论文主要贡献
提出一种新的框架:Ego-HOI recognition by Probing, Curation and Adaption (EgoPCA)。构建了全面的预训练集,平衡的测试集,以及一个包含了微调策略的baseline。
在Ego-HOI达到了SOTA,并且建立了有效的机制方法。
Code and data are available here.
已有工作
Ego-HOI(Egocentric Hand-Object Interaction)
目前Transformers, visual-language models 效果较好,后续可以学习一下。
Gap:这些工作大多以第三人称视角学习,少有第一人称的。
具体地,第一人称往往仅包含手部,且存在抖动,导致已有工作能否有效迁移到下游任务还是未知数。
大多工作都是Kinetics上预训练的,这个数据集已经被证明了在自我为中心的视频上有较大gap。
为所有下游任务微调一个共享的预训练模型效率低下,也无法适应每个下游任务或基准。
HOI Understanding
EPICKITCHENS
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Scaling egocentric vision: The epic-kitchens dataset. In ECCV, 2018
EGTEA Gaze+
Yin Li, Miao Liu, and James M Rehg. In the eye of beholder: Joint learning of gaze and actions in first person video. In ECCV, 2018
2D ConvNets
Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks for action recognition in videos. TPAMI, 2018.
MultiStream Networks
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In ICCV, 2019
3D ConvNets
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, 2017
Transformer-based net
Haoqi Fan, Bo Xiong, Karttikeya Mangalam, Yanghao Li, Zhicheng Yan, Jitendra Malik, and Christoph Feichtenhofer. Multiscale vision transformers. In ICCV, 2021
Video Action Recognition
Two-stream
Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K.Q. Weinberger, editors, NeurIPS, 2014
3D CNN
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, 2017.
Transformer methods
…
CLIP
采用大规模图像文本对的对比学习,展示了出色的零样本性能。
ActionCLIP对目标数据集进行端到端微调,并表明微调对于语言和图像编码器都至关重要。
Ego-HOI Videos
Properties
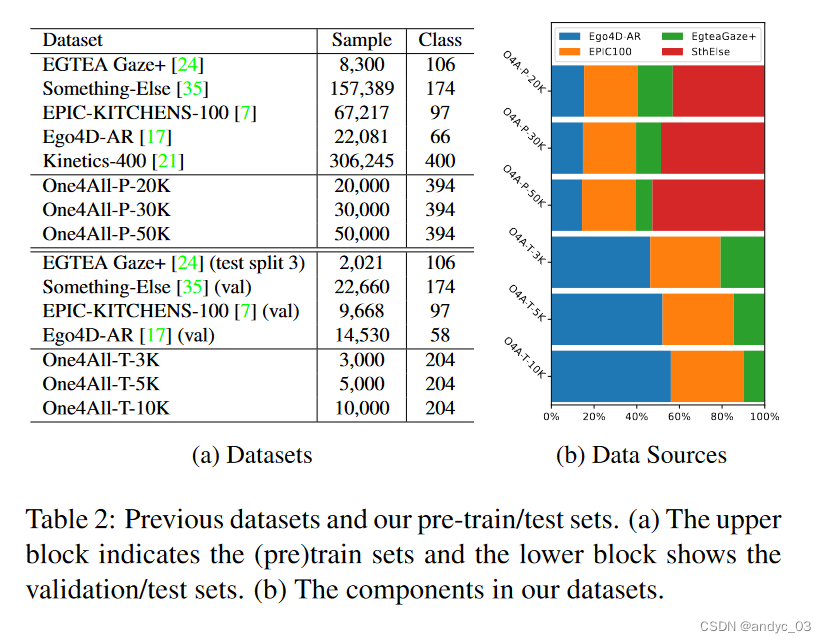
测试在以下五个数据集上:EPIC-KITCHENS-100, EGTEA Gaze+, Ego4D-AR, Something-Else and our One4All-P
