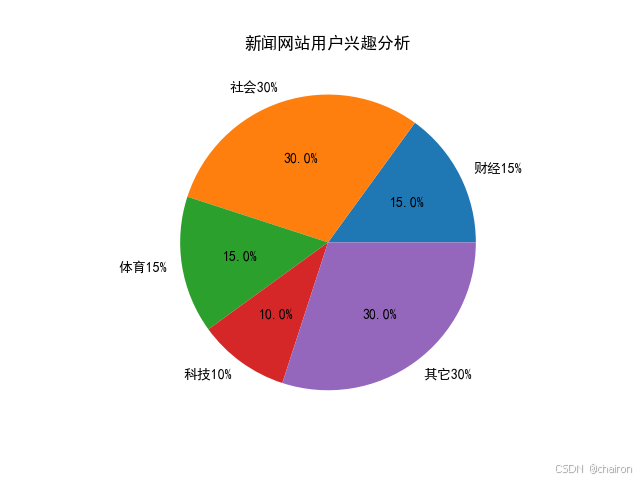
1. 饼图:显示基本比例关系
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# ——————————————————————————————————————————————————————————
#1.饼图:显示基本比例关系# 定义饼图的标签,对应不同的用户兴趣类别
labels = '财经15%', '社会30%', '体育15%', '科技10%', '其它30%'# 定义饼图的大小,对应每个类别的用户兴趣比例
datas = [15, 30, 15, 10, 30]# 创建一个figure对象和axes对象,用于绘制饼图
fig1, ax1 = plt.subplots()
pie = ax1.pie(datas, labels=labels, autopct='%1.1f%%')# 设置整个图表的标题
plt.title('新闻网站用户兴趣分析')# 显示图表
plt.show()
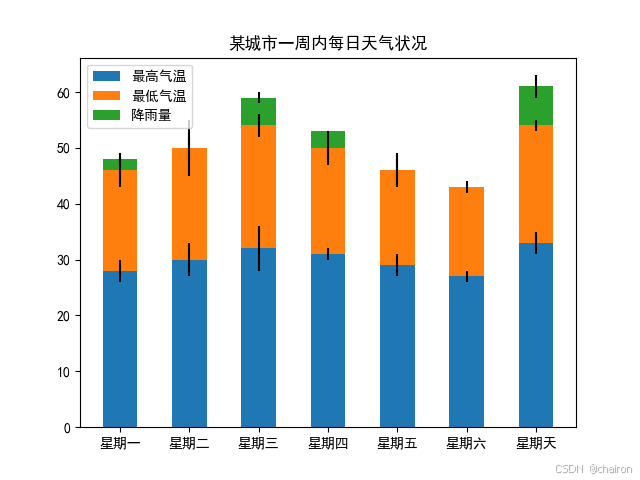
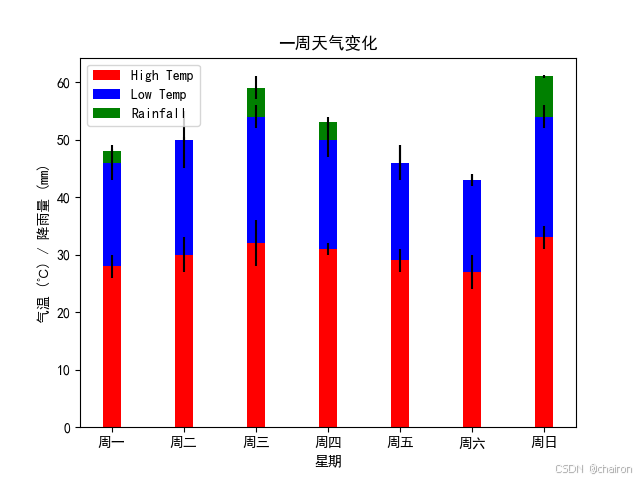
2. 堆叠柱形图
它将两个或多个变量的值在同一个轴上以堆叠的形式展示出来,使得观察者可以清晰地看到每个变量的总和以及它们各自的部分。
#练习2:某城市一周内每日天气状况
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 一周内每天的日期
days = ['周一', '周二', '周三', '周四', '周五', '周六', '周日']# 一周内每天的最高气温、最低气温和降雨量
high_temps = [28, 30, 32, 31, 29, 27, 33]
low_temps = [18, 20, 22, 19, 17, 16, 21]
rainfall = [2, 0, 5, 3, 0, 0, 7]# 使用arange函数生成一个数组,表示条形图的x坐标位置
x = np.arange(7)
# 设置柱状图的宽度
bar_width = 0.25# 误差条
high= (2, 3, 4, 1, 2,3,2)
low = (3, 5, 2, 3, 3,1,2)
rain= (0.3, 0.5, 2, 1, 3,1,0.2)
# 绘制柱状图
plt.bar(x, high_temps,color='red', width=bar_width,yerr=high, label='High Temp')
plt.bar(x, low_temps, bottom=high_temps,color='blue', width=bar_width, yerr=low, label='Low Temp')
plt.bar(x, rainfall, bottom=(np.array(low_temps)+np.array(high_temps)),color='green', width=bar_width, yerr=rain, label='Rainfall')# 添加图例
plt.legend()# 添加标题和标签
plt.xlabel('星期')
plt.ylabel('气温 (℃) / 降雨量 (mm)')
plt.title('一周天气变化')# 设置x轴的刻度标签
plt.xticks(x,('周一', '周二', '周三', '周四', '周五', '周六', '周日'))
# # 添加图例
# plt.legend((p1[0], p2[0], p3[0]), ('最高温度', '最低温度', '降雨量'))# 显示图形
plt.show()
