作者:来自 Elastic Benjamin Trent, Thomas Veasey
在 Lucene 中引入 Int4 量化
在之前的博客中,我们全面介绍了 Lucene 中标量量化的实现。 我们还探索了两种具体的量化优化。 现在我们遇到了一个问题:int4 量化在 Lucene 中是如何工作的以及它是如何排列的?
存储量化向量并对其进行评分
Lucene 将所有向量存储在一个平面文件中,从而可以根据给定的序数检索每个向量。 你可以在我们之前的标量量化博客中阅读对此的简要概述。
现在 int4 为我们提供了比以前更多的压缩选项。 它将量化空间减少到只有 16 个可能的值(0 到 15)。 为了更紧凑的存储,Lucene 使用一些简单的位移操作将这些较小的值打包到单个字节中,在 int8 已经节省 4 倍空间的基础上,还可以节省 2 倍空间。 总之,使用位压缩存储 int4 比 float32 小 8 倍。

int4 在计算延迟方面也有一些好处。 由于已知值在 0-15 之间,因此我们可以利用准确了解何时担心值溢出并优化点积计算。 点积的最大值为 15*15=225,可以容纳在一个字节中。 ARM 处理器(如我的 MacBook)的 SIMD 指令长度为 128 位(16 字节)。 这意味着对于 Java Short,我们可以分配 8 个值来填充通道。 对于 1024 维,每个通道最终将累积总共 1024/8=128 次乘法,最大值为 225。所得的最大和 28800 完全符合 Java 短值的限制,我们可以迭代更多值一次比。 下面是 ARM 的一些简化代码。
// snip preamble handling vectors longer than 1024
// 8 lanes of 2 bytes
ShortVector acc = ShortVector.zero(ShortVector.SPECIES_128);
