(首页推荐、热榜、搜索)回答:请简述三个场景分别满足用户什么样的需求,差异是什么?10分基于你的理解,3个场景用户规模大致是什么样的比例关系?哪个场景用户留存最高?请分别给出你的理由; 10分建立一套指标体系来监控「热榜」场景的业务状态,简述各指标设立的依据。15分
回答:
答案:
1. 首页推荐:首页推荐场景满足用户的主要需求是获取最新最热门的知识内容,帮助用户及时了解各领域的热点话题,扩展用户的知识面。用户在首页推荐中可以随时了解到其他用户关注的内容,方便获取知识信息。
2. 热榜:热榜场景满足用户的需求是浏览当前热门话题和内容,查看大家热议的内容,了解当前社会热点。用户在热榜中可以看到当前最受欢迎的话题、内容或问题,掌握社会热点动态。
3. 搜索:搜索场景满足用户的需求是精准地找到自己感兴趣的内容,快速获取需要的信息。用户通过搜索可以方便地找到特定话题、用户或问题,提高信息检索的效率。
在知乎 app 中,用户规模大致是首页推荐 > 搜索 > 热榜。首页推荐具有最大的用户规模,因为它是用户打开知乎 app 时首先看到的页面,吸引用户浏览最新内容。用户留存最高的场景可能是首页推荐,因为用户频繁打开知乎 app 查看最新内容,保持了较高的活跃度。
建立一个指标体系来监控「热榜」场景的业务状态可以包括以下指标:
1. 热度排名:监测当前热榜内容的排名情况,了解哪些话题或内容受关注程度高。
2. 点击率:监测用户对热榜内容的点击情况,了解用户对不同话题的兴趣程度。
3. 留存率:监测用户在浏览热榜内容后的留存情况,了解用户是否持续关注热门话题。
4. 互动度:监测热榜内容的评论数、点赞数等互动数据,了解用户参与讨论的程度。
5. 阅读时长:监测用户在热榜内容上停留的时长,了解用户对不同内容的阅读深度。
mememe:知乎APP中的业务场景——首页推荐、热榜、搜索
一、三个场景满足的需求与差异
首页推荐满足的是用户的关注领域和喜好内容的需求,对每位用户来说是一种个性化定制的需求。热榜针对的是所有用户或者社会共同关注的焦点问题,突出的是共性。搜索满足的是用户对所求问题给予解决方式的需求,希望能够对用户所提的问题给与全面且准确的回答。
二、用户规模与用户留存率
基于我的理解,首页推荐和搜索的用户留存率最高,热榜此之。因为用户使用知乎主要是关注别人对某个领域问题的回答,或者寻求一些问题的回答。
三、指标体系的建立
1、用户点击率
用户点击率能够监控用户对热榜的标题是否感兴趣
2、相关话题阅读量
这个指标能够监控用户在阅读完某个热榜之后,是否会接着在关注该领域的其他问题,能够检测热榜下的话题是否足够有吸引力和深度。
8、VLOOKUP函数


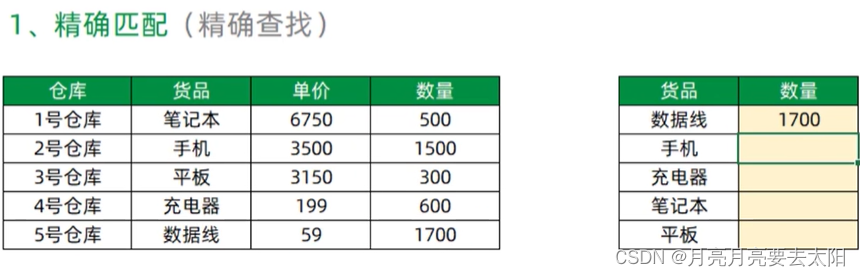
精确查找的语法:=VLOOKUP(G17,货品单价数量,3,精确查找)
在货品中找到了数据列,并返回了它对应的数量。
反向查找——复制过去
多条件查找——构建辅助列
屏蔽错误值——=IFERROR(VLOOKUP(...),'')
关键字查找——利用通配符——关于查找值可以"*"&E17&"*"
文本和数值的混合查找——数字变成文本""&E17&""——文本变数字E17*1【乘1强制转换数字】
去除空格查找——VLOOKUP(SUBSTITUTE(E17," ",""),)【SUBSTITUTE(E17,被替换的,替换什么)】
去除不可见的字符——CLEAN()