3. 板块层级图
- 通常是一种用于展示不同板块之间层级关系或分类的图表,可以是组织结构图、分类图或其他类型的层级表示方法。
- 安装squarify:
pip install squarify
# 练习3:公司部门年度收入分布
import matplotlib.pyplot as plt
import squarify
# 定义部门和对应的收入
departments = ['技术部', '市场部', '人力资源部', '财务部']
revenues = [10, 15, 50, 30] # 转换为相同的数量级以方便计算
# 定义每个部门的颜色
colors = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728']
# 绘制板块层级图
squarify.plot(sizes=revenues, label=departments, color=colors, alpha=0.7)
plt.axis('off')
plt.title('公司部门年度收入分布')
plt.show()
4. 堆叠面积图
安装seaborn: pip install seaborn
- 用于显示每个数值所占大小随时间或类别变化的趋势线,展示的是部分与整体的关系。
- 堆叠面积图上的最大的面积代表了所有的数据量的总和,是一个整体。
- 各个叠起来的面积表示各个数据量的大小,这些堆叠起来的面积图在表现大数据的总量分量的变化情况时格外有用,所以堆叠面积图不适用于表示带有负值的数据集。非常适用于对比多变量随时间变化的情况。
import numpy as np
# 导入seaborn库,用于高级的统计图表绘制
import seaborn as snsx = range(21, 26)# 定义x轴的数据,这里表示年龄范围
# 定义y轴的数据,这里是一个二维数组,表示不同组在不同年龄的分值
y = [[10, 4, 6, 5, 3],[12, 2, 7, 10, 1],[8, 18, 5, 7, 6],[1, 8, 3, 5, 9]]
labels = ['组A', '组B', '组C', '组D']# 定义每个组的标签
pal = sns.color_palette("Set1")# 使用seaborn的color_palette函数生成一组颜色
# 使用plt.stackplot函数绘制堆叠面积图
plt.stackplot(x, y, labels=labels, colors=pal, alpha=0.7)# alpha参数指定透明度,colors=pal, alpha=0.7:可选项
plt.ylabel('分值')
plt.xlabel('年龄')
plt.title('不同组用户区间分值比较')
plt.legend(loc='upper right')
plt.show()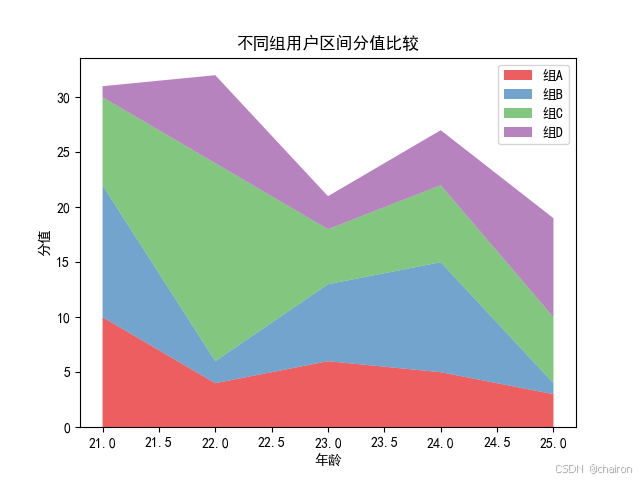
5. 散点图和气泡图
散点图(Scatter Plot)是一种用于显示两个变量之间关系的图表,通过在坐标平面上描绘点来展示数据的分布和趋势。
import numpy as np
import matplotlib.pyplot as plt
import randomplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 设置随机种子,确保结果的可重现性
np.random.seed(42)# ------------------------------------------------------------------
#1.生成散点图