for (int i = 0; i < length; i += ByteVector.SPECIES_64.length()) {// Get 8 bytes from vector aByteVector va8 = ByteVector.fromArray(ByteVector.SPECIES_64, a, i);// Get 8 bytes from vector bByteVector vb8 = ByteVector.fromArray(ByteVector.SPECIES_64, b, i);// Multiply together, potentially saturating signed byte with a max of 225ByteVector prod8 = va8.mul(vb8);// Now convert the product to accumulate into the shortShortVector prod16 = prod8.convertShape(B2S, ShortVector.SPECIES_128, 0).reinterpretAsShorts();// Ensure to handle potential byte saturationacc = acc.add(prod16.and((short) 0xFF));
}
// snip, tail handling计算误差修正
有关误差校正计算及其推导的更详细说明,请参阅误差校正标量点积。
这是一个简短的总结,遗憾的是(或高兴的是)没有复杂的数学。
对于存储的每个量化向量,我们还跟踪量化误差校正。 回到标量量化 101 博客中,提到了一个特定的常数:
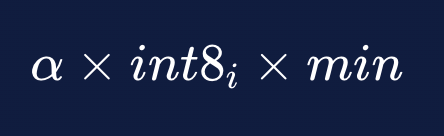
该常数是从基本代数导出的简单常数。 但是,我们现在在存储的浮点数中包含与舍入损失相关的附加信息。

