扩散模型
2024/9/16 17:45:16
【计算机视觉前沿研究 热点 顶会】ECCV 2024中扩散模型有关的论文
神经辐射场修复的驯服潜在扩散模型
神经辐射场(NERF)是一种从多视角图像进行三维重建的表示法。尽管最近的一些工作表明,在编辑具有扩散先验的重建的 NERF 方面取得了初步成功,但他们仍然在努力在完全未覆盖的区域中合成合理的几何图形。一个主要原因是…

30分钟学习如何搭建扩散模型的运行环境【pytorch版】【B站视频教程】【解决环境搭建问题】
30分钟学习如何搭建扩散模型的运行环境【B站视频教程】【解决环境搭建问题】
动手学习扩散模型
点击以下链接即可进入学习:
B站视频教程附赠:环境配置安装(配套讲解文档)
视频 讲解主要内容
一、环境设置 1.本地安装…

【三维重建】InstantSplat:稀疏视角的无SfM高斯泼溅 (3D Gaussian Splatting)
提示:关注B站【方矩实验室】,查看视频讲解 文章目录 1.摘要2.Introduction3.主要方法3.1 MVS( DUSt 3R )3.2 GS的初始化3.3 联合优化 4.实验5.总结总结 1.摘要 InstantSplat将多视图立体(MVS)预测与基于点的…
【三维重建】InstantSplat:稀疏视角的无SfM高斯泼溅 (3D Gaussian Splatting)
提示:关注B站【方矩实验室】,查看视频讲解 文章目录 1.摘要2.Introduction3.主要方法3.1 MVS( DUSt 3R )3.2 GS的初始化3.3 联合优化 4.实验5.总结 1.摘要 InstantSplat将多视图立体(MVS)预测与基于点的表示…

Open-Sora代码详细解读(2):时空3D VAE
Diffusion Models视频生成 前言:目前开源的DiT视频生成模型不是很多,Open-Sora是开发者生态最好的一个,涵盖了DiT、时空DiT、3D VAE、Rectified Flow、因果卷积等Diffusion视频生成的经典知识点。本篇博客从Open-Sora的代码出发,深…
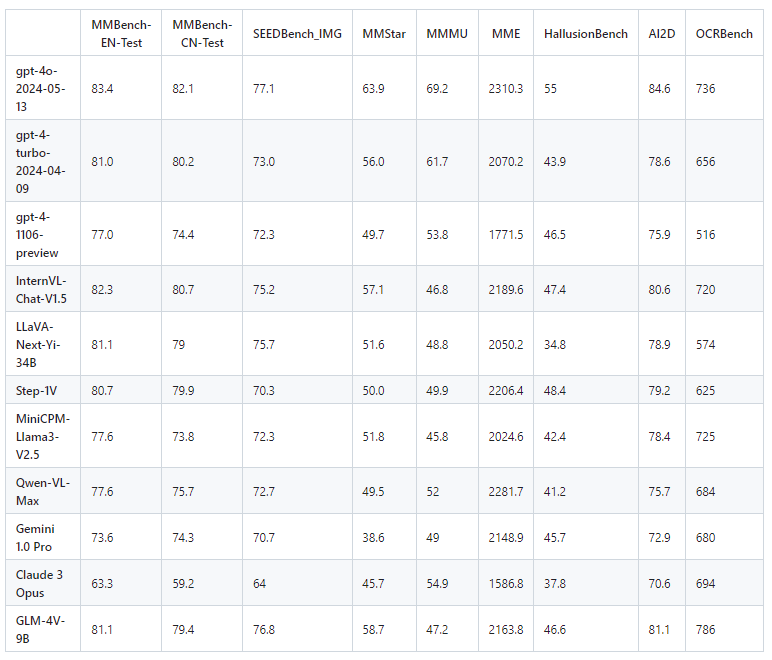
智谱 GLM4 模型开源,意料之中的尺寸,意料之外的效果
最近智谱开了GLM-4-9B的模型,不是6B,是9B。
一共开源了四个模型,Base版本模型(GLM-4-9B)、Chat版本模型(GLM-4-9B-Chat和GLM-4-9B-Chat-1M)和多模态模型(GLM-4V-9B-Chat)…

