因本文内容较长,故分为上下两部分。上部分可点击以下链接查看
基于MindSpore实现Transformer机器翻译(上)
编码器(Encoder)
Transformer的Encoder负责处理输入的源序列,并将输入信息整合为一系列的上下文向量(context vector)输出。
每个encoder层中存在两个子层:多头自注意力(multi-head self-attention)和基于位置的前馈神经网络(position-wise feed-forward network)。
子层之间使用了残差连接(residual connection),并使用了层规范化(layer normalization)。二者统称为“Add & Norm”

基于位置的前馈神经网络 (Position-Wise Feed-Forward Network)
基于位置的前馈神经网络被用来对输入中的每个位置进行非线性变换。它由两个线性层组成,层与层之间需要经过ReLU激活函数。
F F N ( x ) = R e L U ( x W 1 + b 1 ) W 2 + b 2 \mathrm{FFN}(x) = \mathrm{ReLU}(xW_1 + b_1)W_2 + b_2 FFN(x)=ReLU(xW1+b1)W2+b2
相比固定的ReLU函数,基于位置的前馈神经网络可以处理更加复杂的关系,并且由于前馈网络是基于位置的,可以捕获到不同位置的信息,并为每个位置提供不同的转换。
Add & Norm
Add & Norm层本质上是残差连接后紧接了一个LayerNorm层。
Add&Norm ( x ) = LayerNorm ( x + Sublayer ( x ) ) \text{Add\&Norm}(x) = \text{LayerNorm}(x + \text{Sublayer}(x)) Add&Norm(x)=LayerNorm(x+Sublayer(x))
- Add:残差连接,帮助缓解网络退化问题,注意需要满足 x x x与 SubLayer ( x ) 的形状一致 \text{SubLayer}(x)的形状一致 SubLayer(x)的形状一致;
- Norm:Layer Norm,层归一化,帮助模型更快地进行收敛;
解码器 (Decoder)
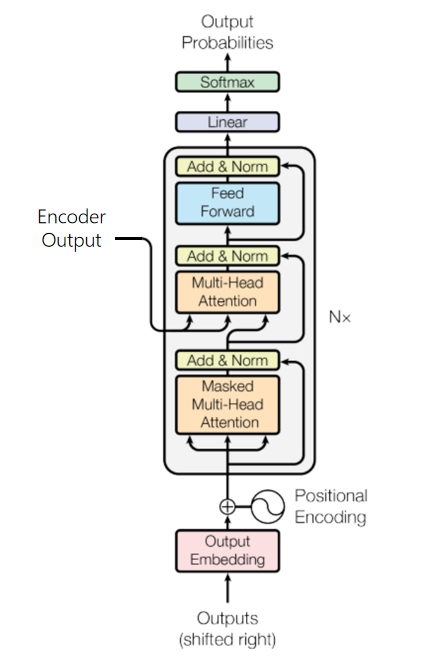
解码器将编码器输出的上下文序列转换为目标序列的预测结果 Y ^ \hat{Y} Y^,该输出将在模型训练中与真实目标输出 Y Y Y进行比较,计算损失。
不同于编码器,每个Decoder层中包含两层多头注意力机制,并在最后多出一个线性层,输出对目标序列的预测结果。
