文章目录
- 一 表设计
- Articles(文章表)
- Comments(评论索引表)
- CommentsContent(评论内容表)
- SQL 创建表的语句
- 触发器
- 二 添加评论
- 三 查询评论
无论我们是阅读公众号文章还是刷短视频,现在都有评论功能,而且这些评论基本上也都是支持“楼中楼”,也就是文章下面有评论,评论下面有回复,回复下面又有回复,回复还可以继续回复…
如果数据量不大的话,这个表其实很好设计,一张表就可以搞定,类似我们常见的省市县表结构:

CREATE TABLE administrative_divisions (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(100) NOT NULL,parent_id INT DEFAULT NULL,level TINYINT NOT NULL,country_code VARCHAR(10),created_at DATETIME DEFAULT CURRENT_TIMESTAMP,updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,INDEX idx_parent_id (parent_id),INDEX idx_level (level)
);
对于这种结构的表,数据量不大的话没问题,数据量大的话,查询性能和维护都会成为问题。
今天我们就来讨论下这种评论表如何设计会好一些,也是松哥最近工作中的一点点经验,欢迎小伙伴们批评指正。
一 表设计
因为现在无论是文章还是短视频,评论数动辄很大,所以系统在显示的时候,往往会先进行评论折叠,只显示一个总数,点击展开的时候,才会显示出来,以微信公众号为例,一般是这样:
首先在文章下方会先展示一个评论总数:
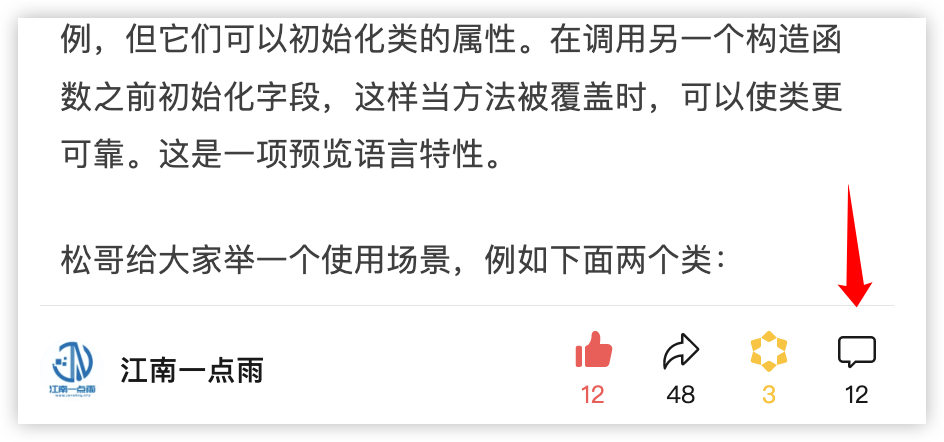
点开评论区之后,这里也有两个值得关注的信息:
- 评论区上方会显示总的评论数
- 回复的评论不会一次性显示出来,但是会显示有多少条回复,需要用户点击之后才可以看到回复内容。
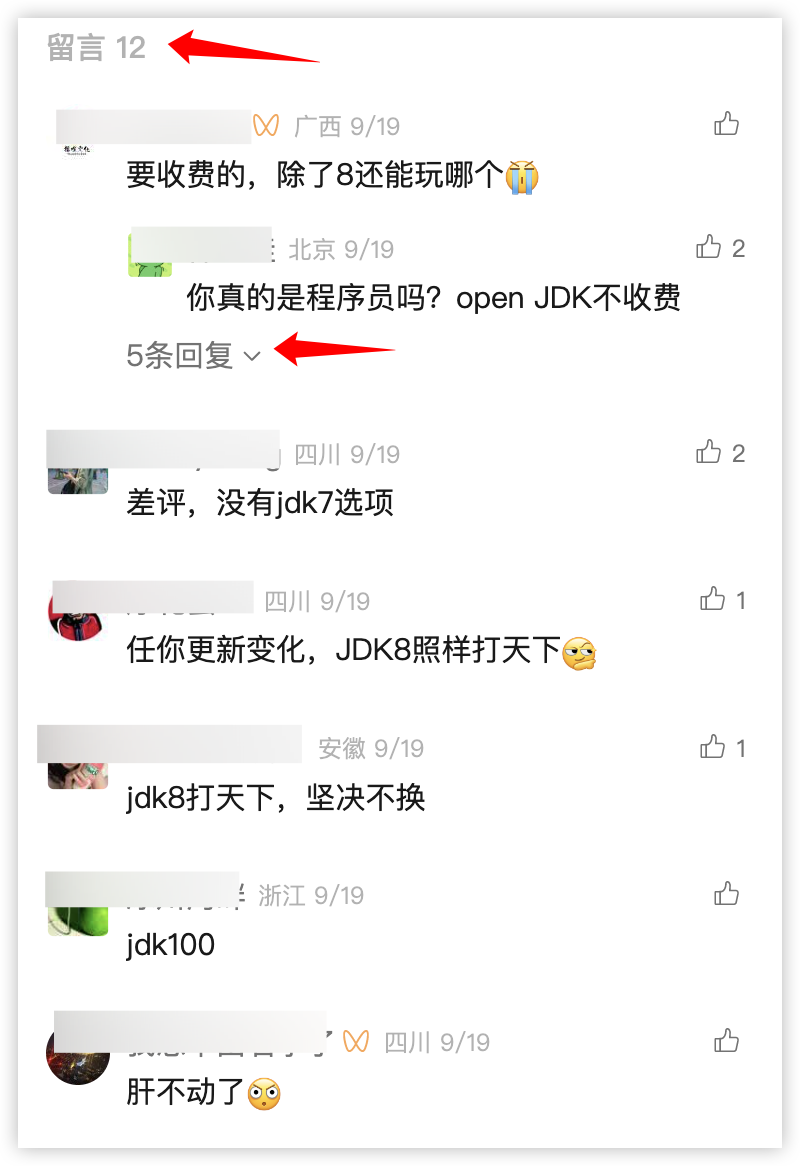
另外需要注意的是,如果回复数量特别多的话,也不会一次性全部展示出来。
首先这样的设计是合理的,这个相信大家应该没什么异议,评论回复之所以不一次性全部展示,一方面是性能考虑,另一方面也是用户体验考虑。有的评论回复特别多,一次性全部展示出来,会影响查看一级评论。
那么我们就看下这样的评论功能,表该如何设计。
为了满足这些要求,我们将设计三个表:Articles(文章表),Comments(评论索引表),和 CommentsContent(评论内容表)。文章表将记录文章的根评论数,评论索引表将记录评论的层级关系、回复数量和点赞数量,评论内容表将存储实际的评论内容。
这种设计方式通过将评论内容和评论索引分开存储,提高了查询性能,同时也便于数据维护,并且通过文章表记录文章的根评论数,方便快速统计。
以下设计主要提供思路,大家不必纠结于表名称。
Articles(文章表)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| article_id | BIGINT AUTO_INCREMENT | 主键,自增 |
| title | VARCHAR(255) | 文章标题 |
| root_comment_count | INT DEFAULT 0 | 文章的根评论数 |
| created_at | DATETIME | 创建时间 |
| updated_at | DATETIME | 更新时间 |
