目录
题目描述
给定一个二叉树,找出其最小深度。最小深度是从根节点到最近叶子节点的最短路径上的节点数量。说明:叶子节点是指没有子节点的节点。
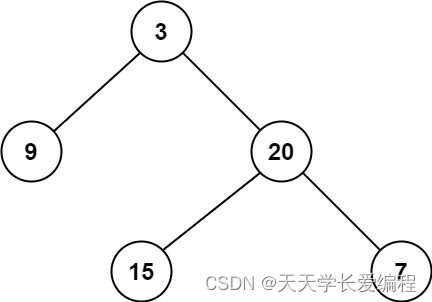
示例 1:输入:root = [3,9,20,null,null,15,7]
输出:2
示例 2输入:root = [2,null,3,null,4,null,5,null,6]
输出:5提示:树中节点数的范围在 [0, 105] 内
-1000 <= Node.val <= 1000
原题:LeetCode 111
思路及实现
DFS_35">方式一:深度优先搜索(DFS)
思路
对于深度优先搜索,我们可以从根节点开始递归遍历整棵树。对于每个节点,我们检查它是否是叶子节点(即没有左子树或右子树)。如果是叶子节点,我们返回1作为当前路径的深度。否则,我们递归地计算左子树和右子树的最小深度,并返回两者中的较小值加1(加1是因为我们要考虑当前节点)。
需要注意的是,如果当前节点只有一个子树(即左子树或右子树为空),我们不能简单地返回另一个子树的最小深度加1。这是因为在这种情况下,我们需要继续沿着当前子树向下搜索,直到找到叶子节点。
代码实现
Java版本
java">class TreeNode {int val;TreeNode left;TreeNode right;TreeNode(int x) { val = x; }
}public class Solution {public int minDepth(TreeNode root) {if (root == null) {return 0;}if (root.left == null && root.right == null) {// 叶子节点return 1;}int leftDepth = Integer.MAX_VALUE;int rightDepth = Integer.MAX_VALUE;if (root.left != null) {// 递归计算左子树的最小深度leftDepth = minDepth(root.left);}if (root.right != null) {// 递归计算右子树的最小深度rightDepth = minDepth(root.right);}// 返回左右子树中较小值加1return Math.min(leftDepth, rightDepth) + 1;}
}
说明:
- 我们首先处理根节点为空的情况,直接返回0。
- 然后检查根节点是否为叶子节点,如果是则返回1。
- 对于非叶子节点,我们初始化左右子树的最小深度为
Integer.MAX_VALUE。- 递归地计算左子树和右子树的最小深度,并更新相应的变量。
- 最后返回左右子树中较小值加1作为当前树的最小深度。
C语言版本
#include <limits.h>struct TreeNode {int val;struct TreeNode *left;struct TreeNode *right;
};int minDepth(struct TreeNode* root) {if (root == NULL) {return 0;}if (root->left == NULL && root->right == NULL) {return 1;}int leftDepth = INT_MAX;int rightDepth = INT_MAX;if (root->left != NULL) {leftDepth = minDepth(root->left);}if (root->right != NULL) {rightDepth = minDepth(root->right);}return (leftDepth < rightDepth) ? (leftDepth + 1) : (rightDepth + 1);
}
说明:
- C语言版本与Java版本类似,但使用了
INT_MAX来初始化左右子树的最小深度。- 注意C语言中结构体指针的使用以及递归调用的语法。
Python3版本
class TreeNode:def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightclass Solution:def minDepth(self, root: TreeNode) -> int:if not root:return 0if not root.left and not root.right:return 1leftDepth = float('inf')rightDepth = float('inf')if root.left:leftDepth = self.minDepth(root.left)if root.right:rightDepth = self.minDepth(root.right)# 返回左右子树中较小值加1return min(leftDepth, rightDepth) + 1
说明:
- Python版本使用了
float('inf')来初始化左右子树的最小深度,因为Python中没有内置的INT_MAX。- Python中的类定义和递归调用语法与Java和C语言略有不同。
Golang版本
package maintype TreeNode struct {Val intLeft *TreeNodeRight *TreeNode