-
映射到BERT的词向量上,我们的One4All-P包含了所有的语义空间。

-
通过比较帧之间的密集光流量化每像素相机运动
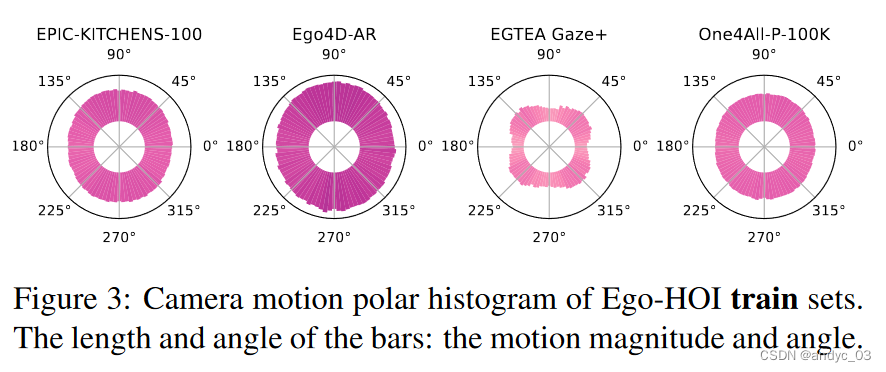
-
帧的拉普拉斯方差来衡量模糊性(Blurriness)
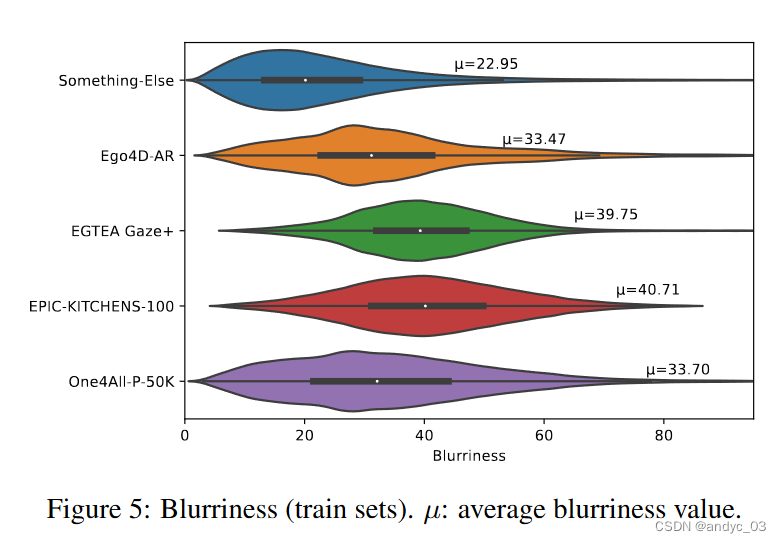
-
通过 MMPose 定位手的位置并且通过 Detic 定位物体的位置
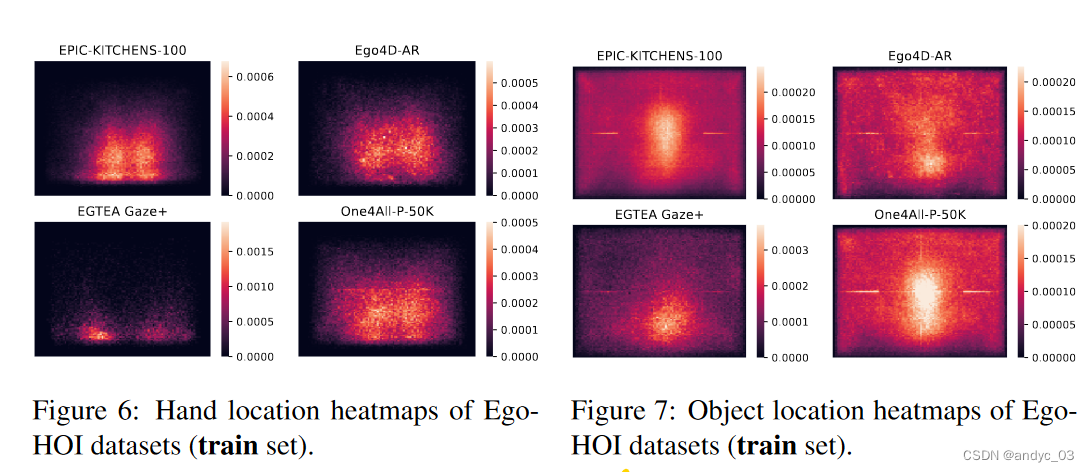 5.通过MMPose现成的姿势检测器定位手的位置形态
5.通过MMPose现成的姿势检测器定位手的位置形态

量化相似性 Kernel Density Estimation (KDE)
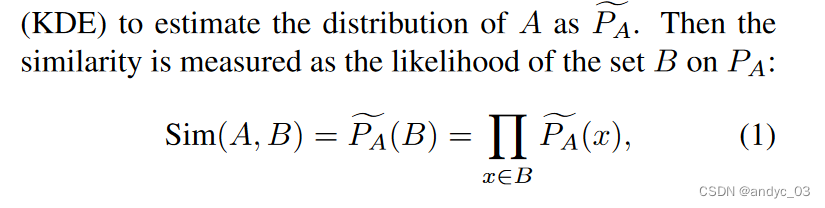
选取高斯核函数,假设有对角化的协方差矩阵,且带宽是Silverman’s estimator选择的。
视频选择算法
提出了一种基于自我属性相似性的选择算法来采样额外的数据,以丰富原始视频集,从而实现平衡或更高的性能。

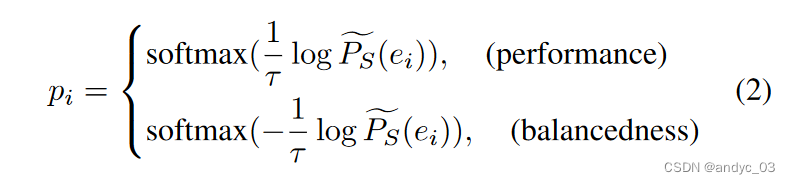 实验结果:
实验结果:
 camera motion, hand location/pose, and object location 为影响较大的因素。
camera motion, hand location/pose, and object location 为影响较大的因素。
通过上述方法,我们可以获得均衡的预训练集和测试集。
预训练流程
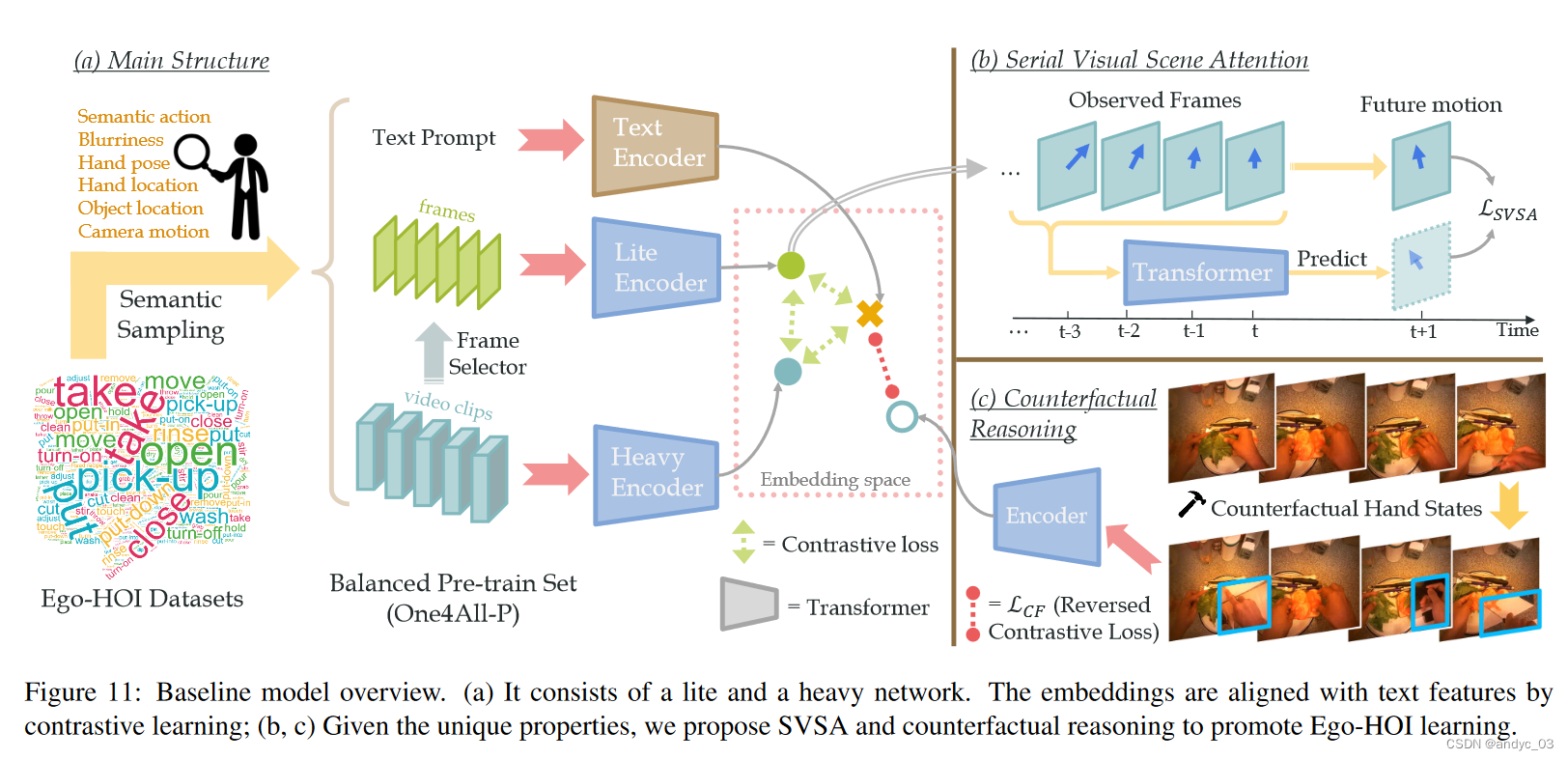
由三个encoder构成:Lite, heavy, text
