引言
我们拿到了xml文件
我们要将将xml文件中的数据加载并解析
完成数据的处理
并且返回给前端页面(result格式)
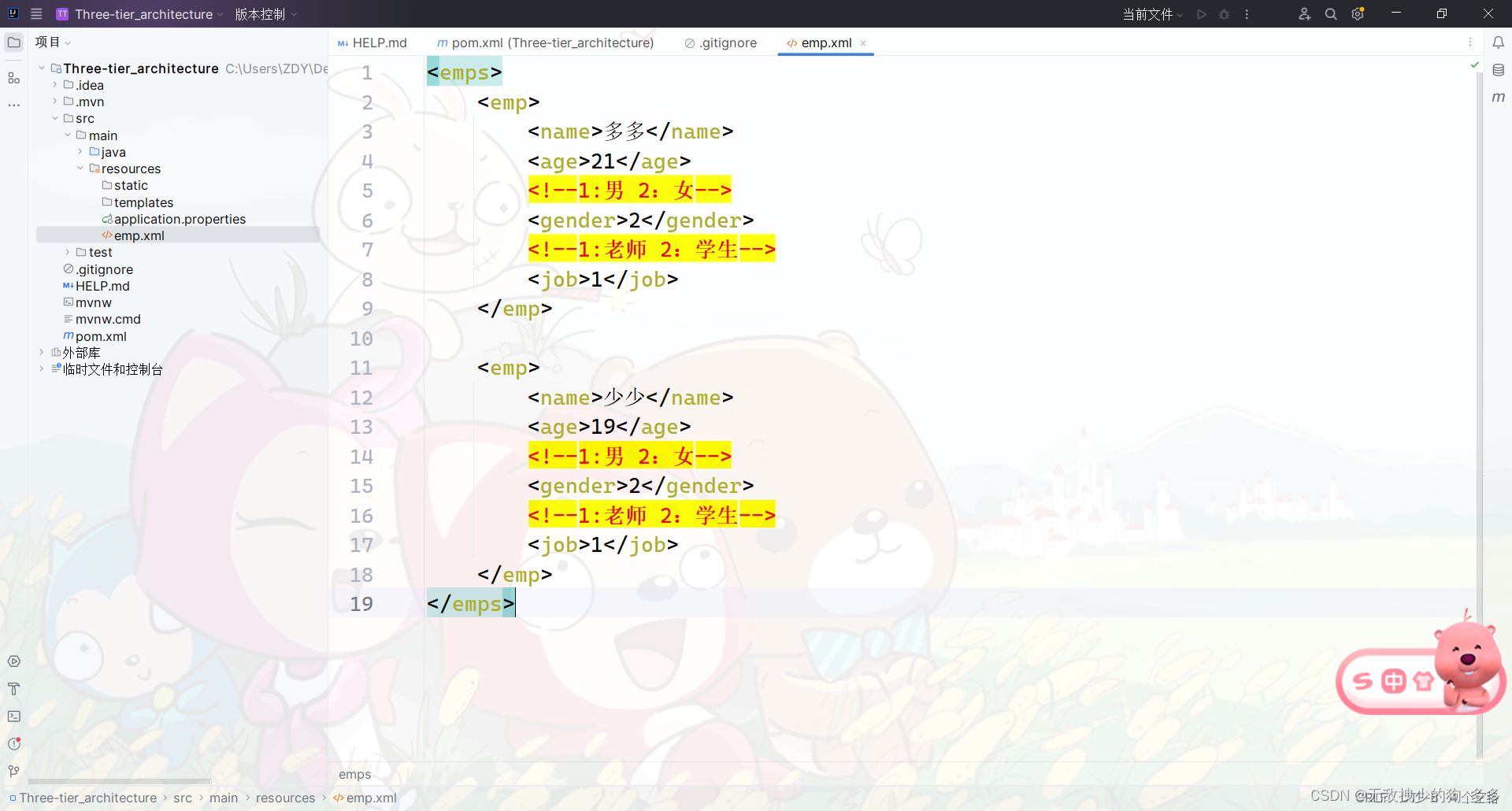
1.将xml文件放在resources目录下
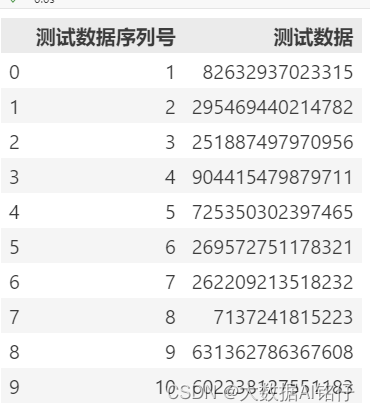
xml是我们需要解析的文件

查看xml文件
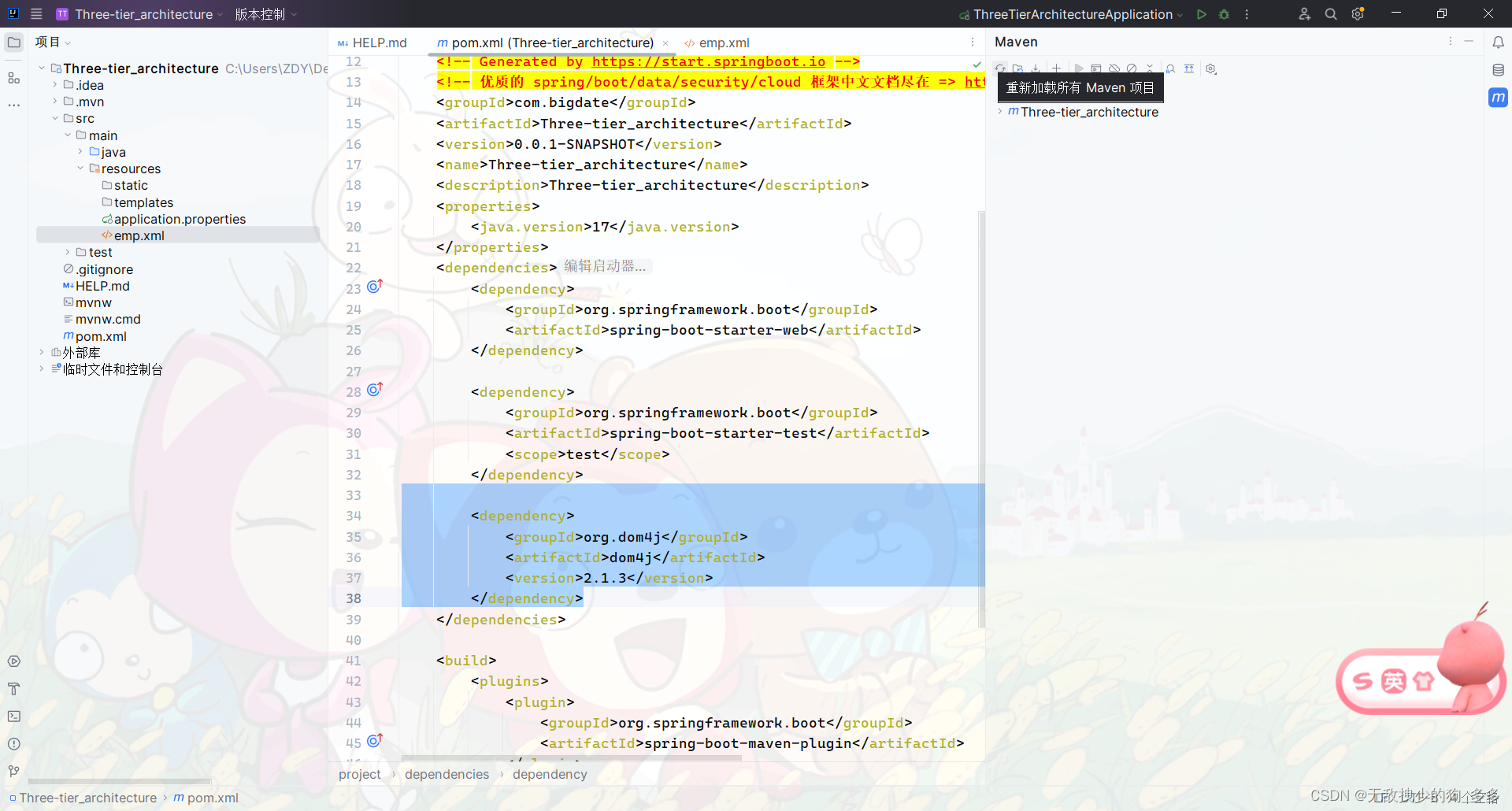
2.在springboot中引入dom4j依赖
解析xml需要在springboot中引入dom4j依赖

这边我们在springboot工程中已经引入依赖并重新构建了maven
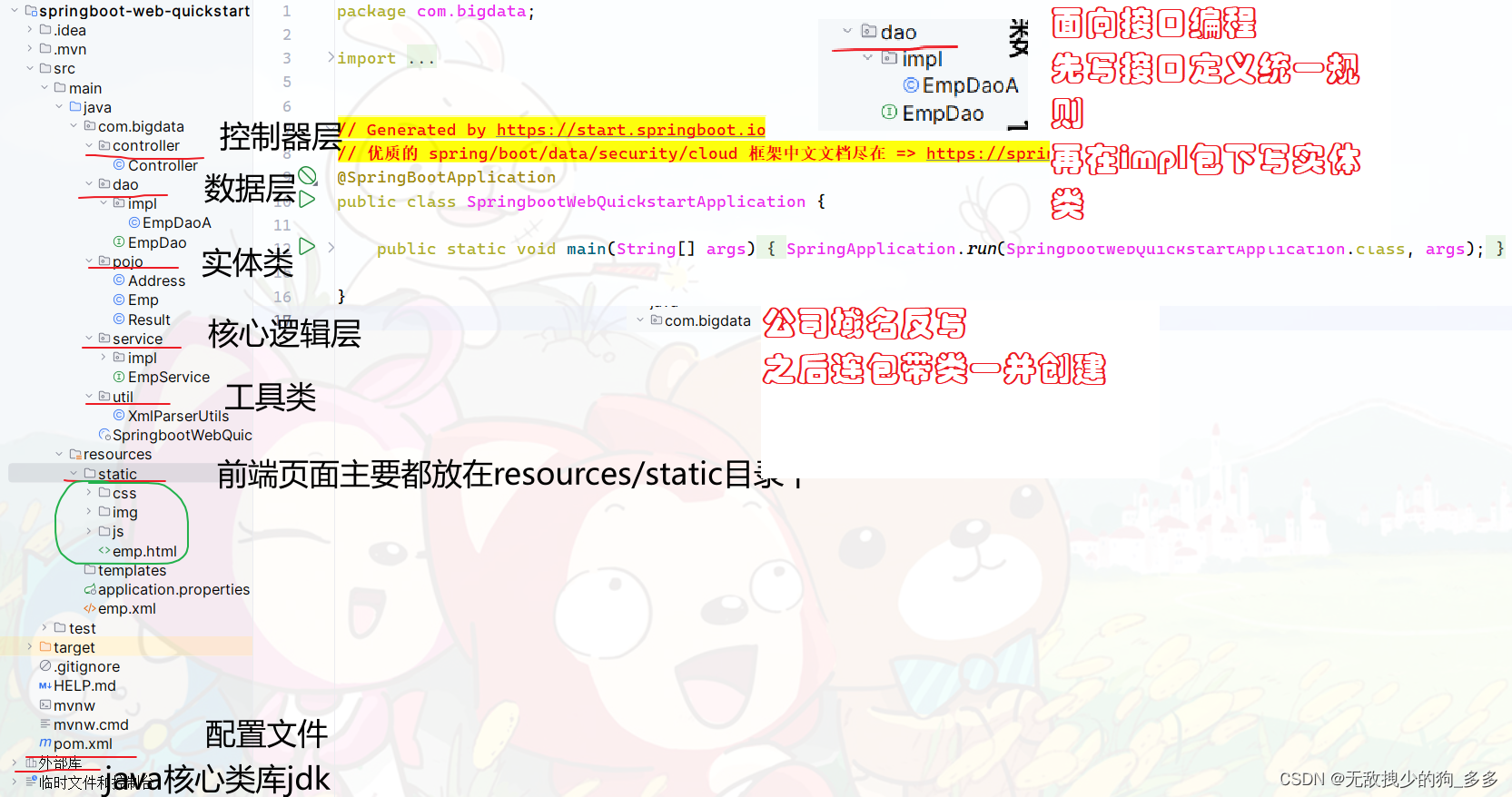
3.引入工具类XmlParserUtils
工具类放入java文件夹下的总包(公司域名反写)的util工具包下

这里引入的是一个解析xml文件的工具类XmlParserUtils
参数是xml文件路径和实例化的类的类型
返回值是list集合

package com.bigdate.threetier_architecture.util;import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;import java.lang.reflect.Constructor;
import java.util.*;
import java.io.File;
import java.util.ArrayList;public class XmlParserUtils{public static <T> List<T> parse(String file,Class<T> targetClass){ArrayList<T> list=new ArrayList<T>();try {//获取一个解析器对象SAXReader