【Diffusion实战】训练一个diffusion模型生成S曲线(Pytorch代码详解)
看了不少资料,终于大概理解diffusion每一步的流程与推导了,搞一个案例实践一下,把代码跟公式对一对加深理解。 0、前向与逆向过程 原论文:Denoising Diffusion Probabilistic Models 1、数据集准备 选一个数据集,本例采…

每日最新AIGC进展(59):谷歌提出关键帧插值算法、谷歌研究院提出用实时游戏画面生成算法、中国科学院大学提出复杂场景图像生成算法
Diffusion Models专栏文章汇总:入门与实战 Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation
本研究提出了一种新颖的关键帧插值方法,旨在生成符合自然运动轨迹的连续视频片段。我们适应了已经训练好的图像到视频扩…

浅析扩散模型与图像生成【应用篇】(二十一)——DALLE·2
21. Hierarchical Text-Conditional Image Generation with CLIP Latents 该文提出一种基于层级式扩散模型的由文本生成图像的方法,也就是大名鼎鼎的DALLE2。在DALLE2之前呢,OpenAI团队已经推出了DALLE和GLIDE两个文生图模型了,其中DALLE是基…

相互作用先验下的 3D 分子生成扩散模型 - IPDiff 评测
IPDiff 是一个基于蛋白质-配体相互作用先验引导的扩散模型,首次把配体-靶标蛋白相互作用引入到扩散模型的扩散和采样过程中,用于蛋白质(口袋)特异性的三维分子生成。 本文将对 IPDiff 实际的分子生成能力进行评测。 一、背景介绍 …
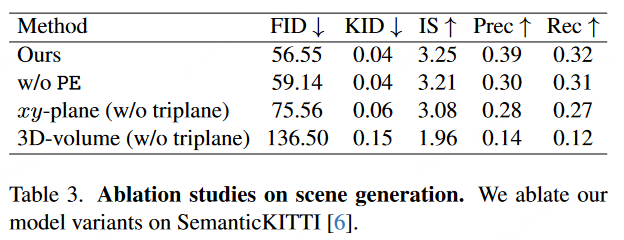
SemCity: 一个应用于真实户外环境场景生成的3D Diffusion模型
论文标题:
SemCity: Semantic Scene Generation with Triplane Diffusion
论文作者:
Jumin Lee1, Sebin Lee1, Changho Jo, Woobin Im, Juhyeong Seon, Sung-Eui Yoon
项目地址:https://sglab.kaist.ac.kr/SemCity/ 前言: 该论…
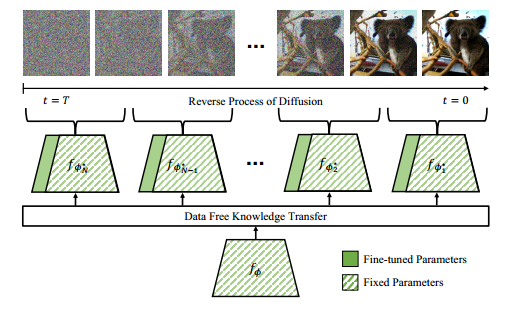
(CVPR-2023)面向实用的即插即用扩散模型
面向实用的即插即用扩散模型 Paper Title:Towards Practical Plug-and-Play Diffusion Models Paper是Riiid AI Research发表在CVPR 2023的工作 paper地址 Code地址 Abstract
基于扩散的生成模型在图像生成方面取得了显著的成功。它们的指导公式允许外部模型即插即…
Open-Sora代码详细解读(1):解读DiT结构
Diffusion Models专栏文章汇总:入门与实战 前言:目前开源的DiT视频生成模型不是很多,Open-Sora是开发者生态最好的一个,涵盖了DiT、时空DiT、3D VAE、Rectified Flow、因果卷积等Diffusion视频生成的经典知识点。本篇博客从Open-Sora的代码出发,深入解读背后的原理。 目录…

