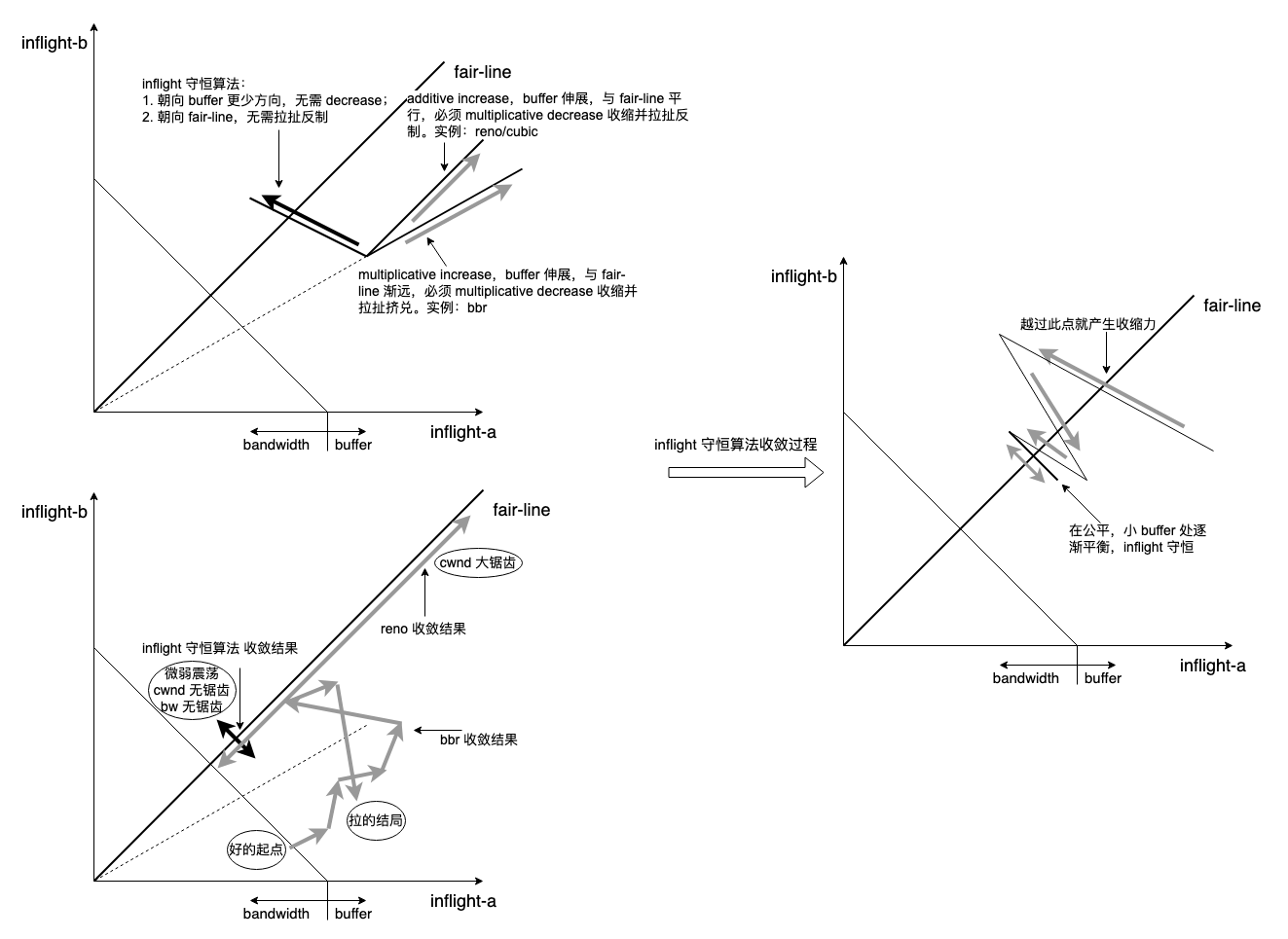
目录
一、什么是消息队列
二、Kafka怎么避免重复消费
三、RabbitMQ 的消息如何实现路由
四、如何保证RabbitMQ的消息可靠传输
五、如何进⾏消息队列选型
一、什么是消息队列
消息队列 Message Queue,简称 MQ。是一种应用间的通信方式,主要由三个部分组成
生产者:Producer
消息的产生者与调用端,主要负责消息所承载的业务信息的实例化,是一个队列的发起方
代理:Broker
主要的处理单元,负责消息的存储、投递、及各种队列附加功能的实现,是消息队列最核心的组成部分
消费者:Consumer
一个消息队列的终端,也是消息的调用端 具体是根据消息承载的信息,处理各种业务逻辑。 消息队列的应用场景较多,常用的可以分为三种:
异步处理
主要应用于对实时性要求不严格的场景, 比如:用户注册发送验证码、下单通知、发送优惠券等等。 服务方只需要把协商好的消息发送到消息队列, 剩下的由消费消息的服务去处理, 不用等待消费服务返回结果。
应用解耦
应用解耦可以看作是把相关但耦合度不高的系统联系起来。 比如订单系统与 WMS、EHR 系统,有关联但不哪么紧密 ,每个系统之间只需要把约定的消息发送到 MQ,另外的系统去消费即可。 解决了各个系统可以采用不同的架构、语言来实现,从而大大增加了系统的灵活 性。
流量削峰
流量削峰一般应用在大流量入口且短时间内业务需求处理不完的服务中心, 为了权衡高可用,把大量的并行任务发送到 MQ 中, 依据 MQ 的存储及分发功能,平稳的处理后续的业务,起到一个大流量缓冲的作用。
目前市面上常见的消息队列中间件主要有:ActiveMQ、RabbitMQ、Kafka、RocketMQ
二、Kafka怎么避免重复消费
首先,Kafka Broker 上存储的消息,都有一个 Offset 标记。然后kafka 的消费者是通过 offSet 标记来维护当前已经消费的数据,每消费一批数据,Kafka Broker 就会更新 OffSet 的值,避免重复消费。
重复消费出现的情况:
1、程序被强制 kill 掉或者宕机
默认情况下,消息消费完以后,会自动提交 Offset 的值,避免重复消费。Kafka 消费端的自动提交逻辑有一个默认的 5 秒间隔,也就是说在 5 秒之后的下一次向 Broker 拉取消息的时候提交。 所以在 Consumer 消费的过程中,应用程序被强制 kill 掉或者宕机,可能会导致 Offset 没提交,从而产生重复提交的问题。
2、消息处理不及时
