17. High-Resolution Image Synthesis with Latent Diffusion Models
该文首次提出在潜在特征空间中的扩散模型LDM,也是大名鼎鼎的Stable Diffusion(SD)模型的基础。不同于之前的扩散模型直接在图像维度上进行扩散和去噪,LDM首先训练了一个自动编码器将图像压缩至一个潜在的特征空间中,并在该低维空间内进行扩散和去噪,最后再通过一个解码器恢复图像维度。这种方法能够大大降低计算的复杂度,提升训练和推理的速度,并且取得了更好的生成效果,已经成为后续许多图像生成方法的基础。
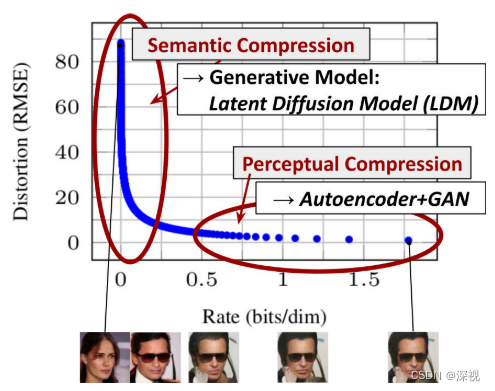
在介绍文章的动机时,作者提到之前的扩散模型是直接在图像上进行扩散和去噪的,为了保证计算复杂度处于可以接受的区间,通常只能对小尺寸的图像进行处理,如64 * 64,128 * 128。即便如此,因为需要经过多次的迭代,训练和推理的时间都非常长,训练一个扩散模型往往需要几百个GPU天。但作者发现,图像的压缩过程会经历两个阶段:感知压缩和语义压缩,如上图所示。在感知压缩阶段,图像仅仅损失一些无关紧要的高频细节信息,而在语义压缩阶段,才会对图像的语义性或概念性内容产生影响。
基于上述洞见,作者首先使用一个自动编码器,将图像进行大幅度压缩,并将其映射到一个潜在特征空间中。根据实验结果,压缩比例在4或8倍时,能够取得最好的生成效果和速度之间的平衡。自动编码器使用感知损失和基于块的对抗目标损失函数进行训练,并且引入了一个KL惩罚作为正则化项,目的是避免潜在特征空间中的方差过大。这里要注意地一点是,经过编码后的特征 z z z仍保持2D的结构,而不是像其他基于Transformer的方法将其转化为1D的特征。作者解释这使得后面的扩散模型能够按照卷积的方式进行处理,更好的利用图像自身的归纳偏置(局部相关性)。
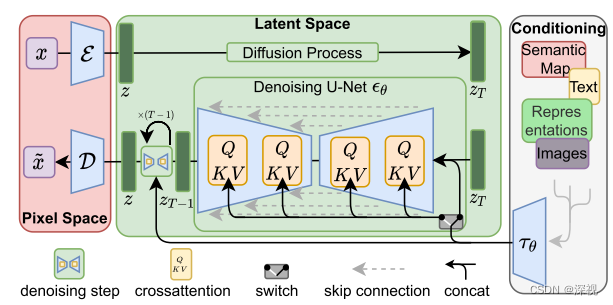
得到特征图 z z z后,就可以对其进行一个常规的扩散和去噪处理了。噪声估计模型 ϵ θ \epsilon_{\theta} ϵθ仍采用了U-net结构,但其中的自注意力层改为了Transformer块,即由自注意力层、MLP和交叉注意力层构成的模块,这是为了方便引入其他模态的条件信息。损失函数仍采用了简化的均方差损失,只是将噪声图像 x t x_t xt改为了噪声特征 z t z_t zt, L L D M : = E E ( x ) , ϵ ∼ N ( 0 , 1 ) , t [ ∥ ϵ − ϵ θ ( z t , t ) ∥ 2 2 ] L_{L D M}:=\mathbb{E}_{\mathcal{E}(x), \epsilon \sim \mathcal{N}(0,1), t}\left[\left\|\epsilon-\epsilon_{\theta}\left(z_{t}, t\right)\right\|_{2}^{2}\right] LLDM:=EE(x),ϵ∼N(0,1),t[∥ϵ−ϵθ(zt,t)∥22]经过 T T T次的去噪处理后,得到重建的潜在特征 z ~ \tilde{z} z~,再经过一个解码器得到生成图像 x ~ \tilde{x} x~.
图中的重建特征仍使用了 z z z来表示,这里为了与原始输入的特征 z z z区分,使用 z ~ \tilde{z} z~来表示
为了引入其他的条件信息,如类别标签、文本描述、语义分割图等,作者针对不同形式的条件输入 y y y训练了相应的条件编码器 τ θ ( y ) \tau_{\theta}(y) τθ(y),可以将条件输入转化为特征向量。然后,利用U-net中的交叉注意力层将其与原始的图像特征 z z z进行融合 Q = W Q ( i ) ⋅ φ i ( z t ) , K = W K ( i ) ⋅ τ θ ( y ) , V = W V ( i ) ⋅ τ θ ( y ) Q=W_{Q}^{(i)} \cdot \varphi_{i}\left(z_{t}\right), K=W_{K}^{(i)} \cdot \tau_{\theta}(y), V=W_{V}^{(i)} \cdot \tau_{\theta}(y) Q=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y)即交叉注意力层中的Q向量来自图像特征,而K和V向量均来自条件特征。对于文本条件,编码器可选择Bert或者CLIP中的文本编码器;对于布局条件,如边界框,可以对位置坐标和类别进行编码。
经过训练后,LDM在多个下游任务中都取得了非常好的效果,如图像生成、图像修复、超分提升等。
无条件图像生成:

超分提升:

图像修复:

其中最为重要的应用肯定是文生图模型StableDiffusion,在此基础上又陆续推出了SD-1.1-1.5多个版本的改进模型,大多是对训练数据集,训练周期数,以及编码器的修改。其中SD-XL是一个较大的改进版本,其采用了CLIP ViT-L 和 OpenCLIP ViT-bigG 两个文本编码器,并且将图像的大小和裁剪位置都作为条件信息引入到噪声估计模型中,最后额外单独训练了一个优化器用于高质量高分辨率的图像生成。在SDXL-turbo中,还利用了蒸馏技术,减少了生成过程的迭代次数,提升了生成速度。更加详细的介绍可参考这篇博客:Stable Diffusion ———LDM、SD 1.0, 1.5, 2.0、SDXL、SDXL-Turbo等版本之间关系现原理详解。近期Stability AI公司又发布了最新的SD3模型,其中使用了与Sora同源的DiT模型,但具体的论文和代码尚未公开。




![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-6.5](https://img-blog.csdnimg.cn/direct/af3bbc40a90646d1809e9eff2cc45597.png)