saxReader=new SAXReader();//利用解析器把xml文件加载到内存中 并且返回一个文档对象Document document=saxReader.read(new File(file));//获取到根标签Element rootElement =document.getRootElement();//通过根标签来获取user标签List <Element> elements=rootElement.elements("emp");//遍历集合,得到每一个user标签for(Element element:elements){//获得name属性String name=element.element("name").getText();//获得age属性String age=element.element("age").getText();//获得gender属性String gender=element.element("gender").getText();//获得job属性String job=element.element("job").getText();//组装数据Constructor<T>constructor=targetClass.getDeclaredConstructor(String.class,Integer.class,String.class,String.class);constructor.setAccessible(true);T object=constructor.newInstance(name,Integer.parseInt(age),gender,job);//把数据添加到集合里面去list.add(object);}} catch (Exception e) {e.printStackTrace();}return list;}
}4.编写实体类emp和统一响应结果类Result
不管是实体类还是统一响应结果类
我们都将其放在pojo包下
且都是用javabean封装的

实体类emp 标准的javabean 这样就能通过创建对象的方式封装emp的各属性
注意数据类型都是包装类
package com.bigdate.threetier_architecture.pojo;public class Emp {private String name;private Integer age;private String gender;private String job;public Emp() {}public Emp(String name, Integer age, String gender, String job) {this.name = name;this.age = age;this.gender = gender;this.job = job;}/*** 获取* @return name*/public String getName() {return name;}/*** 设置* @param name*/public void setName(String name) {this.name = name;}/*** 获取* @return age*/public Integer getAge() {return age;}/*** 设置* @param age*/public void setAge(Integer age) {this.age = age;}/*** 获取* @return gender*/public String getGender() {return gender;}/*** 设置* @param gender*/public void setGender(String gender) {this.gender = gender;}/*** 获取* @return job*/public String getJob() {return job;}/*** 设置* @param