引言
在之前的Python系列文章中,我们介绍的更多的是Python相关的基础语法知识,以及一些常用的类库的使用。但是,Python的实用价值并没有能够很好地体现出来。
为了更加便于不同专业背景、不同领域的Python爱好者能够真正掌握Python的使用,体会到Python的巨大创造力。从今天的这篇文章开始,就不同的领域对Python的实用性进行进一步的阐释说明。
之所以首先是关于Python数据科学的系列内容,是因为对数据的收集、处理、分析及可视化的能力已经成为一项各行各业所必备的硬技能,是一个相对来说更加通用的能力。
本文的主要内容有:
1、数据科学的概念
2、数据科学的主要内容
3、Python常用的数据科学库
数据科学的概念
数据科学(Data Science)是一个跨学科的领域,旨在通过进行数据的收集、处理、分析、可视化等,从中提取洞见、知识和价值。
它结合了统计学、数学、计算机科学、领域相关知识等,以辅助推进实际问题的解决及支撑业务决策。
“跨学科”是数据科学的关键,所以,数据科学也被认为是目前为止对跨学科技能的最佳称呼,在工业界和学术界等各个领域的诸多应用中发挥着越来越大的作用。
数据科学本质上不是一门新的科学或者学科,是一个定义相对模糊的概念。
关于数据科学的定义、描述或者批评,典型的有如下这些:
1、这是一项需要比大多数统计学家更多的编程技巧,和比程序员更多的统计数据技能的工作。
2、是应用统计,但在旧金山却不是。
3、有人突然决定在自己名片上印上“数据科学家”这几个字,然后靠着这个涨了工资。
4、数据科学只是一个多余的标签,毕竟没有哪一门科学不需要数据。
5、知识一个粉饰简历、吸引技术招聘者眼球的噱头。
虽然各种定义、批评不断,但是业界比较公认的对数据科学的定义,要数Drew Conway在2010年9月在自己的博客上首次发表的数据科学维恩图:
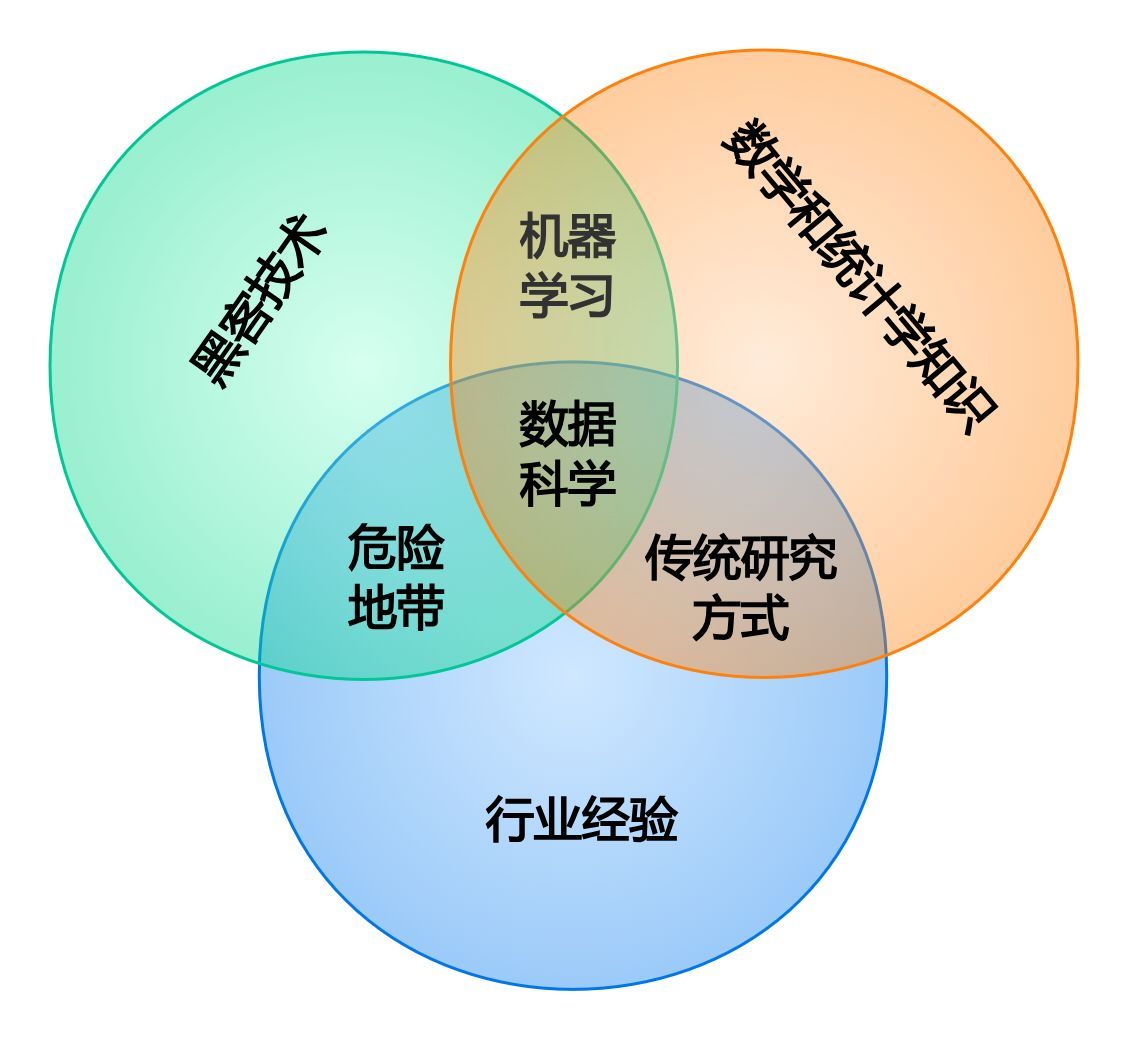
从图中可以看到数据科学的真谛——“跨学科”,数据科学至少综合了三个领域的能力:
1、统计学家和数学家的能力:能够建立数学模型和聚合数量越来越庞大的数据。
2、计算机科学家的能力:能够设计和使用算法对数据进行高效存储、分析和可视化。
3、领域专家的能力:在细分领域中经过专业训练,既可以提出正确的问题,又可以做出专业的解答(很多时候,提出正确的问题是更加困难的事情)。
数据科学的主要内容
按照数据学科解决问题、支撑决策的流程来看,数据科学主要包括以下关键内容:
1、数据的收集:从多种不同来源获取数据,包括结构化数据、半结构化数据和非结构化数据等。
2、数据的清洗和预处理:垃圾进,垃圾出(GIGO)。只有标准、规范的数据才有可能发挥价值,指导决策。所以,在进行数据处理、分析之前,需要对数据进行清洗和预处理,包括:处理缺失值、处理重复数据、清除错误数据等。
3、数据分析:使用统计分析、机器学习算法、深度学习算法等,对数据进行分析,以揭示趋势、模式和关系。