- 第一层:计算目标序列的注意力分数的掩码多头自注意力;
- 第二层:用于计算上下文序列与目标序列对应关系,其中Decoder掩码多头注意力的输出作为query,Encoder的输出(上下文序列)作为key和value;
带掩码的多头注意力
在处理目标序列的输入时,t时刻的模型只能“观察”直到t-1时刻的所有词元,后续的词语不应该一并输入Decoder中。
为了保证在t时刻,只有t-1个词元作为输入参与多头注意力分数的计算,我们需要在第一个多头注意力中额外增加一个时间掩码,使目标序列中的词随时间发展逐个被暴露出来。
该注意力掩码可通过三角矩阵实现,对角线以上的词元表示为不参与注意力计算的词元,标记为1。
0 1 1 1 1 0 0 1 1 1 0 0 0 1 1 0 0 0 0 1 0 0 0 0 0 \begin{matrix} 0 & 1 & 1 & 1 & 1\\ 0 & 0 & 1 & 1 & 1\\ 0 & 0 & 0 & 1 & 1\\ 0 & 0 & 0 & 0 & 1\\ 0 & 0 & 0 & 0 & 0\\ \end{matrix} 0000010000110001110011110
该掩码一般被称作subsequent mask。
最后,将subsequent mask和padding mask合并为一个整体的掩码,确保模型既不会注意到t时刻以后的词元,也不会关注为 <pad> 的词元。

通过Transformer实现文本机器翻译
全流程
- 数据预处理: 将图像、文本等数据处理为可以计算的Tensor
- 模型构建: 使用框架API, 搭建模型
- 模型训练: 定义模型训练逻辑, 遍历训练集进行训练
- 模型评估: 使用训练好的模型, 在测试集评估效果
- 模型推理: 将训练好的模型部署, 输入新数据获得预测结果
数据准备
我们本次使用的数据集为Multi30K数据集,它是一个大规模的图像-文本数据集,包含30K+图片,每张图片对应两类不同的文本描述:
- 英语描述,及对应的德语翻译;
- 五个独立的、非翻译而来的英语和德语描述,描述中包含的细节并不相同;
因其收集的不同语言对于图片的描述相互独立,所以训练出的模型可以更好地适用于有噪声的多模态内容。

图片来源:Elliott, D., Frank, S., Sima’an, K., & Specia, L. (2016). Multi30K: Multilingual English-German Image Descriptions. CoRR, 1605.00459.
在本次文本翻译任务中,德语是源语言(source languag),英语是目标语言(target language)。
数据预处理