job*/public void setJob(String job) {this.job = job;}public String toString() {return "Emp{name = " + name + ", age = " + age + ", gender = " + gender + ", job = " + job + "}";}
}
统一响应结果result类
这个类主要是给前端页面一个统一响应的响应结果
统一后端返回对象
result类包含三个成员属性和三个静态方法
package com.bigdate.threetier_architecture.pojo;public class Result {private Integer code;//响应的状态码private String msg;//响应的信息 如successprivate Object data;//响应回的数据 数据类型为Objectpublic Result() {}public Result(Integer code, String msg, Object data) {this.code = code;this.msg = msg;this.data = data;}public Integer getCode() {return code;}public void setCode(Integer code) {this.code = code;}public String getMsg() {return msg;}public void setMsg(String msg) {this.msg = msg;}public Object getData() {return data;}public void setData(Object data) {this.data = data;}public String toString() {return "Result{code = " + code + ", msg = " + msg + ", data = " + data + "}";}//定义静态方法 帮助我们快速构建result对象//有数据时响应成功返回 会自动补齐其他参数public static Result success(Object data){return new Result(1,"success",data);}//没有任何数据返回 即使成功返回成员属性data也是null public static Result success(){return new Result(1,"success",null);}//响应的信息多种多样 仅仅返回响应信息 应该直接放到成员属性的位置public static Result success(String msg){return new Result(1,msg,null);}
}
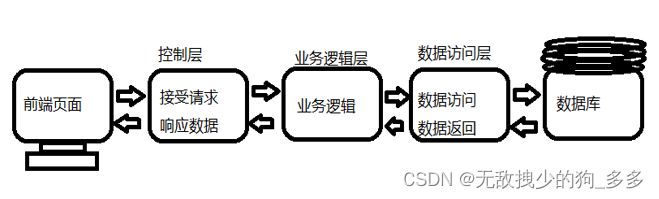
架构展示
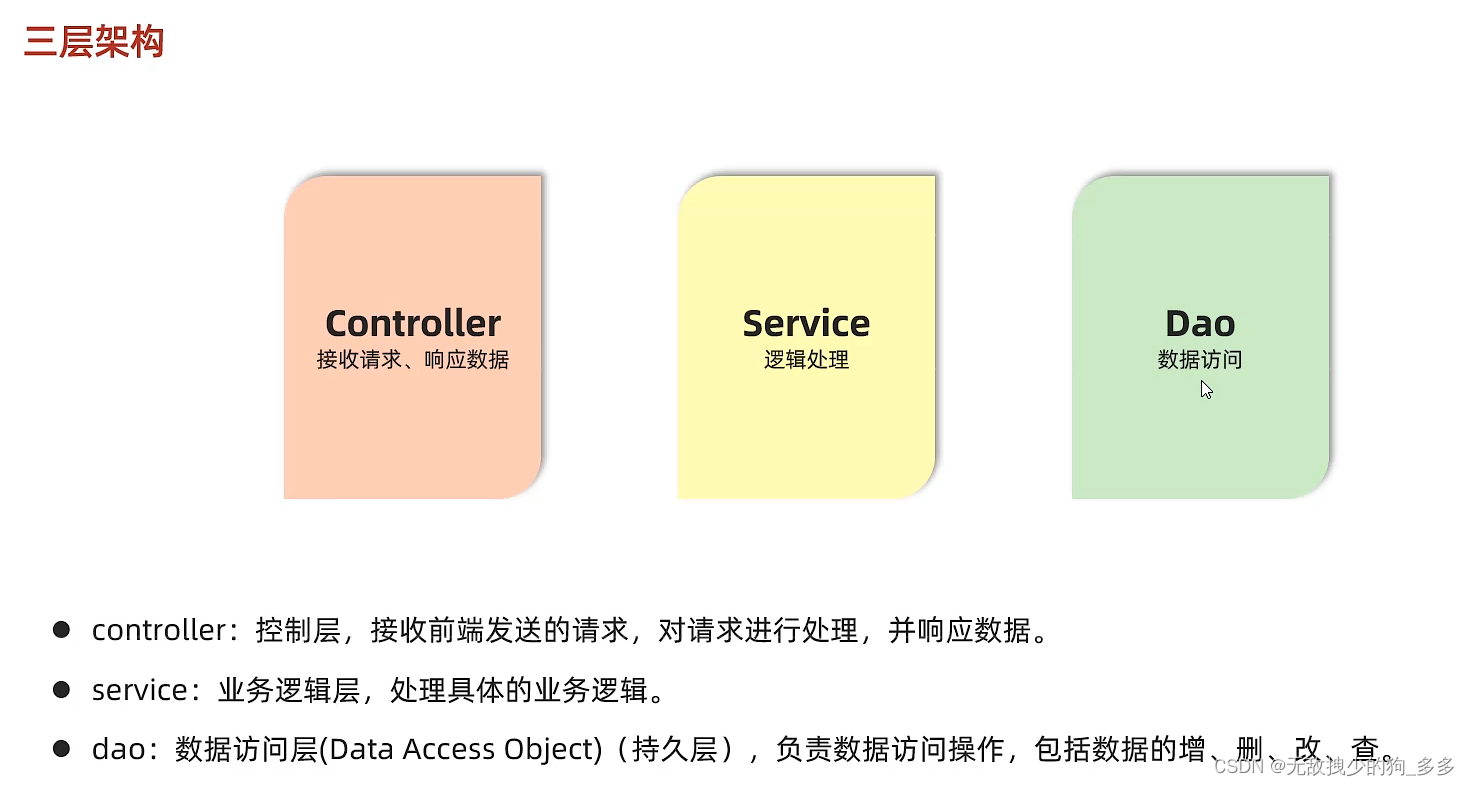
5.数据 -- dao层
我们采用的面向接口的编程方式
先写规则接口 然后用实现类去填充

接口
package com.bigdata.dao;import com.bigdata.pojo.Emp;import java.util.List;/*
* 面向接口编程
* 接口的实现类必须重写接口里的所有方法
* 如应对以后我们从不同地方拿到数据 如xml 本地文件 数据库 服务器
* 所以我们先写接口 定义统一的规则 就是从哪里拿取数据
* 之后通过创建接口实现类的方式从指定地方拿取数据
* */public interface EmpDao {//获取员工列表数据public List<Emp> listEmp();
}
实现类实现了接口并重写了方法
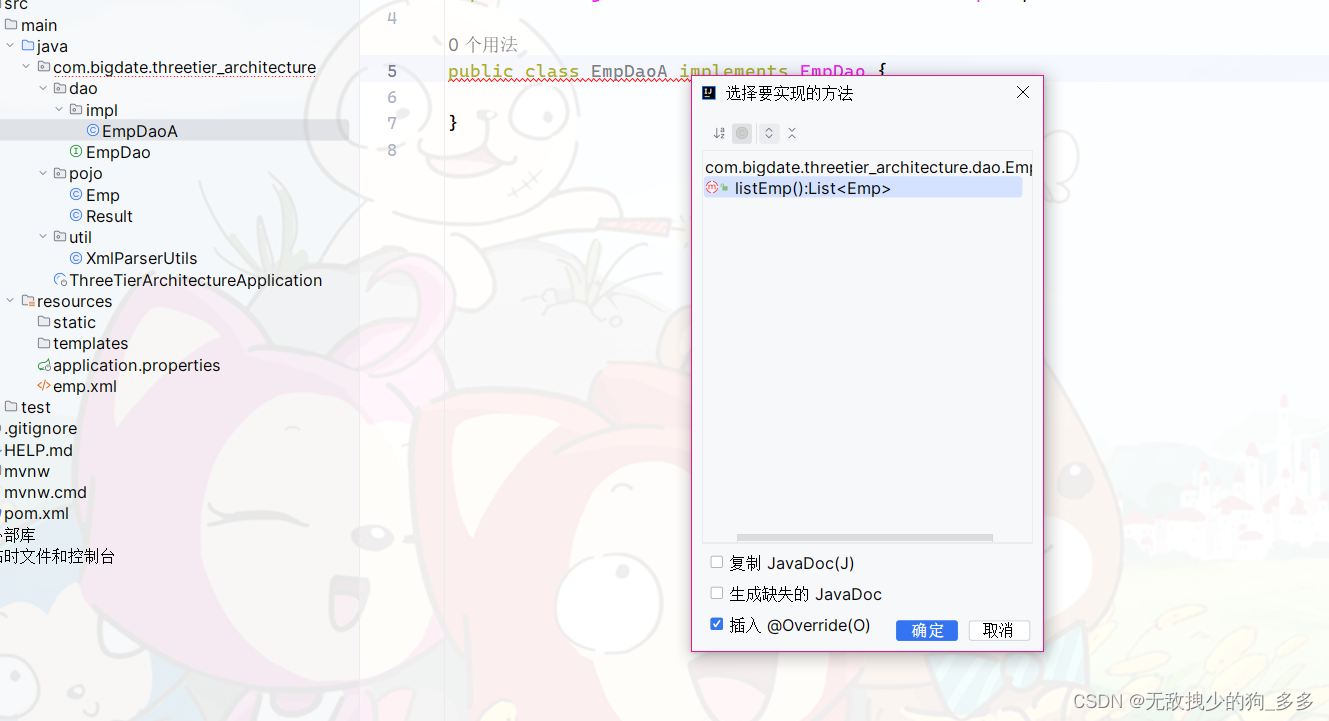
加载了xml文件 调用工具类XmlParserUtils来解析