4、数据可视化:一图胜千言。使用图形和图表来表示分析结果,使复杂的数据更易于理解和解释。
5、模型建立和评估:构建预测、分类等各种模型并评估其性能,确保模型的准确性和有效性。
6、商业洞察与决策支持:基于分析结果向决策者提供可行的建议,帮助其制定战略和战术决策。
Python常用的数据科学库
Python本不是专门用于进行数据科学的编程语言,但是,随着越来越多的强大的数据科学相关的库,使得Python变成最适合进行数据科学实现的编程语言。学习数据科学,除了相关概念、原理、算法的学习,在实践应用中,更多的是对这些类库的学习、使用,从而达到熟能生巧的效果。
常用的Python数据科学库如下:
1、NumPy
提供高效的多维数组(ndarray)对象和用于执行数组操作的函数。可以进行数值计算和线性代数操作;可以灵活进行数组的切片、索引和变形;广播功能,支持不同形状的数组进行运算。
NumPy是高效数据科学的基石,Pandas、TensorFlow、PyTorch等库中,都能看到NumPy的身影。
2、Pandas
用于数据处理和分析,尤其是表格数据的处理分析的库。可以进行数据的清洗和预处理;支持多种数据格式(CSV、Excel、SQL等)的读取和写入;进行表格数据的选择、过滤、聚合和分组操作。
3、Matplotlib、Seaborn、Plotly、Bokeh、Pyecharts
用于进行数据的可视化。通常支持多种静态、动态和交互式图表;支持自定义复杂的表格样式和格式。
4、SciPy
用于进行科学计算的库。提供优化、积分、插值、特征值问题、信号处理等工具。与NumPy紧密结合,扩展了NumPy的功能。
5、Scikit-learn
用于进行机器学习的库。提供各种分类、回归、聚类、降维和模型选择的算法。可以支持模型评估和调参,适合构建和评估机器学习模型。提供方便的数据预处理和特征工程工具。
6、Statsmodels
用于统计建模和计量经济分析的库。提供线性模型、时间序列分析、假设检验等统计工具。适合进行复杂的统计分析和建模。
7、NTLK、SpaCy
用于自然语言处理的库。提供文本处理和分析的工具。支持词汇处理、句法分析、文本分类和情感分析等功能。支持词性标注、命名实体识别、依存句法分析等功能。
8、TensorFlow、Keras、PyTorch
用于深度学习和神经网络建模的库。提供构建和训练深度学习模型的工具。支持分布式计算和大规模数据处理。适合用于图像识别、自然语言处理等任务。支持快速原型开发和模型训练。
需要说明的是,Python数据科学系列后续的文章中,将会穿插进行相关概念、原理、算法以及这些常用数据科学库的介绍。
总结
本文简单介绍了数据科学的含义,强调了“跨学科”的特性;介绍了数据科学的主要工作内容;最后介绍了Python中常用的数据科学的库。需要说明的是,应当将数据科学作为一项具有加乘作用的新能力,而非一门新的学科。
以上就是本文的全部内容,感谢您的拨冗阅读!