Comments(评论索引表)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| comment_id | BIGINT AUTO_INCREMENT | 主键,自增 |
| article_id | BIGINT | 文章ID |
| parent_id | BIGINT DEFAULT 0 | 父评论ID,用于实现多级评论,顶级评论此字段为0 |
| user_id | BIGINT | 发表评论的用户ID |
| reply_count | INT DEFAULT 0 | 这条评论的回复数量 |
| like_count | INT DEFAULT 0 | 这条评论的点赞数量 |
| created_at | DATETIME | 创建时间 |
| updated_at | DATETIME | 更新时间 |
CommentsContent(评论内容表)
| 字段名 | 数据类型 | 描述 |
|---|---|---|
| comment_id | BIGINT | 外键,关联评论索引表的comment_id |
| comment_text | TEXT | 评论内容 |
| comment_time | DATETIME | 评论时间 |
SQL 创建表的语句
-- 创建文章表
CREATE TABLE articles (article_id BIGINT AUTO_INCREMENT PRIMARY KEY,title VARCHAR(255) NOT NULL,root_comment_count INT DEFAULT 0,created_at DATETIME DEFAULT CURRENT_TIMESTAMP,updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,INDEX idx_root_comment_count (root_comment_count)
);-- 创建评论索引表
CREATE TABLE comments (comment_id BIGINT AUTO_INCREMENT PRIMARY KEY,article_id BIGINT NOT NULL,parent_id BIGINT DEFAULT 0,user_id BIGINT NOT NULL,reply_count INT DEFAULT 0,like_count INT DEFAULT 0,created_at DATETIME DEFAULT CURRENT_TIMESTAMP,updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,INDEX idx_article_id (article_id),INDEX idx_parent_id (parent_id)
);-- 创建评论内容表
CREATE TABLE comments_content (comment_id BIGINT PRIMARY KEY,comment_text TEXT NOT NULL,comment_time DATETIME DEFAULT CURRENT_TIMESTAMP,FOREIGN KEY (comment_id) REFERENCES comments(comment_id)
);
触发器
触发器主要用于更新文章的根评论数和评论的回复数量及点赞数量,不过这个并非必须,这个也可以通过业务逻辑去处理,松哥这里主要是给大家提供一个参考。
DELIMITER //
CREATE TRIGGER after_comment_insert