package com.bigdata.dao.impl;import com.bigdata.dao.EmpDao;
import com.bigdata.pojo.Emp;
import com.bigdata.util.XmlParserUtils;import java.util.List;//接口的实现类A
public class EmpDaoA implements EmpDao {@Overridepublic List<Emp> listEmp() {//1.加载并解析xml文件String file=this.getClass().getClassLoader().getResource("emp.xml").getFile();System.out.println(file);List<Emp> empList=XmlParserUtils.parse(file, Emp.class);return empList;}}
6.核心逻辑 -- service层
最主要的一层
接口 与刚刚一样 接口中只有一个属性 集合
说明我们在service层中的实现类中依然是要对 存储在list内的数据进行处理
package com.bigdata.service;import com.bigdata.pojo.Emp;import java.util.List;public interface EmpService {//获取员工列表数据public List<Emp>listEmp();
}
接口的实现类 处理代码的核心逻辑

其中我们的list集合从dao层获取
我们要获取的集合就是那个从service层接口的实现类已经处理好的集合

package com.bigdata.service.impl;import com.bigdata.dao.EmpDao;
import com.bigdata.dao.impl.EmpDaoA;
import com.bigdata.pojo.Emp;
import com.bigdata.service.EmpService;import java.util.List;public class EmpServiceA implements EmpService {//service层拿取集合要从dao层获取 调用dao获取数据private EmpDao empDao=new EmpDaoA();@Overridepublic List<Emp> listEmp() {//拿到dao对象List<Emp> empList=empDao.listEmp();//2.对数据进行转换处理empList.stream().forEach(emp ->{//处理genderString gender=emp.getGender();if(gender.equals("1")){emp.setGender("男");}else emp.setGender("女");//处理jobString job=emp.getJob();if(job.equals("1")){emp.setJob("学生");}else emp.setJob("老师");});return empList;}
}
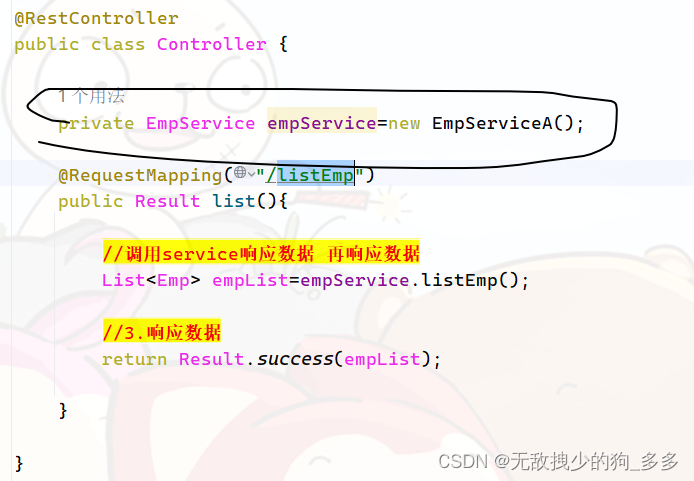
7.控制器 -- controller层
不需要书写接口
我们将前dao层和service处理的数据已经放到集合里面去
我们要将集合返回 而这个集合去service层中去拿
service层的集合又是从dao层获取的并经过逻辑处理的
package com.bigdata.controller;import com.bigdata.pojo.Emp;
import com.bigdata.pojo.Result;
import com.bigdata.service.EmpService;
