最近看到了一篇挺有意思的论文,叫《指令掩蔽下的指令调整》(Instruction Tuning With Loss Over Instructions,https://arxiv.org/abs/2405.14394) 。
这篇论文里,研究者们对一个在指令微调中大家普遍接受的做法提出了疑问,那就是在算损失的时候把指令给遮起来(Instruction Masking During Instruction Finetuning)。不过咱们先别急着聊这个,先来聊聊指令微调是啥。
指令微调(Instruction Tuning,简称IT),它的工作就是让那些已经预训练好的大型语言模型,比如LLM,能更好地理解并执行我们给的指令,比如说“总结一下这篇文章”或者“翻译这句话”啥的。这样做可以帮助缩小模型预测下一个词的目标和我们让它按指令来的目标之间的差距。指令微调其实可以看作是监督式微调(Supervised Fine-Tuning,SFT)的一种特殊情况,不过它们的目标还是有些不同的。
监督式微调,就是拿些标记好的数据来继续训练预训练的模型,让模型能更好地完成特定的任务。而指令微调呢,就是让大型语言模型在包含“指令-输出”对的数据集上再训练一下,这样能提升模型的能力和可控性。指令微调的特别之处在于它的数据集结构,是由人类指令和期望输出组成的一对对的。这种结构让指令微调专注于让模型理解和遵循人类的指令。
总的来说,指令微调是监督式微调的一种特别形式,它专注于通过理解和遵循人类指令来提升大型语言模型的能力和可控性。虽然它们的目标和方法挺像的,但指令微调的特殊数据结构和任务焦点让它成了SFT的一个独特的小分支。

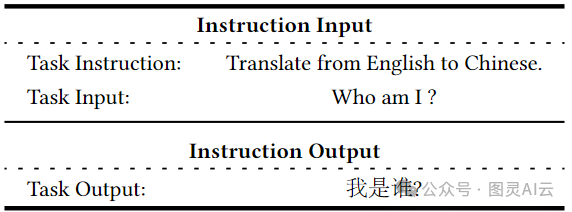
指令微调的数据集示例
在对LLM进行指令微调时,我们通常在计算损失时会掩蔽掉指令本身。
在其他流行的LLM库如Axolotl中,这也是通过config.yaml中的train_on_inputs: false默认设置自动完成的。在Hugging Face中,这不是默认做的,但可以通过DataCollatorForCompletionOnlyLM数据集收集器来实现,详见他们的文档。

输入掩蔽的图,其中突出显示的文本仍然提供给LLM,但在训练期间计算损失时不使用。
就像刚才聊的,把输入提示遮起来这事儿在调教大型语言模型时挺常见的。有些论文里头,研究者们会试试看遮不遮提示,哪个效果更好。比如说,QLoRA这篇论文( "QLoRA: Efficient Finetuning of Quantized LLMs",https://arxiv.org/abs/2305.14314)里头,他们就比了比,发现遮起来效果还挺不错的。
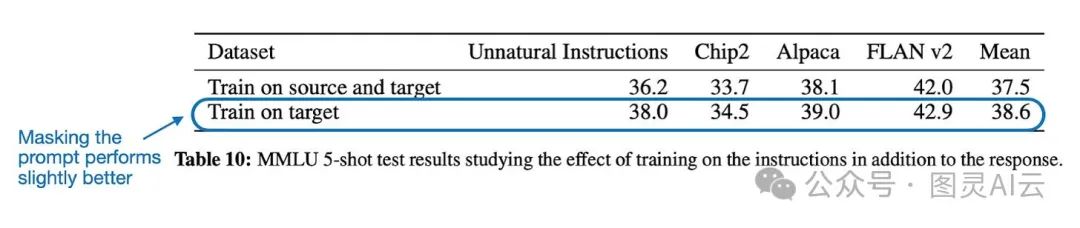
但是得注意,MMLU这个测试主要是看看模型做多选题怎么样,它没去测如果把微调后的模型拿来当聊天机器人用,这对话能力会受啥影响。
在这篇论文里,研究者们就特别认真地研究了,遮不遮指令,对模型性能有啥不一样的影响。