在这里,i 是每个浮点向量维度, 是每个浮点向量维度,且
。
这有两个后果。 第一个是直观的,因为这意味着对于给定的一组量化桶,我们会稍微更准确,因为我们考虑了量化的一些损耗。 第二个结果有点微妙。 现在这意味着我们有一个受量化分桶影响的纠错措施。 这意味着它可以被优化。
寻找最佳分桶
进行标量量化的简单而简单的方法可以让你走得很远。 通常,你选择一个置信区间,从中计算向量值允许的极端边界。 Lucene 和 Elasticsearch 中的默认值是
1−1/(dimensions+1) 。图 2 显示了一些 CohereV3 嵌入样本的置信区间。 图 3 显示了相同的向量,但使用静态设置的置信区间进行标量量化。
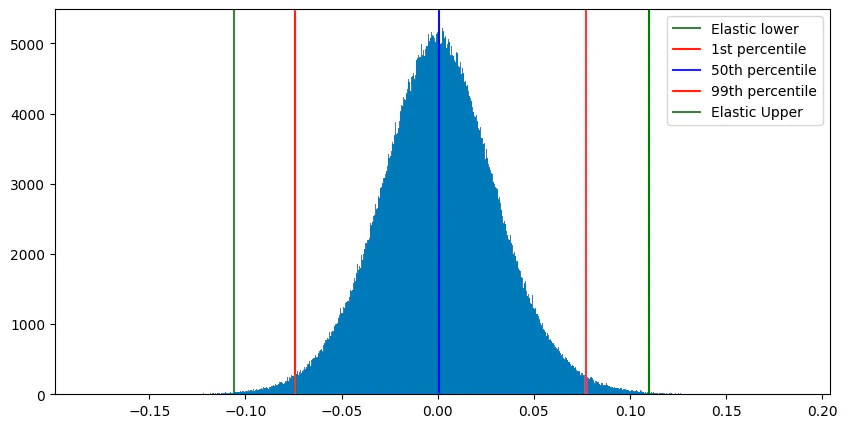
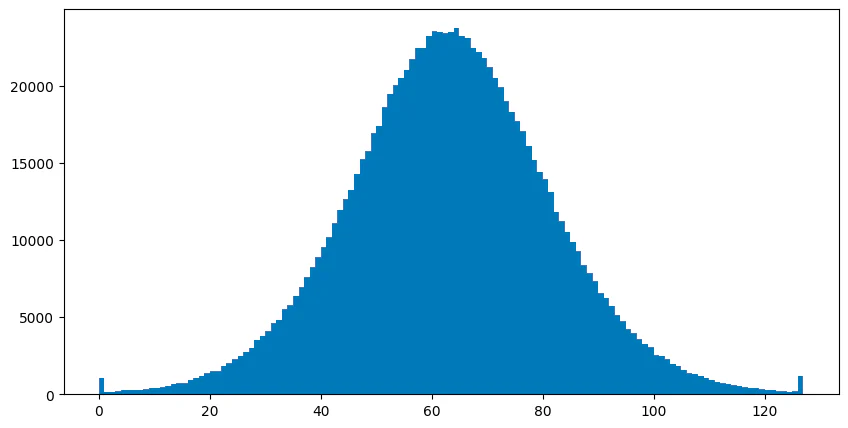
但是,我们留下了一些不错的优化。 如果我们可以调整置信区间来移动存储桶,从而允许更重要的维度值具有更高的保真度,该怎么办? 为了优化,Lucene 执行以下操作:
- 从数据集中采样大约 1,000 个向量并计算它们真正的最近 10 个邻居。
- 计算一组候选上分位数和下分位数。 该集合是通过使用两个不同的置信区间来计算的:1−1/(dimensions+1) 及 1−(dimensions/10)/(dimensions+1)。这些间隔处于相反的极端。 例如,具有 1024 个维度的向量将搜索置信区间 0.99902 和 0.90009 之间的候选分位数。
- 对这两个置信区间之间存在的分位数子集进行网格搜索。 网格搜索找到使量化得分误差的确定系数与之前计算的真实 10 个最近邻相比最大的分位数。
