LLM,全称Large Language Model,即大型语言模型。LLM是一种强大的人工智能算法,它通过训练大量文本数据,学习语言的语法、语义和上下文信息,从而能够对自然语言文本进行建模。这种模型在自然语言处理(NLP)领域具有广泛的应用,包括文本生成、文本分类、机器翻译、情感分析等。本文将详细介绍LLM大语言模型的原理、发展历程、训练方法、应用场景和未来趋势。
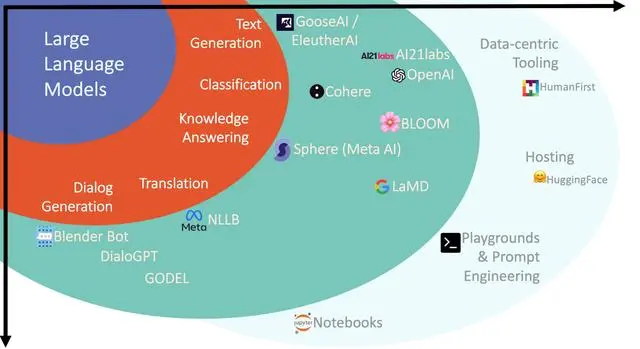
1.原理
LLM大语言模型的核心思想是通过训练大量文本数据,学习语言的语法、语义和上下文信息。这些模型通常采用深度学习技术,例如神经网络,来学习文本数据中的模式和规律。在训练过程中,模型会不断优化其参数,以提高对文本数据的建模能力。

2.发展历史
(1)2020年9月,OpenAI授权微软使用GPT-3模型,微软成为全球首个享用GPT-3能力的公司。2022年,Open AI发布ChatGPT模型用于生成自然语言文本。2023年3月15日,Open AI发布了多模态预训练大模型GPT4.0。
(2)2023年2月,谷歌发布会公布了聊天机器人Bard,它由谷歌的大语言模型LaMDA驱动。2023年3月22日,谷歌开放Bard的公测,首先面向美国和英国地区启动,未来逐步在其它地区上线。
(3)2023年2月7日,百度正式宣布将推出文心一言,3月16日正式上线。文心一言的底层技术基础为文心大模型,底层逻辑是通过百度智能云提供服务,吸引企业和机构客户使用API和基础设施,共同搭建AI模型、开发应用,实现产业AI普惠。
(4)2023年4月13日,亚马逊云服务部门在官方博客宣布推出Bedrock生成式人工智能服务,以及自有的大语言模型泰坦(Titan)。
(5)2024年3月,Databricks 推出大语言模型 DBRX,号称“现阶段最强开源 AI”。
(6)2024年4月,在瑞士举行的第27届联合国科技大会上,世界数字技术院(WDTA)发布了《生成式人工智能应用安全测试标准》和《大语言模型安全测试方法》两项国际标准,是由OpenAI、蚂蚁集团、科大讯飞、谷歌、微软、英伟达、百度、腾讯等数十家单位的多名专家学者共同编制而成。

3.发展历程
大型语言模型的发展历程可以分为三个阶段:统计机器翻译、深度学习和预训练模型。
(1)统计机器翻译:在21世纪初,统计机器翻译(SMT)成为自然语言处理领域的主流方法。SMT方法基于统计学原理,通过分析大量双语文本数据,学习源语言和目标语言之间的映射关系。然而,SMT方法在处理长句子和复杂语言结构时存在局限性。
(2)深度学习:随着深度学习技术的发展,神经网络模型开始应用于自然语言处理领域。2013年,word2vec模型的提出标志着词嵌入技术的诞生。词嵌入将词汇映射为低维向量,能够捕捉词汇的语义信息。此后,循环神经网络(RNN)、长短时记忆网络(LSTM)和门控循环单元(GRU)等模型相继应用于自然语言处理任务。
(3)预训练模型:2018年,谷歌提出了BERT(Bidirectional Encoder Representations from Transformers)模型,开启了预训练模型的时代。BERT模型采用双向Transformer结构,通过预训练学习语言的深层表示。随后,各种基于Transformer的预训练模型不断涌现,如GPT、RoBERTa、XLNet等。这些模型在自然语言处理任务上取得了显著的性能提升。

4.训练方法
大型语言模型的训练方法主要包括预训练和微调两个阶段。
(1)预训练:预训练阶段旨在学习语言的通用表示。预训练任务包括语言建模、掩码语言建模、下一句预测等。在预训练过程中,模型通过学习大量文本数据,优化其参数,提高对文本数据的建模能力。
(2)微调:微调阶段针对具体任务对预训练模型进行优化。微调任务可以是文本分类、机器翻译、情感分析等。在微调过程中,模型在特定任务的数据集上进行训练,调整其参数,以适应任务需求。

5.应用场景
(1)文本生成:大型语言模型可以生成各种类型的文本,如新闻报道、故事、诗歌等。这些应用可以用于内容创作、智能写作等场景。
(2)文本分类:大型语言模型可以用于对文本进行分类,如情感分析、主题分类等。这些应用可以用于舆情分析、信息检索等场景。
(3)机器翻译:大型语言模型可以用于机器翻译任务,将一种语言的文本翻译为另一种语言。这些应用可以用于跨语言交流、国际化等场景。
(4)问答系统:大型语言模型可以用于构建问答系统,回答用户提出的问题。这些应用可以用于智能客服、知识查询等场景。
6.未来趋势
随着计算能力的提升和数据的积累,大型语言模型在自然语言处理领域取得了显著进展。未来,大型语言模型的发展趋势主要包括:
(1)模型规模:为了提高模型对文本数据的建模能力,未来大型语言模型的规模将继续扩大。这将需要更强的计算能力和更多的数据支持。
(2)多模态学习:大型语言模型不仅可以处理文本数据,还可以处理图像、声音等其他类型的数据。多模态学习将成为未来大型语言模型的一个重要研究方向。
(3)跨语言学习:随着全球化的发展,跨语言学习将成为大型语言模型的一个重要应用场景。模型需要在多种语言之间进行知识迁移和融合。
(4)可解释性和可靠性:随着大型语言模型在各个领域的应用,模型的可解释性和可靠性将成为一个重要研究方向。这将有助于提高模型在关键领域的应用效果。

总结:LLM它是一种基于深度学习的人工智能技术,通过大量的语料数据进行训练,能够理解和生成自然语言文本。LLM在接收到输入文本后,可以预测并生成接下来可能出现的文本内容,因此具有非常广泛的应用,如文本生成、机器翻译、智能问答、语音识别等领域。简单来说,LLM就是一种能够模拟人类语言处理能力的大型神经网络模型。总之,大型语言模型是一种强大的人工智能算法,它在自然语言处理领域具有广泛的应用。随着技术的不断发展,大型语言模型将在未来发挥更大的作用。