一. 模型的下载
weights为false时则为没有提前经过训练的模型,为true时则经过了提前训练
vgg16_false = torchvision.models.vgg16(weights=False)
vgg16_true = torchvision.models.vgg16(weights=True)打印
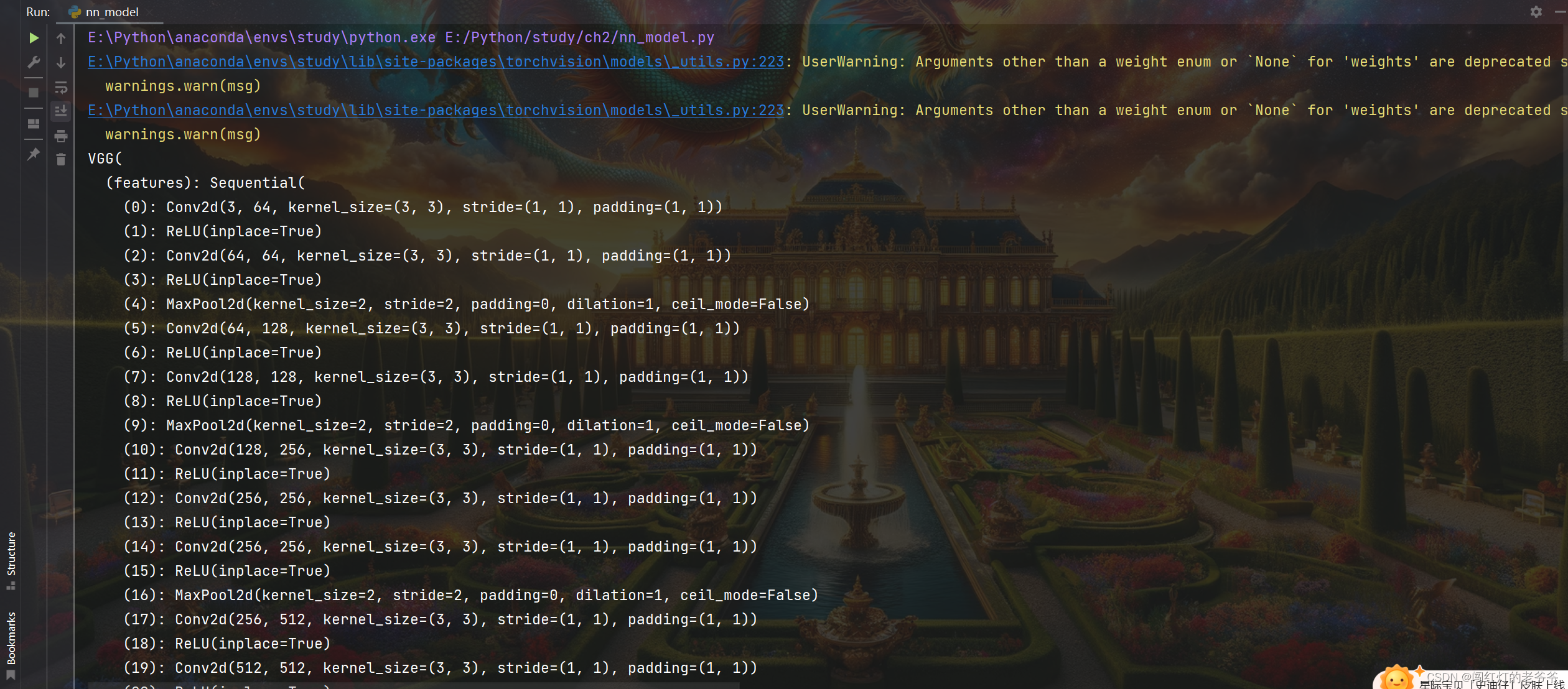
二. 模型的修改
(1)添加操作
分为两种,一种是在classifier的外部添加,一种是在内部添加
外部添加,例如添加了一个线性层
vgg16_true.add_module("add_linear", nn.Linear(1000, 10))打印,最下方添加了线性层
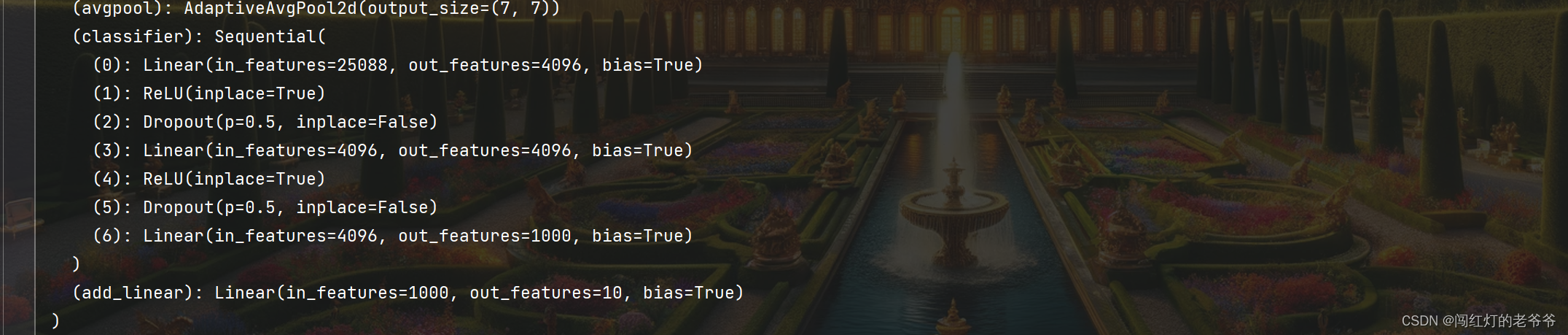
内部添加
vgg16_true.classifier.add_module("add_linear", nn.Linear(1000, 10))打印,在classifier里面添加

(2)修改操作
例如,我修改索引为6的操作
vgg16_false.classifier[6] = nn.Linear(4096, 5)打印
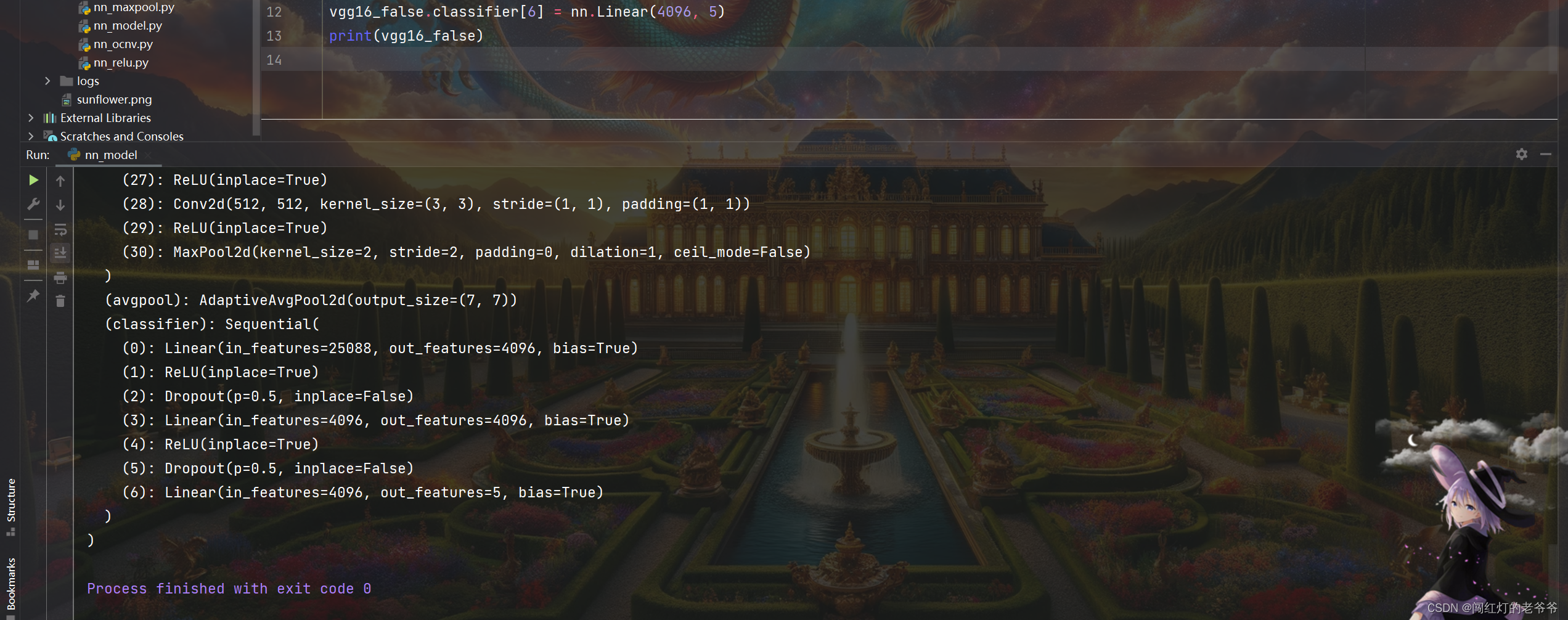
三. 模型的保存与读取
在PyTorch中,可以使用torch.save函数来保存模型的状态字典或整个模型。同时,可以使用torch.load函数来加载保存的模型。
1. 保存模型的状态字典:
# 保存模型的状态字典
torch.save(model.state_dict(), 'model.pth')# 加载模型的状态字典
model.load_state_dict(torch.load('model.pth'))
2. 保存整个模型:
# 保存整个模型
torch.save(model, 'model.pth')# 加载整个模型
model = torch.load('model.pth')
需要注意的是,如果要加载模型,需要确保模型的定义和保存时一致。如果要加载模型到GPU上,需要在torch.load函数中传入map_location参数来指定加载到哪个设备上。
四. 训练套路实例
训练流程
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom ch2.model import Yktrain_set = torchvision.datasets.CIFAR10("./data", transform=torchvision.transforms.ToTensor(), train=True,download=True)
test_set = torchvision.datasets.CIFAR10("./data", transform=torchvision.transforms.ToTensor(), train=False,download=True)
train_loader = DataLoader(dataset=train_set, batch_size=64, drop_last=True)
test_loader = DataLoader(dataset=test_set, batch_size=64, drop_last=True)loss_fn = nn.CrossEntropyLoss()learning_rate = 1e-2
yk = Yk()
opt = torch.optim.SGD(yk.model1.parameters(), learning_rate)total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter("../logs")