import com.bigdata.service.impl.EmpServiceA;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController
public class Controller {private EmpService empService=new EmpServiceA();@RequestMapping("/listEmp")public Result list(){//调用service响应数据 再响应数据List<Emp> empList=empService.listEmp();//3.响应数据return Result.success(empList);}}
8.前端页面展示
启动spingboot
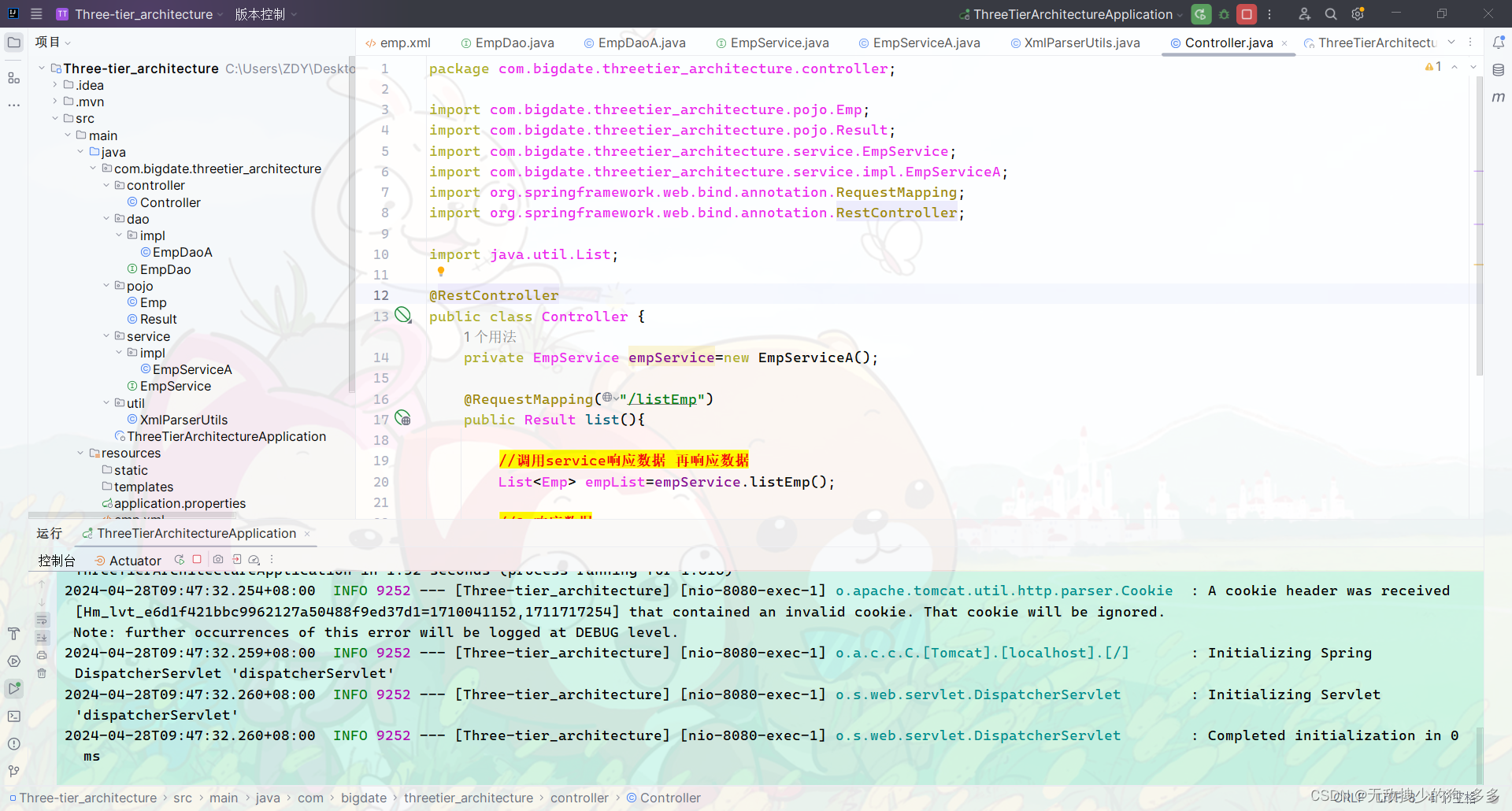
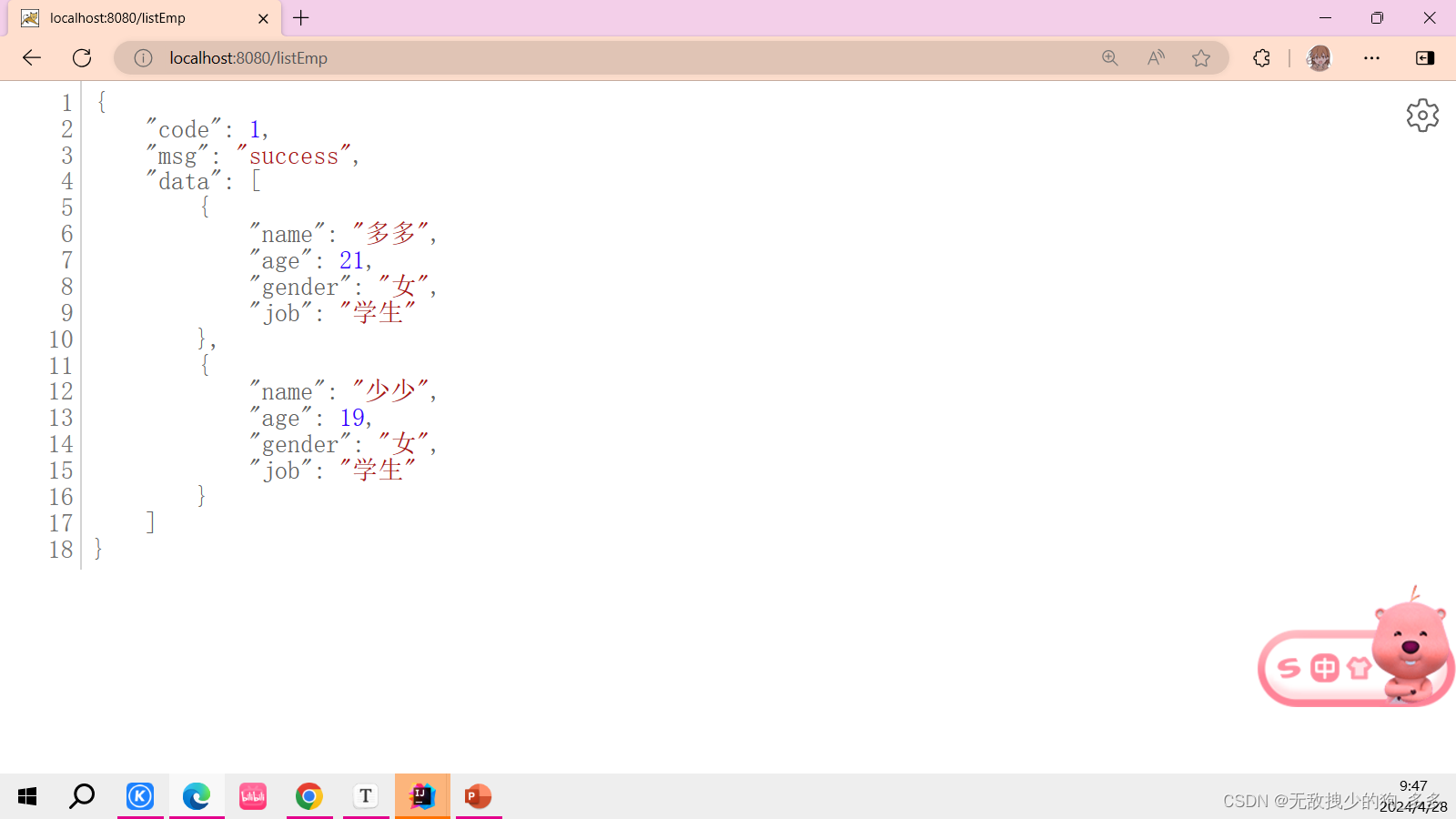
访问本地网址 进行展示
总结
定义的每一个对外暴露的方法我们都称为功能接口
引号内的是功能接口的访问路径

如果用户从前端页面获取数据
先是给controller层发起响应
controller层向service层发起请求
servece层向dao层拿取数据
dao层再去翻数据源
那我们的代码应该从这时候开始写
所以我们会选择先书写dao层的代码
然后回调给service层 service再传递给controller层
想了一晚上 所以我认为我们在实际后端开发中就是书写数据回调的代码
我们在书写三层架构的代码时是
先写接口 再写实现类
即面向接口编程
接口的事项类必须重写接口中的所有方法
如我们以后从不同地方拿到数据 如数据库 云数据库 本地文件 服务器
所以我们先写接口定义统一的规则的 就是从哪里拿取数据 之后用实现类重写方法
三层架构分工明确利于书写
前一层的数据都是后一层获取的 而排在最最后的的是数据源 最前面的是前端页面
吐槽
草你爸 没有xml文件和工具类本多直接动手搓别让我再见类引入三字 累死了!