在使用数据进行模型训练等操作时,我们需要对数据进行预处理,流程如下:
- 加载数据集;
- 构建词典;
- 创建数据迭代器;
数据加载器
加载数据集,并进行分词,即将句子拆解为单独的词元(token,可以为字符或者单词)。一般在机器翻译类任务中,我们习惯进行单词级词元化,即每个词元要么为一个单词,要么为一个标点符号。同一个单词,不论首字母是否大写,都应该对应同一个词元,故在分词前,我们需统一将单词转换为小写。
“Hello world!” --> [“hello”, “world”, “!”]
接下来,我们创建数据加载器Multi30K。后期调用该类进行遍历时,每次返回当前源语言(德语)与目标语言(英语)文本描述的词元列表。
词典
将每个词元映射到从0开始的数字索引中(为节约存储空间,可过滤掉词频低的词元),词元和数字索引所构成的集合叫做词典(vocabulary)。
以上述“Hello world!”为例,该序列组成的词典为:
{“<unk>”: 0, “<pad>”: 1, “<bos>”: 2, “<eos>”: 3, “hello”: 4, “world”: 5, “!”: 6}
在构建词典中,我们使用了4个特殊词元。
- <unk>:未知词元(unknown),将出现次数少于一定频率的单词统一判定为未知词元;
- <bos>:起始词元(begin of sentence),用来标注一个句子的开始;
- <eos>:结束词元(end of sentence),用来标注一个句子的结束;
- <pad>:填充词元(padding),当句子长度不够时将句子填充至统一长度;
通过Vocab创建词典后,我们可以实现词元与数字索引之间的互相转换。我们可以通过调用enocde函数,返回输入词元或者词元序列对应的数字索引或数字索引序列,反之亦然,我们同样可以通过调用decode函数,返回输入数字索引或数字索引序列对应的词元或词元序列。
使用collections中的Counter和OrderedDict统计英/德语每个单词在整体文本中出现的频率。构建词频字典,然后再将词频字典转为词典。其中,收录所有源语言(德语)词元的词典为de_vocab,收录所有目标语言(英语)词元的词典为en_vocab。
在分配数字索引时有一个小技巧:常用的词元对应数值较小的索引,这样可以节约空间。
数据迭代器
数据预处理的最后一步是创建数据迭代器。截至目前,我们已经通过数据加载器Multi30K将源语言(德语)与目标语言(英语)的文本描述转换为词元序列,并构建了词元与数字索引一一对应的词典,接下来,需要将词元序列转换为数字索引序列。
还是以“Hello world!”为例,我们逐步演示数据迭代器中的操作