}func minDepth(root *TreeNode) int {if root == nil {return 0}if root.Left == nil && root.Right == nil {return 1}leftDepth, rightDepth := math.MaxInt32, math.MaxInt32if root.Left != nil {leftDepth = minDepth(root.Left)}if root.Right != nil {rightDepth = minDepth(root.Right)}if leftDepth == math.MaxInt32 {return rightDepth + 1}if rightDepth == math.MaxInt32 {return leftDepth + 1}return int(math.Min(float64(leftDepth), float64(rightDepth))) + 1
}import ("fmt""math"
)func main() {// 这里可以添加测试代码
}
说明:
- Golang版本使用了
math.MaxInt32来初始化左右子树的最小深度。- Golang中的结构体定义和递归调用语法与其他语言有所不同。
- 使用了
math.Min函数来比较两个整数的大小,因为Golang没有内置的min函数。
复杂度分析
- 时间复杂度:O(n),其中n是二叉树的节点数。在最坏的情况下,我们需要遍历整棵树的所有节点。
- 空间复杂度:O(h),其中h是二叉树的高度。这是因为递归调用栈的深度最大为二叉树的高度。在极端情况下(例如退化为链表时),空间复杂度为O(n)。
BFS_208">方式二:广度优先搜索(BFS)
思路
广度优先搜索可以通过层序遍历的方式找到二叉树的最小深度>二叉树的最小深度。我们从根节点开始,将根节点入队,然后进入一个循环,每次从队列中取出一个节点,检查该节点是否为叶子节点。如果是,返回当前遍历的层数。如果不是,将节点的左右子节点(如果存在)入队,并继续下一层的遍历。
代码实现
Java版本
java">import java.util.LinkedList;
import java.util.Queue;class TreeNode {int val;TreeNode left;TreeNode right;TreeNode(int x) { val = x; }
}public class Solution {public int minDepth(TreeNode root) {if (root == null) {return 0;}Queue<TreeNode> queue = new LinkedList<>();queue.offer(root);int depth = 1;while (!queue.isEmpty()) {int size = queue.size();for (int i = 0; i < size; i++) {TreeNode node = queue.poll();if (node.left == null && node.right == null) {return depth;}if (node.left != null) {queue.offer(node.left);}if (node.right != null) {queue.offer(node.right);}}depth++;}return depth;}
}
说明:
- 我们使用了
Queue来进行层序遍历。depth变量用于记录当前遍历的层数。- 在每一层遍历时,我们记录当前层的节点数量,并遍历这些节点。这样可以确保我们在同一层内处理完所有节点后才进入下一层。
- 如果遇到一个叶子节点,我们返回当前的
depth。
C语言版本
C语言标准库没有直接提供队列数据结构,但我们可以使用数组或者链表来模拟队列的行为。以下是一个使用数组模拟队列的示例:
#include <stdio.h>
#include <stdbool.h>typedef struct TreeNode {int val;struct TreeNode *left;struct TreeNode *right;
} TreeNode;typedef struct {TreeNode **data;int front;int rear;int capacity;
} Queue;Queue* createQueue(int capacity) {Queue *queue = (Queue*)malloc(sizeof(Queue));queue->data = (TreeNode**)malloc(capacity * sizeof(TreeNode*));queue->front = 0;queue->rear = -1;queue->capacity = capacity;return queue;
}bool isQueueEmpty(Queue *queue) {return queue->front > queue->rear;
}bool isQueueFull(Queue *queue) {return queue->rear == queue->capacity - 1;
}void enqueue(Queue *queue, TreeNode *node) {if (isQueueFull(queue)) {printf("Queue is full\n");return;}queue->rear++;queue->data[queue->rear] = node;
}TreeNode* dequeue(Queue *queue) {if (isQueueEmpty(queue)) {printf("Queue is empty\n");return NULL;}TreeNode *node = queue->data[queue->front];queue->front++;return node;
