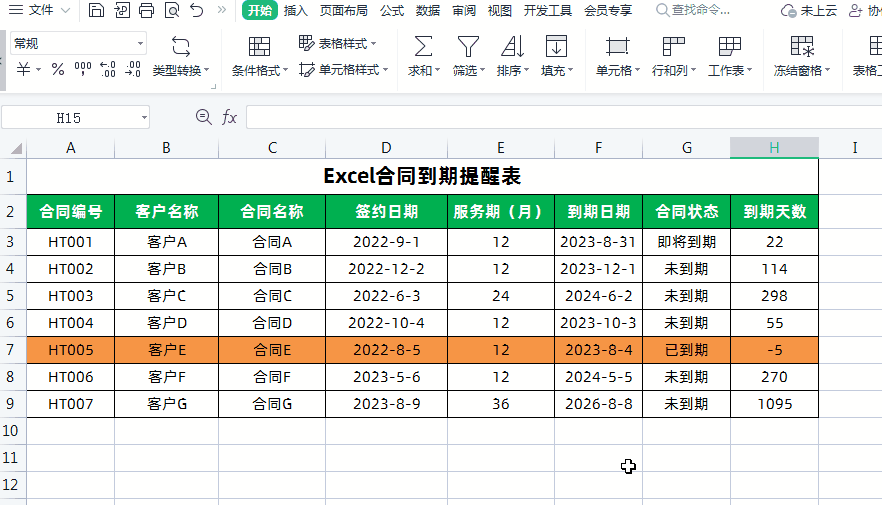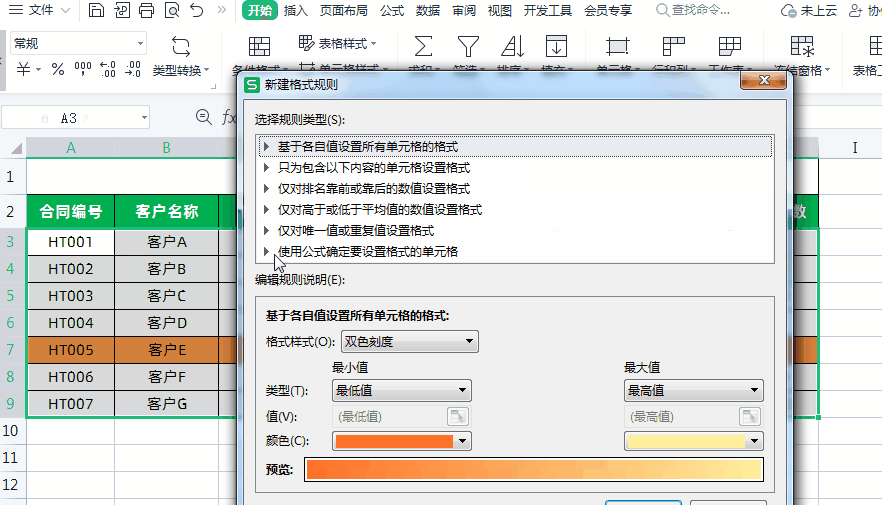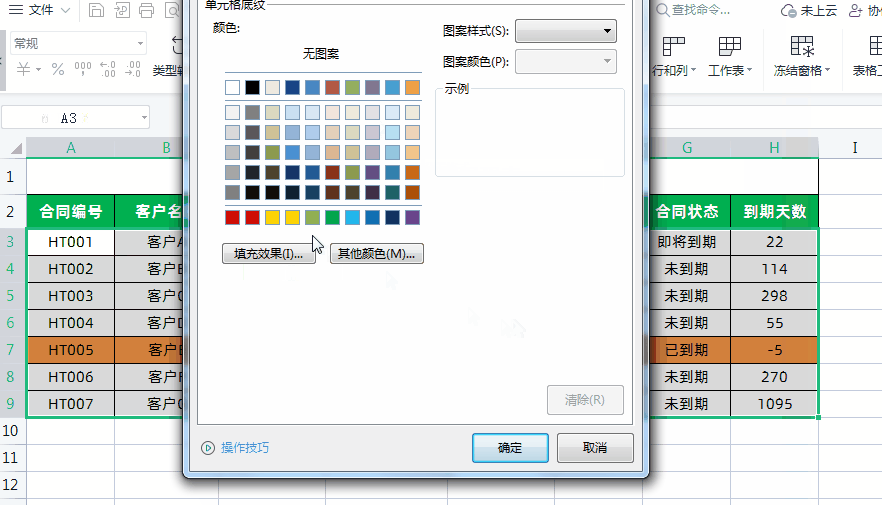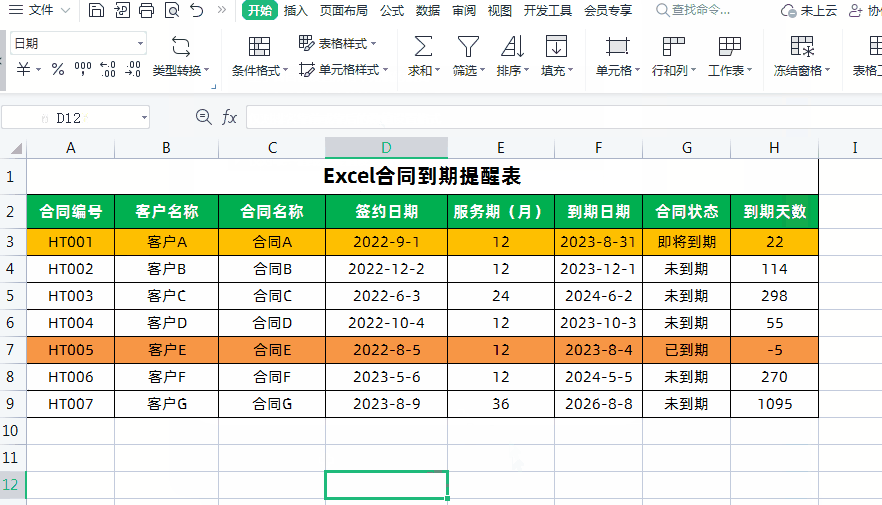
N-Gram模型概念
N-Gram模型是一种基于统计的语言模型,用于预测文本中某个词语的出现概率。它通过分析一个词语序列中前面N-1个词的出现频率来预测下一个词的出现。具体来说,N-Gram模型通过将文本切分为长度为N的词序列来进行建模。
注意:这里的一个Gram(词)不一定是一个单词一个汉字,也可以是一个词组,一个短语,比如“唐僧”、“自然语言”等,还可以是一个字符,比如playing可以分为 play 和 ##ing 这2个Gram。
-
Unigram(1-Gram): 仅依赖于当前词的概率。例如,给定一个句子“我 爱 自然语言”,它将被切分为“我”,“爱”,“自然语言”三个独立的词。
-
Bigram(2-Gram): 使用前一个词来预测下一个词。例如,在句子“我 爱 自然语言”中,Bigram模型将考虑“我 → 爱”和“爱 → 自然语言”两个词对的概率。
-
Trigram(3-Gram): 使用前两个词来预测下一个词。例如,句子“我 爱 自然语言”可以表示为“我 爱 → 自然语言”的三元组。
主要特点:
- 局部上下文:N-Gram模型假设一个词的出现仅依赖于前面N-1个词。这意味着它没有考虑词序列中更远的上下文信息。
- 简易实现:N-Gram模型实现简单,可以用于机器翻译、文本生成、自动纠错等多种任务。
- 数据稀疏问题:随着N的增大,可能会遇到数据稀疏问题,因为某些N-Gram组合可能在训练数据中没有出现过。
优缺点:
- 优点:
- 简单易懂,容易实现。
- 可以在不需要太复杂计算的情况下,对语言进行一定的建模。
- 缺点:
- 模型可能会忽略远距离词之间的依赖关系,限制了其对复杂语言模式的捕捉能力。
- 数据稀疏问题:如果某个N-Gram在训练数据中没有出现过,模型就无法进行有效预测。
应用场景:
- 自动文本生成:通过N-Gram模型,可以生成流畅的文本,虽然在复杂度和语义准确度上有一定局限性。
- 拼写纠错:可以根据大数据中最常见的词组合来判断用户输入是否有误。
- 语言翻译:基于N-Gram的机器翻译模型,虽然如今已经被更先进的模型(如神经网络)所取代,但仍然有其历史意义。
N-Gram模型的构建过程
1. 数据预处理
首先,获取原始文本数据,并对其进行预处理。这个过程通常包括:
- 文本清洗:去除无用的符号、标点符号、特殊字符、HTML标签等。
- 分词:将文本划分为词(或字),这是N-Gram模型的基础。在不同语言中,分词的方法可能有所不同。 一般的自然语言处理工具包都为我们提供好了分词的工具。比如,英文分词通常使用NLTK、spaCy等自然语言处理库,中文分词通常使用jieba库(中文NLP工具包),而如果你将来会用到BERT这样的预训练模型,那么你就需要使用BERT的专属分词器Tokenizer,它会把每个单词拆成子词——这是BERT处理生词的方法。
- 去除停用词(可选):停用词是指在某些任务中不重要的词,比如“的”、“是”等。虽然在一些情况下,停用词不被删除,但在构建模型时有时会去除这些词以提高效率。
2. 生成N-Grams
在数据预处理完成后,接下来就是生成N-Grams。在这一过程中,将文本划分为连续的N个词组成的序列。
- Unigram:每个单独的词构成一个N-Gram。例如,文本“我 爱 自然语言”会变成 ["我", "爱", "自然语言"]。
- Bigram:将相邻的两个词作为一个N-Gram。例如,文本“我 爱 自然语言”会变成 ["我 爱", "爱 自然语言"]。(可称为二元组)
- Trigram:将相邻的三个词作为一个N-Gram。例如,文本“我 爱 自然语言”会变成 ["我 爱 自然语言"]。
3. 计算N-Gram频率
对于生成的N-Grams,计算它们在整个训练语料中出现的频率。这通常使用一个词频统计工具或者简单的计数器来完成。例如,假设你的文本数据中出现了以下的Bigram:
- “我 爱” 出现了5次
- “爱 自然语言” 出现了3次
- “我 学习” 出现了2次
4. 计算概率
N-Gram模型的核心就是通过计算每个N-Gram的出现概率。对于一个N-Gram模型,我们需要计算一个特定N-Gram的条件概率,表示给定前N-1个词的情况下,某个特定词出现的概率。如,二元组“我爱”在语料库中出现了3次,而二元组的前缀“我”在语料库中出现了10次,则给定“我”,下一个词为“爱”的概率为30%(如下图所示)。

给定“我”,下一个词为“爱”的概率为30%
5、预算文本
可以使用这些概率来预测文本中下一个词出现的可能性。多次迭代这个过程,甚至可以生成整个句子,也可以算出每个句子在语料库中出现的概率。
比如,从一个字“我”,生成“爱”,再继续生成“吃”,直到“我爱吃肉”这个句子。计算“我爱”“爱吃”“吃肉”出现的概率,然后乘以各自的条件概率,就可以得到这个句子在语料库中出现的概率了。

哪一个词更可能出现在“爱”后面
总结
N-Gram模型是一个简单而有效的语言建模方法,但对于复杂的语言依赖关系,它有一定的局限性。