- 我们将表示开始和结束的特殊词元 <bos> 和 <eos> 分别添加在每个词元序列的句首和句尾。
[“hello”, “world”, “!”] --> [“<bos>”, “hello”, “world”, “!”, “<eos>”]
- 统一序列长度(超出长度的进行截断,未达到长度的通过填充 <pad> 进行补齐),同时记录序列的有效长度。此处假定统一的长度为7。
[“<bos>”, “hello”, “world”, “!”, “<eos>”] --> [“”, “hello”, “world”, “!”, “<eos>”, “<pad>”, “<pad>”], valid length = 5
- 最后,对文本序列进行批处理。对于每个batch中的序列,通过调用词典中的
encode为序列中的所有词元找到其对应的数字索引,将结果以Tensor的形式返回。
[“<bos>”, “hello”, “world”, “!”, “<eos>”, “<pad>”, “<pad>”] --> [2, 4, 5, 6, 3, 1, 1] --> tensor
模型训练 & 模型评估
定义损失函数与优化器。
- 损失函数:定义如何计算模型输出(logits)与目标(targets)之间的误差,这里可以使用交叉熵损失(CrossEntropyLoss)
- 优化器:MindSpore将模型优化算法的实现称为优化器。优化器内部定义了模型的参数优化过程(即梯度如何更新至模型参数),所有优化逻辑都封装在优化器对象中。
模型训练逻辑
MindSpore在模型训练部分使用了函数式编程(FP)。
构造函数 → 函数变换 → 函数调用 \text{构造函数}\rightarrow \text{函数变换} \rightarrow \text{函数调用} 构造函数→函数变换→函数调用
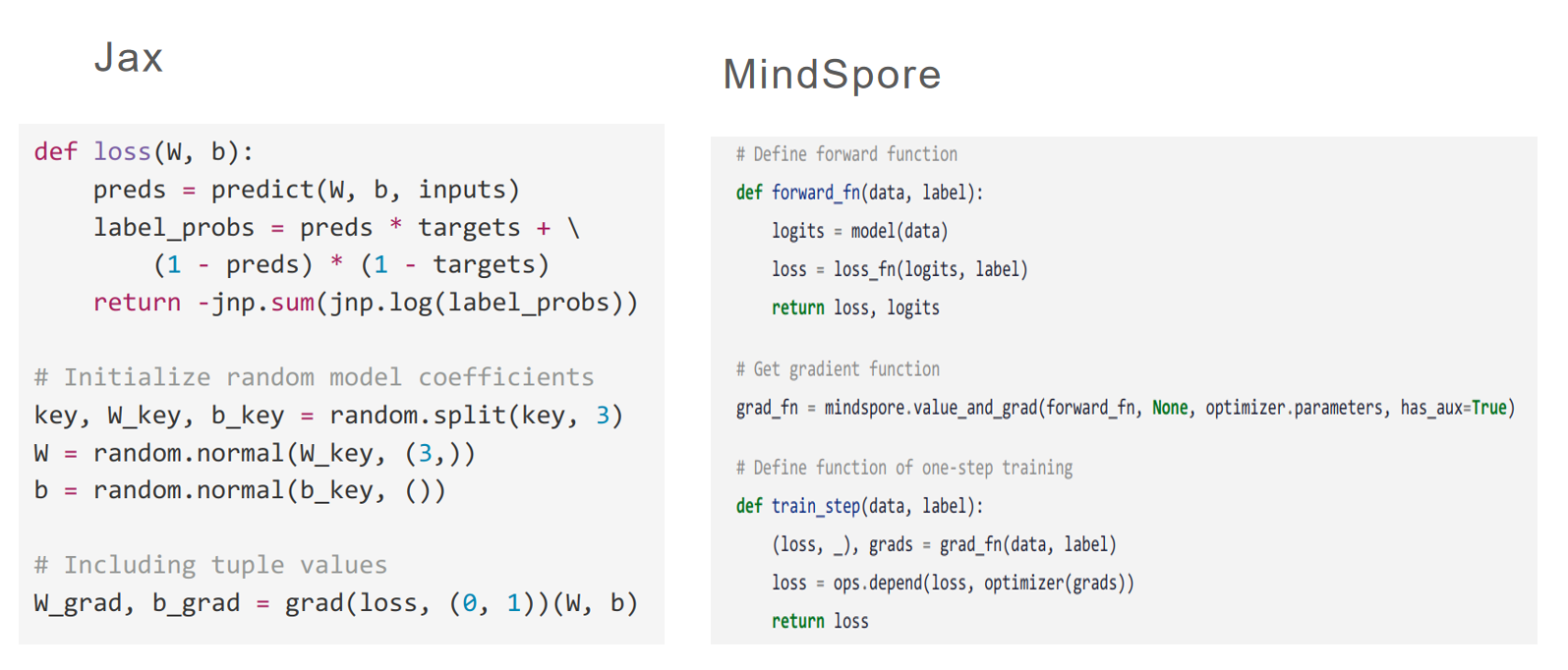
- Network+loss function直接构造正向函数
- 函数变换,获得梯度计算(反向传播)函数
- 构造训练过程函数
- 调用函数进行训练
定义前向网络计算逻辑。
在训练过程中,表示句子结尾的 <eos> 占位符应是被模型预测出来,而不是作为模型的输入,所以在处理 Decoder 的输入时,我们需要移除目标序列最末的 <eos> 占位符。
trg = [, x_1, x_2, …, x_n, ]
trg[:-1] = [, x_1, x_2, …, x_n]
其中, x i x_i xi代表目标序列中第i个表示实际内容的词元。
我们期望最终的输出包含表示句末的 <eos> ,不包含表示句首的 <bos>,所以在计算损失时,需要同样去除的目标序列的句首 <bos> 占位符,再进行比较。