}int minDepth(TreeNode *root) {if (root == NULL) {return 0;}Queue *queue = createQueue(1000); // 假设队列足够大enqueue(queue, root);int depth = 1;while (!isQueueEmpty(queue)) {int size = queue->rear - queue->front + 1;for (int i = 0; i < size; i++) {TreeNode *node = dequeue(queue);if (node->left == NULL && node->right == NULL) {free(queue); // 释放队列内存return depth;}if (node->left != NULL) {enqueue(queue, node->left);}if (node->right != NULL) {enqueue(queue, node->right);}}depth++;}free(queue); // 如果队列不为空,则在此处释放return depth;
}// 辅助函数,用于创建树和测试
// ...int main() {// 创建测试树// ...// 调用minDepth函数并打印结果// ...return 0;
}
说明:
Queue结构体用于模拟队列,包含数据数组、队首和队尾指针,以及队列容量。createQueue用于初始化队列。isQueueEmpty和isQueueFull分别检查队列是否为空或满。enqueue和dequeue分别用于入队和出队操作。minDepth函数中的逻辑与Java版本相似,但使用了自定义队列来实现层序遍历。
Python3版本
from collections import dequeclass TreeNode:def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightdef minDepth(root):if not root:return 0queue = deque([root])depth = 1while queue:size = len(queue)for _ in range(size):node = queue.popleft()if not node.left and not node.right:return depthif node.left:queue.append(node.left)if node.right:queue.append(node.right)depth += 1return depth# 示例用法
# root = TreeNode(3)
# root.left = TreeNode(9)
# root.right = TreeNode(20)
# root.right.left = TreeNode(15)
# root.right.right = TreeNode(7)
# print(minDepth(root)) # 输出:2
说明:
- Python使用
collections.deque双端队列来实现广度优先搜索。
C++ 版本
在C++中,我们通常会使用标准库中的std::queue来模拟队列,或者使用std::deque作为双端队列来更高效地进行入队和出队操作。以下是使用std::queue实现的C++代码:
#include <iostream>
#include <queue>struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};int minDepth(TreeNode* root) {if (root == nullptr) {return 0;}std::queue<TreeNode*> q;q.push(root);int depth = 1;while (!q.empty()) {int size = q.size();for (int i = 0; i < size; ++i) {TreeNode* node = q.front();q.pop();if (node->left == nullptr && node->right == nullptr) {return depth;}if (node->left != nullptr) {q.push(node->left);}if (node->right != nullptr) {q.push(node->right);}}depth++;}return depth;
}// 辅助函数,用于创建树和测试
// ...int main() {// 创建测试树// TreeNode* root = new TreeNode(3);// root->left = new TreeNode(9);// root->right = new TreeNode(20);// root->right->left = new TreeNode(15);// root->right->right = new TreeNode(7);// 调用minDepth函数并打印结果// int minDepthResult = minDepth(root);// std::cout << "Minimum depth of tree is: " << minDepthResult << std::endl;// 释放树节点内存// ...return 0;
}
说明:
TreeNode结构体定义了一个二叉树节点。minDepth函数使用std::queue来存储待处理的节点,并使用层序遍历来查找最小深度。- 在
while循环中,我们先获取当前层的节点数,然后遍历这些节点,对每个节点进行处理,并将其子节点(如果有的话)加入到队列中。- 当遇到一个叶子节点(没有左右子节点)时,返回当前的深度。
- 注意:在实际应用中,还需要编写额外的代码来释放创建的树节点的内存,以避免内存泄漏。
Golang 版本