for i in range(epoch):print("————第{}次训练开始————".format(i))yk.train()for data in train_loader:images, targets = dataoutput = yk(images)loss = loss_fn(output, targets)opt.zero_grad()loss.backward()opt.step()total_train_step += 1if total_train_step % 100 == 0:print("训练次数:{}, Loss:{}".format(total_train_step, loss))writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始yk.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_loader:images, targets = dataoutput = yk(images)loss = loss_fn(output, targets)total_test_loss = total_test_loss + lossaccuracy = (output.argmax(1) == targets).sum()total_accuracy=total_accuracy+accuracyprint("整体测试集上的loss:{}".format(total_test_step))print("整体测试集上的正确率{}".format(total_accuracy/len(test_set)))total_test_step += 1writer.add_scalar("test_loss", total_test_loss.item(), total_test_step)writer.add_scalar("test_accuracy", total_accuracy.item(), total_test_step)torch.save(yk, "yk_{}".format(i))print("模型已保存")writer.close()
训练模型
from torch import nnclass Yk(nn.Module):def __init__(self):super(Yk, self).__init__()self.model1 = nn.Sequential(nn.Conv2d(3, 32, (5, 5), padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 32, (5, 5), padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 64, (5, 5), padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(4 * 4 * 64, 64),nn.Linear(64, 10))def forward(self, x):x = self.model1(x)return xif __name__ == '__main__':yk = Yk()
打印

五. 使用GPU训练
1. 使用cuda
原本代码
import timeimport torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom ch2.model import Yktrain_set = torchvision.datasets.CIFAR10("./data", transform=torchvision.transforms.ToTensor(), train=True,download=True)
test_set = torchvision.datasets.CIFAR10("./data", transform=torchvision.transforms.ToTensor(), train=False,download=True)
train_loader = DataLoader(dataset=train_set, batch_size=64, drop_last=True)