除此之外,还有另外一种情况也会出现重复消费。在 Kafka 里面有一个 Partition Balance 机制,就是把多个 Partition 均衡的分配 给多个消费者。Consumer 端会从分配的 Partition 里面去消费消息,如果 Consumer 在默认的 5 分钟内没办法处理完这一批消息。就会触发Kafka的 Rebalance机制,从而导致Offset自动提交失败。 而在重新Rebalance之后,Consumer还是会从之前没提交的Offset位置开始 消费,也会导致消息重复消费的问题。
解决办法:
基于这样的背景下,解决重复消费消息问题的方法有几个
1、提高消费端的处理性能避免触发 Balance
比如可以用异步的方式来处理消息,缩短单个消息消费的时间,或者还可以调整消息处理的超时时间,还可以减少一次性从 Broker 上拉取数据的条数
2、利用幂等性
可以针对消息生成 md5 然后保存到mysql或者redis 里面,在处理消息之前先去mysql或者 redis里面判断是否已经消费过
三、RabbitMQ 的消息如何实现路由
RabbitMQ 是一个基于 AMQP 协议实现的分布式消息中间件。
AMQP 的具体工作机制是,生产者把消息发送到 RabbitMQ Broker 上的 Exchange 交换机上。 Exchange 交换机把收到的消息根据路由规则发给绑定的队列(Queue)。 最后再把消息投递给订阅了这个队列的消费者,从而完成消息的异步通讯。
其中,Exchange 是一个消息交换机,它里面定义了消息路由的规则,也就是这 个消息路由到那个队列。 然后 Queue 表示消息的载体,每个消息可以根据路由规则路由到一个或者多个 队列里面。 而关于消息的路由机制,核心的组件是 Exchange。 它负责接收生产者的消息然后把消息路由到消息队列,而消息的路由规则由 ExchangeType 和 Binding 决定。 Binding 表示建立 Queue 和 Exchange 之间的绑定关系,每一个绑定关系会存在 一个 BindingKey。 通过这种方式相当于在 Exchange 中建立了一个路由关系表。
生产者发送消息的时候,需要声明一个 routingKey(路由键),Exchange 拿到 routingKey 之后,根据 RoutingKey 和路由表里面的 BindingKey 进行匹配,而 匹配的规则是通过 ExchangeType 来决定的。
在 RabbitMQ 中,有三种类型的 Exchange:direct ,fanout 、topic。