在Go语言中,没有内置的队列数据结构,但我们可以使用切片(slice)来模拟队列的行为。下面是一个使用切片来实现二叉树最小深度计算的Go语言版本代码:
package mainimport ("fmt"
)type TreeNode struct {Val intLeft *TreeNodeRight *TreeNode
}func minDepth(root *TreeNode) int {if root == nil {return 0}queue := []*TreeNode{root}depth := 1for len(queue) > 0 {size := len(queue)for i := 0; i < size; i++ {node := queue[0]queue = queue[1:]if node.Left == nil && node.Right == nil {return depth}if node.Left != nil {queue = append(queue, node.Left)}if node.Right != nil {queue = append(queue, node.Right)}}depth++}return depth
}func main() {// 构造测试用的二叉树root := &TreeNode{Val: 3}root.Left = &TreeNode{Val: 9}root.Right = &TreeNode{Val: 20}root.Right.Left = &TreeNode{Val: 15}root.Right.Right = &TreeNode{Val: 7}// 调用函数并打印结果minDepthResult := minDepth(root)fmt.Printf("Minimum depth of tree is: %d\n", minDepthResult)
}
说明
在这个Go语言版本的代码中,我们定义了一个TreeNode结构体来表示二叉树的节点。minDepth函数使用切片来存储待处理的节点,通过层序遍历来查找二叉树的最小深度>二叉树的最小深度。
在main函数中,我们创建了一个测试用的二叉树,并调用minDepth函数来计算其最小深度,然后将结果打印出来。
请注意,在实际应用中,可能需要处理树的构建和节点内存的释放,但在上述示例中,我们主要关注最小深度计算的实现。如果需要动态构建树,可以使用循环或递归的方式添加节点;释放内存时,则需要遍历树并逐个释放每个节点的内存。
总结
以下是使用深度优先搜索(DFS)和广度优先搜索(BFS)两种方式实现二叉树最小深度计算的总结表格。请注意,这里我们只对比DFS和BFS两种算法在解决二叉树最小深度问题时的特点,不涉及具体语言实现。
| 方式 | 优点 | 缺点 | 时间复杂度 | 空间复杂度 | 其他 |
|---|---|---|---|---|---|
| DFS | 代码相对简洁 | 可能会遍历不必要的节点 | O(n) | O(h),h为树的高度 | 适用于树不平衡的情况 |
| BFS | 直观且易于理解 | 需要使用队列,可能增加代码复杂度 | O(n) | O(n) | 适用于树平衡或接近平衡的情况 |
- 优点:DFS的代码通常比较简洁,因为它递归地访问每个节点,可以很容易地利用递归的性质。在树结构较为不平衡的情况下,DFS可能具有更好的性能,因为它可以更早地找到最小深度。
- 缺点:DFS可能会遍历一些不必要的节点,特别是在寻找最小深度时,如果提前遇到叶子节点,那么继续递归访问其他分支是没有意义的。此外,DFS在处理大规模树时可能会导致栈溢出,尽管这在实践中并不常见。
- 时间复杂度:O(n),其中n是树中节点的数量。在最坏情况下,DFS需要访问树中的所有节点。
- 空间复杂度:O(h),其中h是树的高度。这是由递归调用栈的深度决定的。在平衡树中,h为logn,因此空间复杂度为O(logn)。但在最坏情况下(树完全不平衡),h可能接近n,此时空间复杂度为O(n)。
- 优点:BFS通过逐层遍历树来找到最小深度,因此非常直观且易于理解。在树结构平衡或接近平衡的情况下,BFS通常具有更好的性能,因为它可以更快地找到最小深度。
- 缺点:BFS需要使用队列来存储待访问的节点,这可能会增加代码的复杂度。此外,队列需要额外的空间来存储节点,因此在空间复杂度上可能不如DFS。
- 时间复杂度:O(n),其中n是树中节点的数量。BFS同样需要访问树中的所有节点才能找到最小深度。
- 空间复杂度:O(n)。在最坏情况下,当树完全不平衡时,BFS可能需要存储所有的节点在队列中,因此空间复杂度为O(n)。在平衡树中,虽然队列中的节点数量会有所减少,但空间复杂度仍然是O(n),因为需要存储整层的节点。
其他
- DFS和BFS都是解决二叉树最小深度问题的有效方法,选择哪种方法取决于具体的应用场景和树的结构。在不知道树是否平衡的情况下,BFS通常是一个更安全的选择,因为它总是按照层的顺序遍历树。然而,在某些特定情况下,如树非常不平衡时,DFS可能会更加高效。
- 在实际应用中,还需要考虑其他因素,如内存使用、代码可读性和可维护性等。这些因素可能会影响最终选择哪种方法来实现二叉树最小深度计算。
相似题目
以下是一些与计算二叉树最小深度相似的题目:
| 相似题目 | 难度 | 链接 |
|---|---|---|
| 二叉树的最大深度 | 简单 | LeetCode 104 |
| 最短路径长度(图论) | 中等 | LeetCode 743 |
| 最小路径和(二叉树) | 中等 | LeetCode 111 |
| 最小路径和(网格图) | 中等 | LeetCode 64 |
| 从根到叶的二进制数之和 | 中等 | LeetCode 1022 |
这些题目都涉及到树的遍历和路径计算,通过解决这些问题,可以进一步加深对树形结构理解和相关算法的应用。