test_loader = DataLoader(dataset=test_set, batch_size=64, drop_last=True)start_time = time.time()loss_fn = nn.CrossEntropyLoss()
# loss_fn = loss_fn.cuda()
learning_rate = 1e-2
yk = Yk()
# yk = yk.cuda()
opt = torch.optim.SGD(yk.model1.parameters(), learning_rate)total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter("../logs")
for i in range(epoch):print("————第{}次训练开始————".format(i))yk.train()for data in train_loader:images, targets = data# images = images.cuda()# targets = targets.cuda()output = yk(images)loss = loss_fn(output, targets)opt.zero_grad()loss.backward()opt.step()total_train_step += 1if total_train_step % 100 == 0:end_time = time.time()print(end_time-start_time)print("训练次数:{}, Loss:{}".format(total_train_step, loss))writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始yk.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_loader:images, targets = data# images = images.cuda()# targets = targets.cuda()output = yk(images)loss = loss_fn(output, targets)total_test_loss = total_test_loss + lossaccuracy = (output.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的loss:{}".format(total_test_step))print("整体测试集上的正确率{}".format(total_accuracy / len(test_set)))total_test_step += 1writer.add_scalar("test_loss", total_test_loss.item(), total_test_step)writer.add_scalar("test_accuracy", total_accuracy.item(), total_test_step)torch.save(yk, "yk_{}".format(i))print("模型已保存")writer.close()间隔时间如下

使用cuda,用gpu后,间隔时间明显极大缩短了

2. 定义设备
在里面定义使用cpu,还是cuda,有多个gpu,可以选用第几个(我选用的第一个)
device = torch.device("cuda:0")原本需要使用*.cuda的地方,修改为*.to(device):
yk = yk.to(device)全部代码如下:
import timeimport torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom ch2.model import Ykdevice = torch.device("cuda:0")train_set = torchvision.datasets.CIFAR10("./data", transform=torchvision.transforms.ToTensor(), train=True,download=True)