data = {'城市': ['A', 'B', 'C', 'D', 'E'],'温度': [22, 24, 26, 23, 25],'相对湿度': [60, 65, 70, 55, 68],}x = data['温度']
y = data['相对湿度']
print(x)
print(y)
# #气泡图需要修改颜色和大小
# #------------------------------
# color = np.random.rand(5)
color1 = ["red",'blue','yellow','black','green']
# size = np.random.rand(5)*1000#【0,1)-->[0,1000)
size1 = [100,20,30,600,400]
# #---------------------------------# 使用scatter函数绘制散点图,s=100表示点的大小,c='black'表示点的颜色为黑色,alpha=0.8表示点的透明度
# plt.scatter(x, y)
plt.scatter(x, y,s=size1,c=color1, alpha=0.6)plt.title("随机生成的数字散点")
plt.ylabel('Y坐标值')
plt.xlabel('X坐标值')
# 显示图表
plt.show()散点图:

气泡图:就是改变散点图的大小和颜色(随机生成)

6.直方图
一种用于展示数据分布特征的统计图表,它通过将数据分组并计算每组中的频数或频率来表示数据的分布情况。
##3.直方图:
"""用于展示数据分布特征的统计图表,
它通过将数据分组并计算每组中的频数或频率来表示数据的分布情况。"""
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
np.random.seed(19680801)mu = 100 # 均值
sigma = 15 # 标准差
x = mu + sigma * np.random.randn(500)# 根据正态分布生成随机样本数据num_bins = 10# 设置直方图的箱数fig, ax = plt.subplots()# fig是整个图形的容器,ax是图形的轴
ax.hist(x, num_bins, density=True, alpha=0.6,edgecolor='black')#density=True表示y轴显示概率密度而非计数
ax.set_xlabel('智商IQ')
ax.set_ylabel('概率密度')
ax.set_title(r'智商分布情况直方图')# plt.hist(x,num_bins,density=False)
# plt.xlabel('学生人数')
# plt.ylabel('考试成绩')
# plt.title('学生考试成绩分布')plt.show()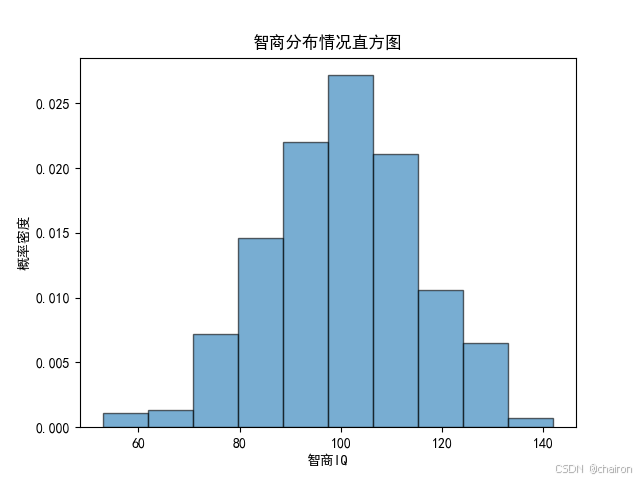
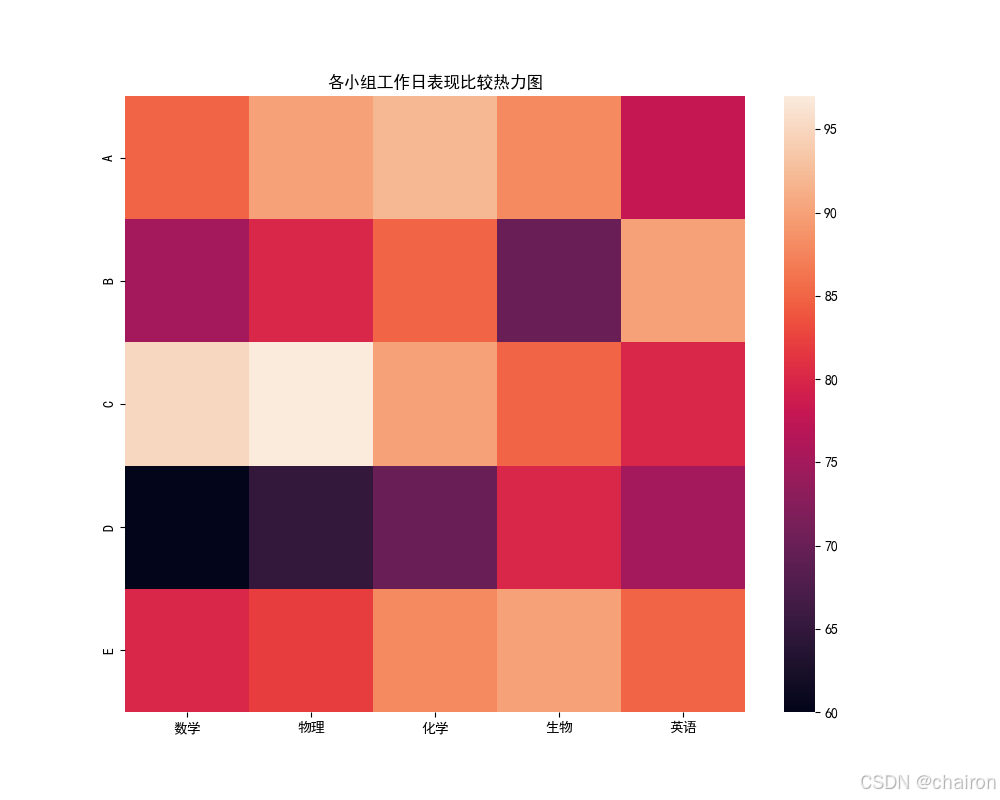
7. 热力图(heatmap)
是一种数据可视化技术,它通过颜色的变化来展示数据矩阵中数值的大小。
##4.heatmap热力图:通过颜色的变化来展示数据矩阵中数值的大小。
import seaborn as sns
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as pltplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=Falsestudents = ['A', 'B', 'C', 'D', 'E']
subjects = ['数学', '物理', '化学', '生物', '英语']# 生成随机成绩数据