(1)无指令掩蔽,(2)指令掩蔽,和(3)样板文字掩蔽。
上图里头,方法1是咱们用大型语言模型时的常规操作,因为它用起来简单,不需要咱们额外费心去改损失函数啥的。论文里的作者管这招叫“指令建模”。而且哦,他们在论文里还提到,除了指令,那些可能会出现在非Alpaca提示模板里的,像是<|user|>、<|assistant|>和<|system|>这样的特殊提示标记,也都会被遮起来。
方法2是目前大家用得最多的,算损失的时候,除了模型的回应,其他啥都被遮起来。论文里的作者把这招叫做“指令调整”,不过这个名字起得有点尴尬,因为我们实际上不是在调整指令,而是在算损失的时候把指令排除在外,跟方法1比起来。
画上图的时候,我突然想到一个论文里没提到的第三种方法:把那些每回都出现的样板文字给遮起来。比如Alpaca风格的提示,每个例子开头都是“Below is an instruction...”。这些文字和真正的指令、输入比起来,其实是固定的,所以可以考虑在算损失的时候不包括它们。
研究结果发现,这种不把指令遮起来的“指令建模”方法,好像效果还挺好的,比那些遮起来的方法要强一点儿,具体的数据图如下所示。
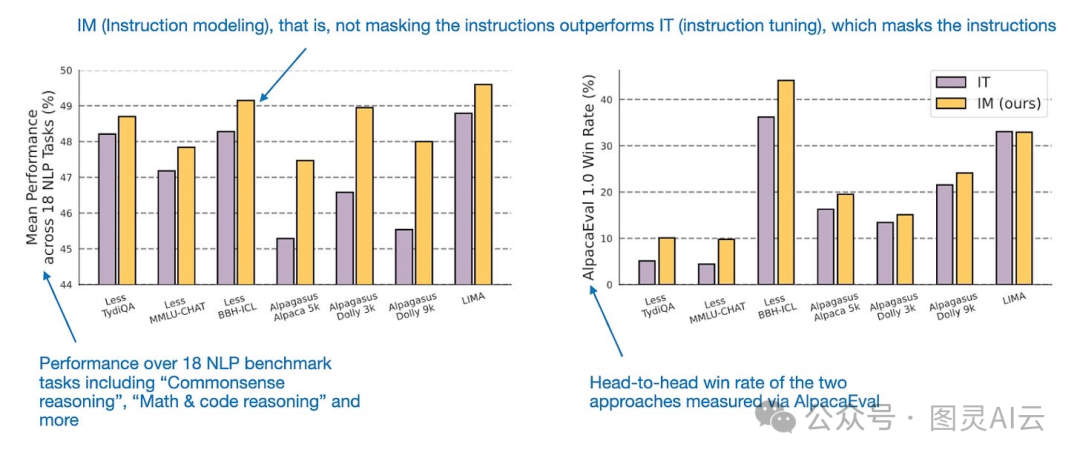
不掩蔽指令比掩蔽指令表现更好。注释来自《指令掩蔽下的指令调整》,( https://arxiv.org/abs/2405.14394)
然而,“指令建模”的性能取决于(a)指令和响应长度的比例和(b)数据集的大小(就训练示例的数量而言)。
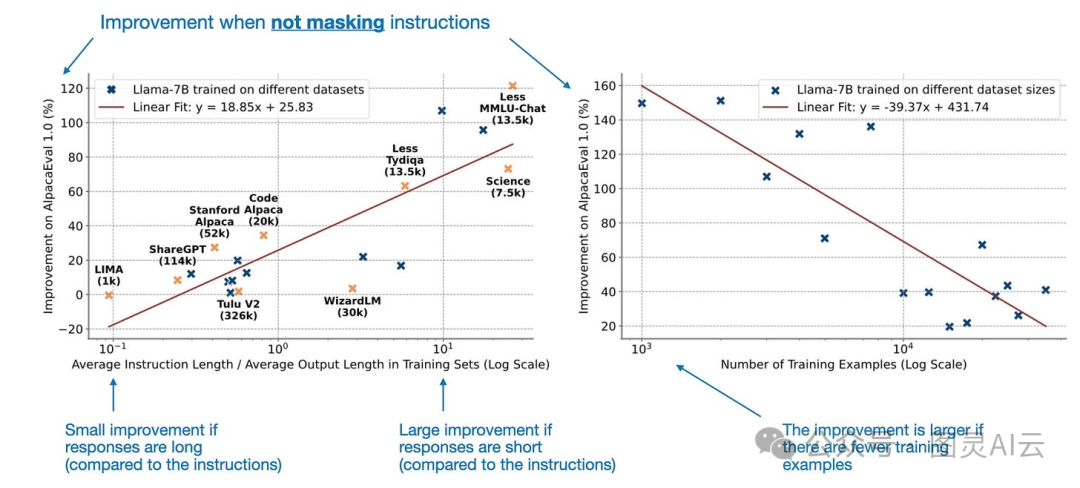
不掩蔽指令的好处取决于数据集的长度和大小。注释来自《指令掩蔽下的指令调整》,(https://arxiv.org/abs/2405.14394)
为啥“指令建模”的效果和数据集的大小、长度有关系呢?原因可能是这样的:如果模型要回应的内容很短,而且训练时用的例子又不多,那模型就很容易把那些回应给记住了。这时候,如果我们在计算损失的时候,把指令这些信息也考虑进去,也就是说让模型输出的内容更多地反映在损失计算里,就能帮到模型,让它不那么容易出现过拟合的情况。
简单来说,研究者们发现,有时候回到最基本的方法,也就是不把指令遮起来,反而能提升模型的表现。
而且,有意思的是,简单的不掩蔽指令的方法(当然,除了那些特殊的提示标记,像<|user|>、<|assistant|>和<|system|>这些还是得遮的),效果竟然更好。
我自己以前也试过这两种方法,当时没觉得哪个明显更好,所以就没在掩蔽这块儿多下功夫,而是去调整别的设置了。现在想想,可能当时应该多试试不同的掩蔽方法,因为现在看来,这个方法好不好用,可能还真的和数据集的大小、长度有关系。