test_set = torchvision.datasets.CIFAR10("./data", transform=torchvision.transforms.ToTensor(), train=False,download=True)
train_loader = DataLoader(dataset=train_set, batch_size=64, drop_last=True)
test_loader = DataLoader(dataset=test_set, batch_size=64, drop_last=True)start_time = time.time()loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
learning_rate = 1e-2
yk = Yk()
yk = yk.to(device)
opt = torch.optim.SGD(yk.model1.parameters(), learning_rate)total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter("../logs")
for i in range(epoch):print("————第{}次训练开始————".format(i))yk.train()for data in train_loader:images, targets = dataimages = images.to(device)targets = targets.to(device)output = yk(images)loss = loss_fn(output, targets)opt.zero_grad()loss.backward()opt.step()total_train_step += 1if total_train_step % 100 == 0:end_time = time.time()print(end_time - start_time)print("训练次数:{}, Loss:{}".format(total_train_step, loss))writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始yk.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_loader:images, targets = dataimages = images.to(device)targets = targets.to(device)output = yk(images)loss = loss_fn(output, targets)total_test_loss = total_test_loss + lossaccuracy = (output.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的loss:{}".format(total_test_step))print("整体测试集上的正确率{}".format(total_accuracy / len(test_set)))total_test_step += 1writer.add_scalar("test_loss", total_test_loss.item(), total_test_step)writer.add_scalar("test_accuracy", total_accuracy.item(), total_test_step)torch.save(yk, "yk_{}".format(i))print("模型已保存")writer.close()
运行