output = [y_1, y_2, …, y_n, <eos>]
trg[1:] = [x_1, x_2, …, x_n, <bos>]
其中, y i y_i yi表示预测的第i个实际内容词元。
定义梯度计算函数。
为了优化模型参数,需要求参数对loss的导数。我们调用mindspore.ops.value_and_grad函数,来获得function的微分函数。
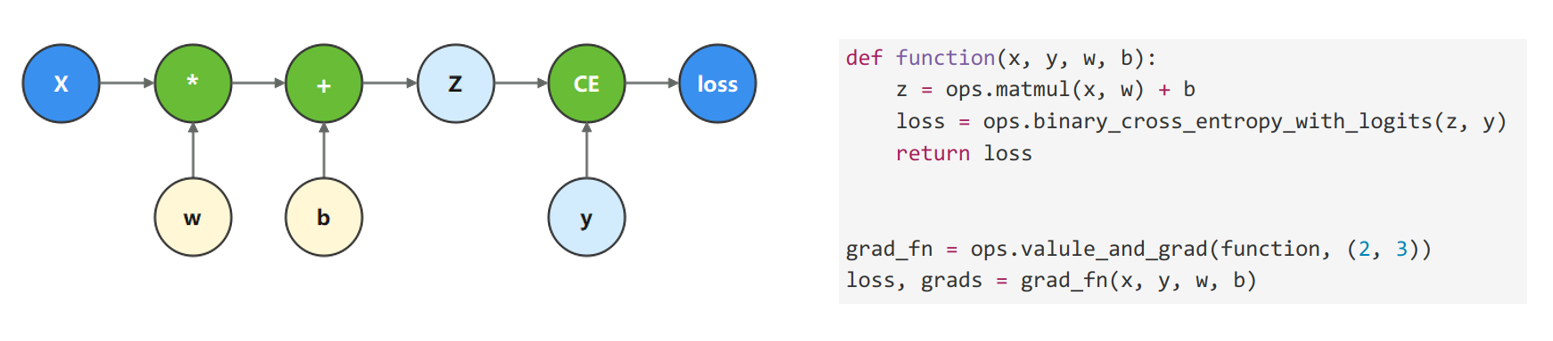
常用到的参数有三种:
- fn:待求导的函数;
- grad_position:指定求导输入位置的索引;
- weights:指定求导的参数;
由于使用Cell封装神经网络模型,模型参数为Cell的内部属性,此时我们不需要使用grad_position指定对函数输入求导,因此将其配置为None。对模型参数求导时,我们使用weights参数,使用model.trainable_params()方法从Cell中取出可以求导的参数。
定义整体训练逻辑。
在训练中,模型会以最小化损失为目标更新模型权重,故模型状态需设置为训练model.set_train(True)。
定义模型评估逻辑。
在评估中,仅需正向计算loss,无需更新模型参数,故模型状态需设置为训练model.set_train(False)。
模型训练
数据集遍历迭代,一次完整的数据集遍历成为一个epoch。我们逐个epoch打印训练的损失值和评估精度,并通过save_checkpoint保存评估精度最高的ckpt文件(transformer.ckpt)到home_path/.mindspore_examples/transformer.ckpt。
模型推理
首先,通过load_checkpoint与load_param_into_net将训练好的模型参数加载入新实例化的模型中。
推理过程中无需对模型参数进行更新,所以这里model.set_train(False)。
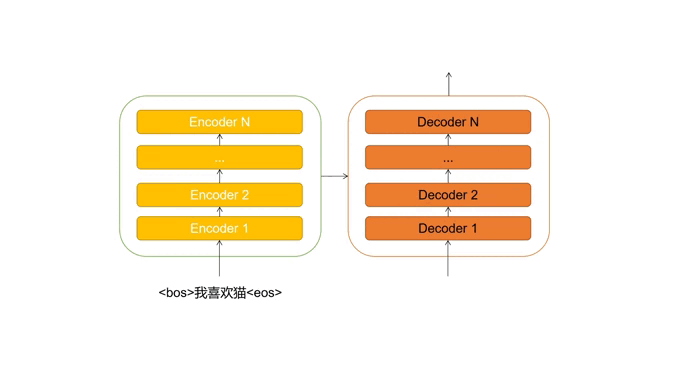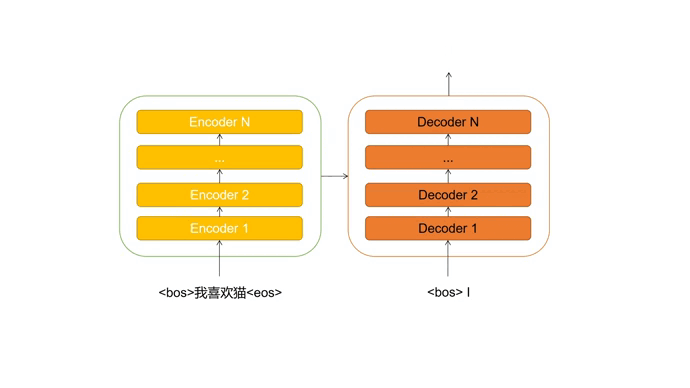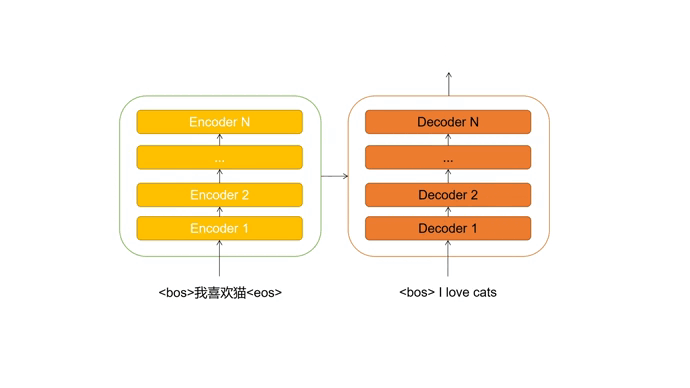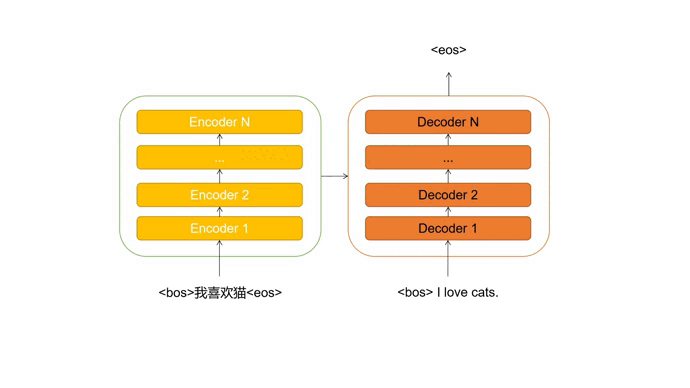
我们输入一个德文语句,期望可以返回翻译好的英文语句。
首先通过Encoder提取德文序列中的特征信息,并将其传输至Decoder。
Decoder最开始的输入为起始占位符 <bos>,每次会根据输入预测下一个出现的单词,并对输入进行更新,直到预测出终止占位符 <eos> 。