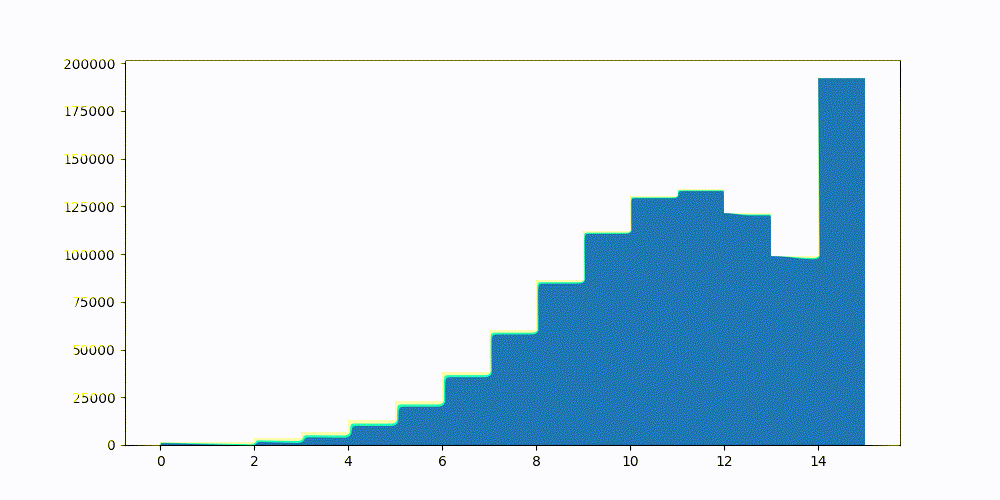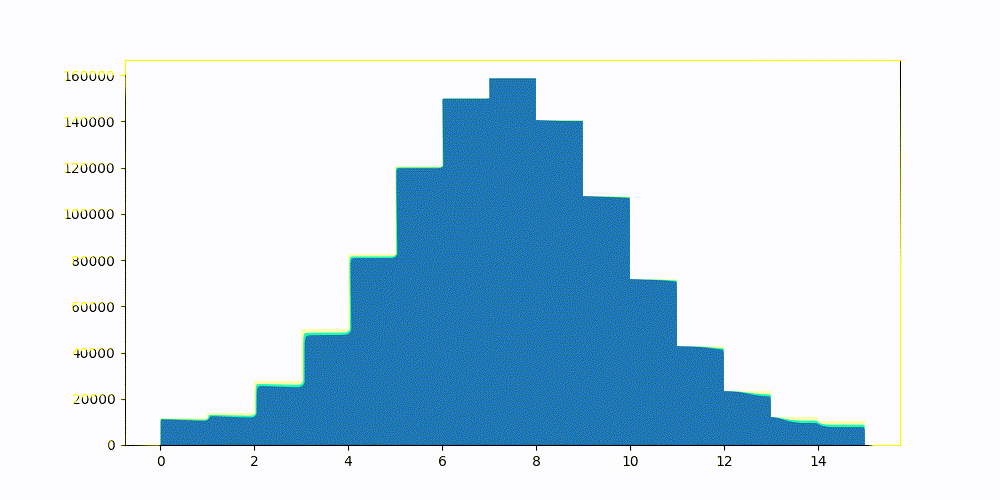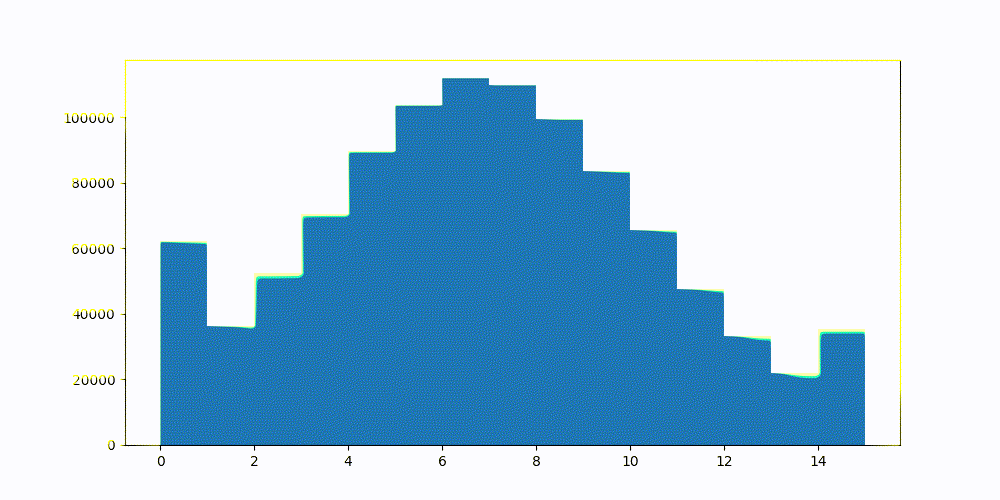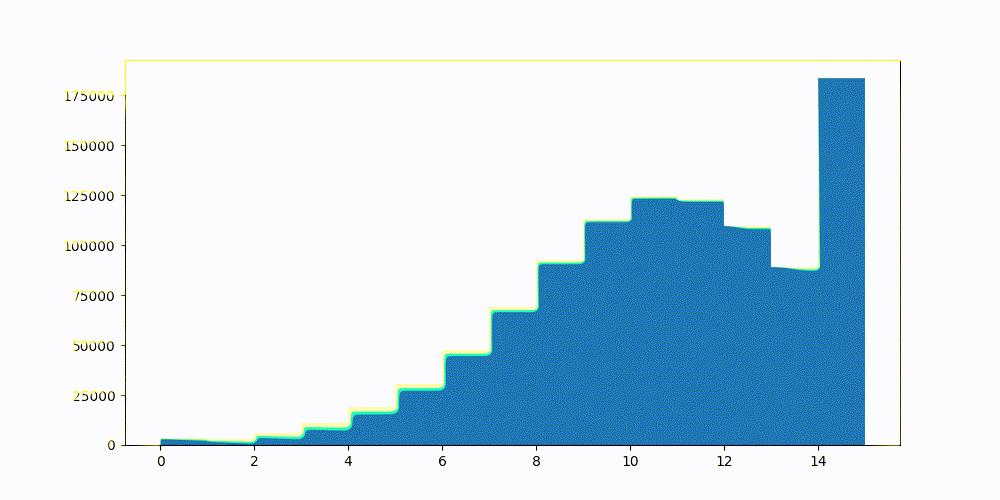

有关优化过程和优化背后的数学原理的更完整说明,请参阅优化截断间隔。
量化速度与大小
正如我之前提到的,int4 为你提供了性能和空间之间有趣的权衡。 为了说明这一点,以下是 CohereV3 500k 向量的一些内存要求。
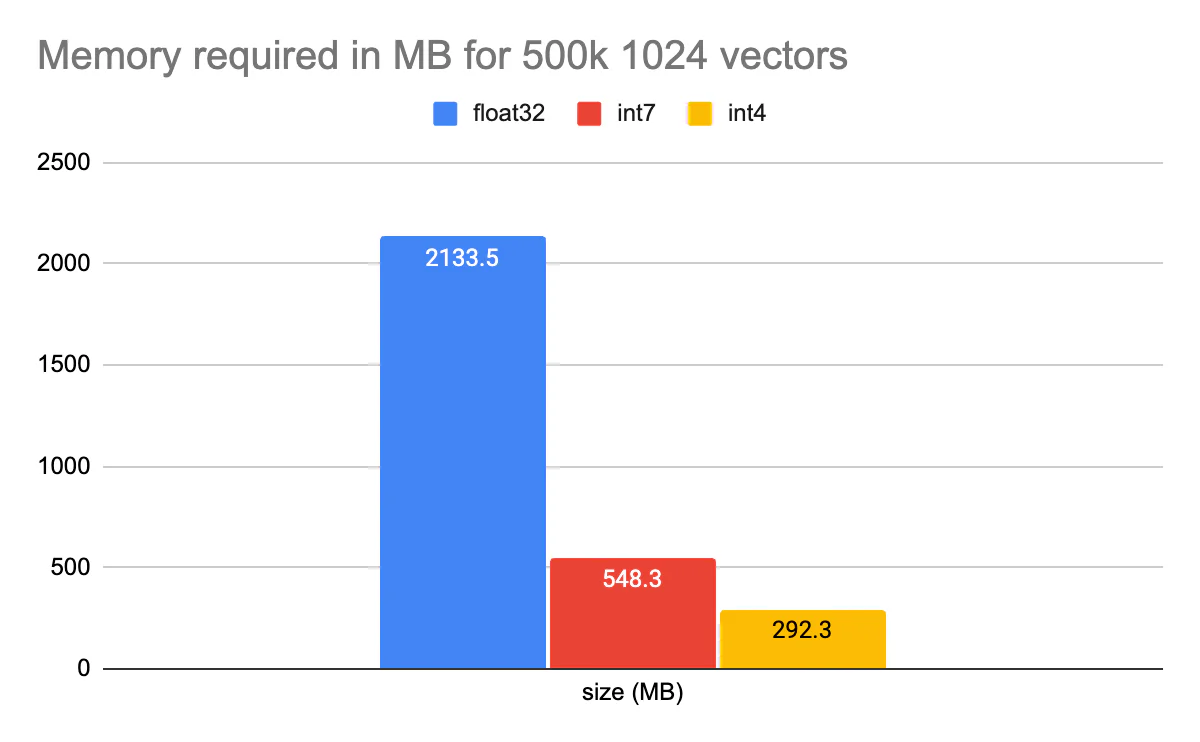
当然,我们看到常规标量量化典型地减少了 4 倍,但使用 int4 又减少了 2 倍。 将所需内存从 2GB 减少到 300MB 以下。 请记住,这是启用压缩的情况。 解压缩和压缩字节在搜索时确实会产生开销。 对于每个字节向量,我们必须在进行 int4 比较之前对其进行解压缩。 因此,当在 Elasticsearch 中引入这一功能时,我们希望让用户能够选择压缩或不压缩。 对于某些用户来说,更便宜的内存要求是不容错过的,而对于其他用户来说,他们关注的是速度。 Int4 提供了调整设置以适合你的用例的机会。
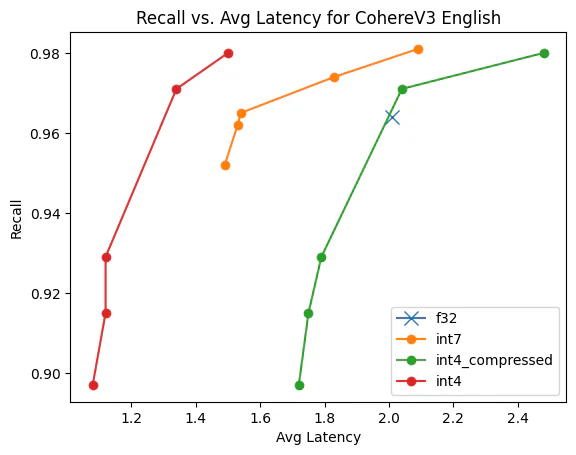
结束 ?
在过去的两篇大型技术博客文章中,我们回顾了有关优化的数学和直觉以及它们给 Lucene 带来的影响。 这是一段漫长的旅程,我们还远远没有完成。 请在未来的 Elasticsearch 版本中关注这些功能!
准备好将 RAG 构建到你的应用程序中了吗? 想要尝试使用向量数据库的不同 LLMs?
在 Github 上查看我们的 LangChain、Cohere 等示例笔记本,并参加即将开始的 Elasticsearch 工程师培训!
原文:Int4: More Scalar Quantization in Lucene — Elastic Search Labs