direct: 完整匹配方式,也就是Routing key 和Binding Key 完全一致,相当于 点对点的发送。
fanout: 广播机制,这种方式不会基于Routing key来匹配,而是把消息广播给 绑定到当前 Exchange上的所有队列上。
topic: 正则表达式匹配,根据Routing Key 使用正则表达式进行匹配,符合匹 配规则的 Queue都会收到这个消息
四、如何保证RabbitMQ的消息可靠传输
在 RabbitMQ 的整个消息传递过程中,有三种情况会存在丢失。
1、生产者把消息发送到 RabbitMQ Server 的过程中丢失
2、RabbitMQ Server 收到消息后在持久化之前宕机导致数据丢失
3、消费端收到消息还没来得及处理宕机,导致 RabbitMQ Server 认为这个消息已签收。
所以,只需要从这三个纬度去保证消息的可靠性传输就行了。
1、从生产者发送消息的角度来说,RabbitMQ 提供了一个 Confirm(消息确认)机 制,生产者发送消息到 Server 端以后,如果消息处理成功,Server 端会返回一 个 ack 消息。 客户端可以根据消息的处理结果来决定是否要做消息的重新发送,从而确保消息 一定到达 RabbitMQ Server 上。
2、从 RabbitMQ Server 端来说,可以开启消息的持久化机制,也就是收到消息之 后持久化到磁盘里面。 设置消息的持久化有两个步骤。 创建 Queue 的时候设置为持久化 发送消息的时候,把消息投递模式设置为持久化投递,不过虽然设置了持久化消息,但是有可能会出现,消息刷新到磁盘之前,RabbitMQ Server 宕机导致消息丢失的问题。 所以为了确保万无一失,需要结合 Confirm 消息确认机制一起使用。
3、 从消费端的角度来说,我们可以把消息的自动确认机制修改成手动确认,也就是说消费端只有手动调用消息确认方法才表示消息已经被签收。 这种方式可能会造成重复消费问题,所以这里需要考虑到幂等性的设计。
五、如何进⾏消息队列选型
Kafka:
优点: 吞吐量⾮常⼤,性能⾮常好,集群⾼可⽤。
缺点:会丢数据,功能⽐较单⼀。
使⽤场景:⽇志分析、⼤数据采集
RabbitMQ:
优点: 消息可靠性⾼,功能全⾯。
缺点:吞吐量⽐较低,消息积累会严重影响性能。erlang语⾔不好定制。
使⽤场景:⼩规模场景。
RocketMQ:
优点:⾼吞吐、⾼性能、⾼可⽤,功能⾮常全⾯。
缺点:开源版功能不如云上商业版。官⽅⽂档和周边⽣态还不够成熟。客户端只⽀持java。 使⽤场景:⼏乎是全场景。