AFTER INSERT ON comments
FOR EACH ROW
BEGINIF NEW.parent_id = 0 THENUPDATE articles SET root_comment_count = root_comment_count + 1 WHERE article_id = NEW.article_id;END IF;
END; //
DELIMITER ;CREATE TRIGGER after_comment_like_insert
AFTER INSERT ON comments
FOR EACH ROW
BEGINUPDATE comments SET like_count = like_count + 1 WHERE comment_id = NEW.comment_id;
END; //
DELIMITER ;CREATE TRIGGER after_comment_reply_insert
AFTER INSERT ON comments
FOR EACH ROW
BEGINUPDATE comments SET reply_count = reply_count + 1 WHERE comment_id = NEW.parent_id;
END; //
DELIMITER ;CREATE TRIGGER after_comment_delete
BEFORE DELETE ON comments
FOR EACH ROW
BEGINIF OLD.parent_id = 0 THENUPDATE articles SET root_comment_count = root_comment_count - 1 WHERE article_id = OLD.article_id;ELSEUPDATE comments SET reply_count = reply_count - 1 WHERE comment_id = OLD.parent_id;END IF;
END; //
DELIMITER ;
在 Comments 表的 article_id 和 parent_id 字段上创建索引,可以提高查询特定文章的评论及其子评论的性能。
根据上面的设计,当我们想要获取评论总数、回复总数的时候,直接查询就可以了,就不需要统计了,非常方便。
二 添加评论
为了应对高并发,添加评论这块我们可以结合 MQ 去完成。
- 首先前端发送评论到服务端。
- 服务端收到评论消息之后,将之发给 MQ 去处理。
- 消费者从 MQ 上消费消息,向数据添加评论。
- 添加完成后,将添加成功的消息发送给客户端。
以上步骤需要确保 MQ 消息可靠性,具体如何确保可靠性,松哥在之前的文章中和大家聊过了(四种策略确保 RabbitMQ 消息发送可靠性!你用哪种?
),这里就不再赘述。
另外还有一点就是如果需要对评论内容进行分析,那么在第 4 步完成之后,还是通过消费 MQ 消息将评论存入 ES;或者通过 Canal 之类的工具,将表中的数据同步到 ES。
三 查询评论
热门评论可以存入缓存中,避免每次查询数据库,这个松哥之前有过专门的文章,小伙伴们可以参考:
- 点赞收藏功能该如何设计?
虽然当时写的是点赞收藏,但是和这里思路基本一致。
另一方面就是读写分离。
评论数据是非常典型的读多写少场景,因此我们可以从数据库层面进行读写分离,以提升性能。
好啦,目前的思路大致上就是这样,如果有不同看法,欢迎小伙伴们留言讨论。





![[VUE]框架网页开发1 本地开发环境安装](https://i-blog.csdnimg.cn/direct/db8d3ea91d464fc7acbeed1b550d2365.png)