#np.random.seed(0) # 为了结果的可重复性
data = { '数学': [85, 75, 95, 60, 80],'物理': [90, 80, 97, 65, 82],'化学': [92, 85, 90, 70, 88],'生物': [88, 70, 85, 80, 90],'英语': [78, 90, 80, 75, 85]}print(data)# 创建DataFrame
df = pd.DataFrame(data, index=students,columns=subjects)
print(df)# 使用Seaborn绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(df, xticklabels=subjects, yticklabels=students)
# 设置图表标题
plt.title('各小组工作日表现比较热力图')
# 显示图表
plt.show()
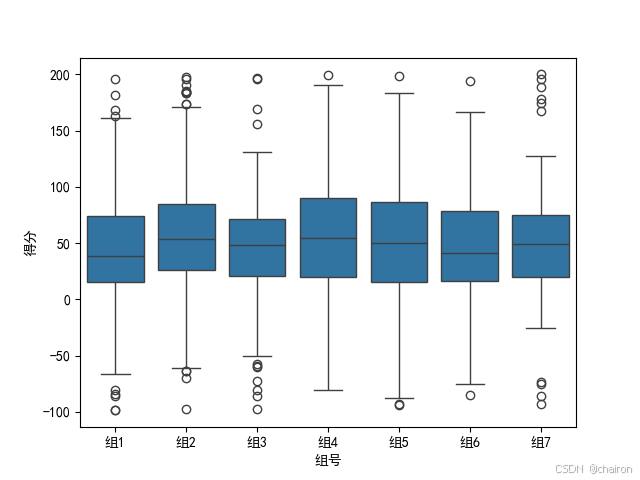
8. 箱型图
是一种非常有用的数据可视化工具,它不仅可以展示数据的中位数、四分位数,还可以直观地表示异常值,帮助用户快速了解数据的集中趋势、分散程度和异常情况。
#5.box:小组成员的得分情况
"""箱型图:展示数据的中位数、四分位数,还可以直观地表示异常值,
帮助用户快速了解数据的集中趋势、分散程度和异常情况。
"""
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import randomplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号# 设置随机种子以确保结果的可重现性
np.random.seed(42)# 生成组号列表
day_list = ['组1', '组2', '组3', '组4', '组5', '组6', '组7']
day = [random.choice(day_list) for _ in range(1000)]#从day_list随机选取1000个数据存入day
print(day)
# 重新设置随机种子,生成数据(800个正常数据,200个离群数据)
np.random.seed(666)
spread = np.random.rand(800) * 100 # 生成800个0~100之间的随机数,np.random.rand(800) :800个[0,1)的数据
flier_high = np.random.rand(100) * 100 + 100 # 生成100个100~200之间的随机数
flier_low = np.random.rand(100) *100 -100 # 生成100个-100~0之间的随机数
# #
# # # 将数据合并为一个数组
data = np.concatenate((spread, flier_high, flier_low), 0)
# data1={'组号': day,
# '得分': data}
# # # 创建DataFrame
# df = pd.DataFrame(data1)
df = pd.DataFrame({'组号': day,'得分': data})
print(df)
# # 使用Seaborn绘制箱型图
sns.boxplot(x='组号', y='得分', data=df)
#
# # 设置x轴的刻度标签
# plt.xticks(range(len(day_list)), day_list)
plt.xticks(range(7), day_list)
#
# # 显示图表
plt.show()