lite network captures frame-level features while the heavy network learns spatiotemporal features.
These two streams are aligned with the text feature.

训练步骤:
- 框架级lite网络使用Ego - HOI数据中的框架-文本对进行预训练。
- 冻结帧编码器,然后用视频-文本对预训练ATP模块(从多个帧中选择最有价值的一个)
- 帧编码器和ATP模块都被冻结,在我们的One4All - P数据集上联合训练lite和heavy网络。
- 在推理过程中,轻网络和重网络通过与类的文本嵌入的余弦相似度独立地生成预测。这两个流可以通过均值池化来组合,以产生全模型结果。
Serial Visual Scene Attention Learning (SVSA)
希望引入对于视频序列连续的注意机制,以此从其关联的观点来学习人类的意图。
从语义特征流中预测视图中心的移动。
Figure11 (b) 中也有体现
Counterfactual Reasoning for Ego-HOI
反事实因果关系研究的是事件的结果,如果事件没有实际发生,我们利用反事实学习来增强因果鲁棒性。
通过以下两种方式构造反事实的例子:
1 ) 用具有不同手部姿势或动作标签的同一视频中的帧替换整帧
2 ) 用具有不同手部姿势或动作标签的其他帧的手框替换手部区域
此外还进行了数据剪枝,来减小无用的数据(可能包含高KDE的数据)
通过消融实验,验证了SVSA和Counterfactural Reasoning 模块的意义。
![[移动端] “viewport“ content=“width=device-width, initial-scale=1.0“ 什么意思](https://img-blog.csdnimg.cn/direct/0a3e56de0b4e4865b8398603fcf5c02c.png)