Black Forest Labs 的 Flux——文本转图像模型的下一个飞跃,它比 Midjourney 更好吗?
一、前言 Black Forest Labs是开创性稳定扩散模型的团队,现已发布Flux——一套最先进的模型,有望重新定义 AI 生成图像的功能。但 Flux 是否真正代表了该领域的飞跃?它与 Midjourney 等行业领导者相比如何?让我们深入探索 Flux 的…
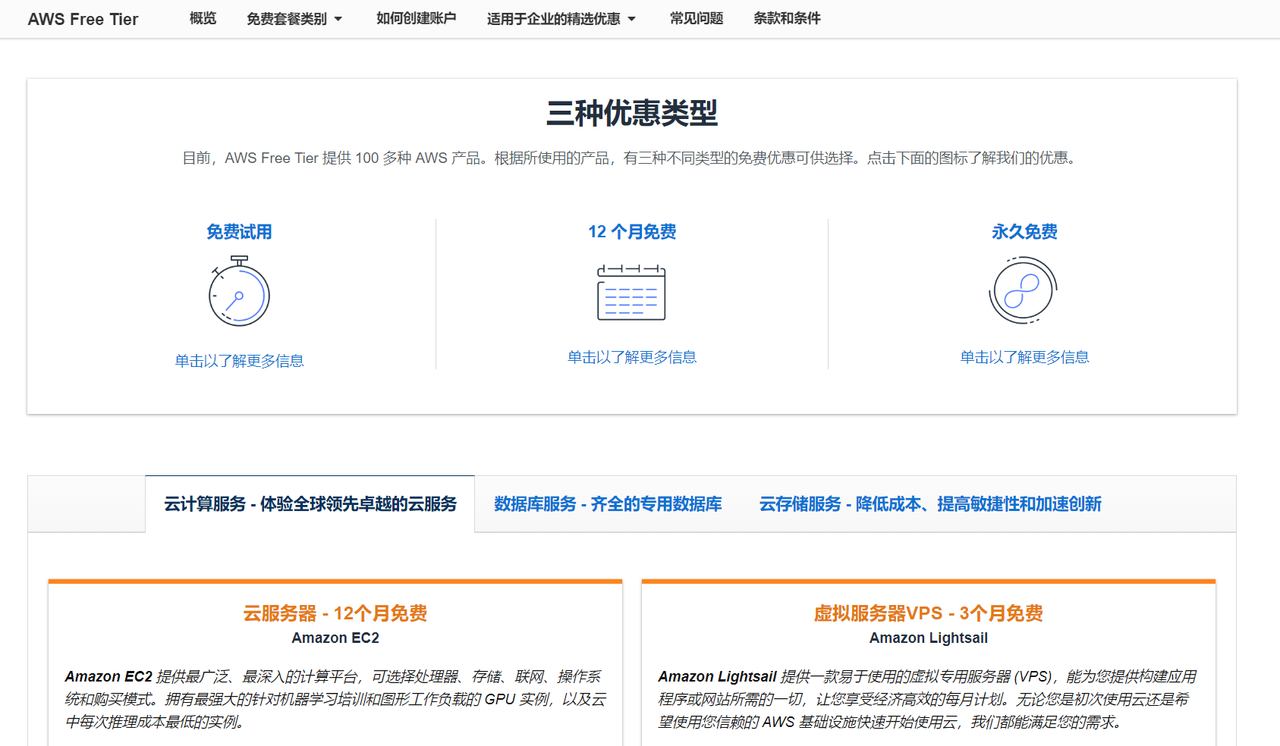
基于 Amazon EC2 快速部署 Stable Diffusion WebUI + chilloutmax 模型
自2023年以来,AI绘图已经从兴趣娱乐逐渐步入实际应用,在众多的模型中,作为闪耀的一颗明星,Stable diffusion已经成为当前最多人使用且效果最好的开源AI绘图软件之一。Stable Diffusion Web UI 是由AUTOMATIC1111 开发的基于 Stabl…
(CVPR-2023)面向实用的即插即用扩散模型
面向实用的即插即用扩散模型 Paper Title:Towards Practical Plug-and-Play Diffusion Models Paper是Riiid AI Research发表在CVPR 2023的工作 paper地址 Code地址 Abstract
基于扩散的生成模型在图像生成方面取得了显著的成功。它们的指导公式允许外部模型即插即…