BLEU得分
双语替换评测得分(bilingual evaluation understudy,BLEU)为衡量文本翻译模型生成出来的语句好坏的一种算法,它的核心在于评估机器翻译的译文 pred \text{pred} pred 与人工翻译的参考译文 label \text{label} label 的相似度。通过对机器译文的片段与参考译文进行比较,计算出各个片段的的分数,并配以权重进行加和,基本规则为:
- 惩罚过短的预测,即如果机器翻译出来的译文相对于人工翻译的参考译文过于短小,则命中率越高,需要施加更多的惩罚;
- 对长段落匹配更高的权重,即如果出现长段落的完全命中,说明机器翻译的译文更贴近人工翻译的参考译文;
BLEU的公式如下:
e x p ( m i n ( 0 , 1 − l e n ( label ) l e n ( pred ) ) Π n = 1 k p n 1 / 2 n ) exp(min(0, 1-\frac{len(\text{label})}{len(\text{pred})})\Pi^k_{n=1}p_n^{1/2^n}) exp(min(0,1−len(pred)len(label))Πn=1kpn1/2n)
len(label):人工翻译的译文长度len(pred):机器翻译的译文长度p_n:n-gram的精度
我们可以调用nltk中的corpus_bleu函数来计算BLEU,在此之前,需要手动下载nltk。
pip install nltk
from nltk.translate.bleu_score import corpus_bleudef calculate_bleu(dataset, max_len=50):trgs = []pred_trgs = []for data in dataset[:10]:src = data[0]trg = data[1]pred_trg = inference(src, max_len)pred_trgs.append(pred_trg)trgs.append([trg])return corpus_bleu(trgs, pred_trgs)bleu_score = calculate_bleu(test_dataset)print(f'BLEU score = {bleu_score*100:.2f}')
![World of Warcraft [CLASSIC] International translation bug](https://i-blog.csdnimg.cn/direct/a04cea3d10f040db9bb155618147dca0.jpeg)






