1. 连接简介
1.1 连接的本质
连接就是把各个表中的记录都取出来进行一次匹配,并把匹配后的组合发送给客户端。如果连接查询中的结果集中包含一个表中的每一条记录与另一个表中的每一条记录相互匹配的组合,那么这样的结果集就可以称为笛卡尔积。
1.2 连接过程简介
t1、t2表数据
SELECT * FROM `t1`;
+----+----+
| m1 | n1 |
+----+----+
| 1 | a |
| 2 | b |
| 3 | c |
+----+----+
SELECT * FROM `t2`;
+----+----+
| m1 | n1 |
+----+----+
| 1 | a |
| 2 | b |
| 3 | c |
+----+----+
连接过程:
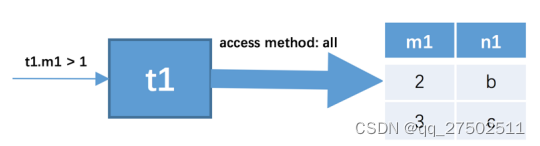
SELECT * FROM t1, t2 WHERE t1.m1 < 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
这个查询中,有3个过滤条件:
- t1.m1 >1;
- t1.m1 = t2.m2;
- t2.n2 < ‘d’
步骤1:假设使用t1作为驱动表,那么就需要到t1表中查找满足t1.m1 >1的记录。
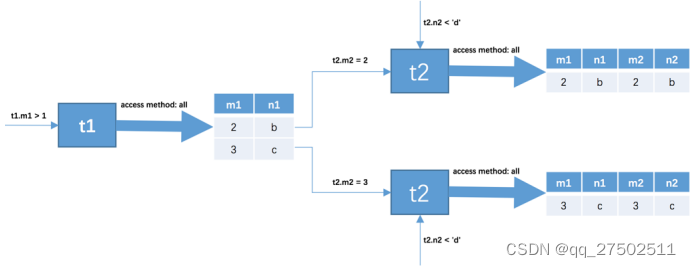
步骤2:步骤1中从驱动表每获取到一条记录,都需要到t2表中查找匹配的记录。
1.3 内连接和外连接
- 对于内连接和两个表,若驱动表中的记录在被驱动表中找不到匹配的记录,则该记录不会加入到最后的结果集。
- 对于外连接的两个表,即使驱动表中的记录在被驱动表中没有匹配的记录,也仍然需要加入到结果集。
- 左外连接:选取左侧的表为驱动表
- 右外连接:选取右侧的表为驱动表
- WHERE 子句中的过滤条件
不论是内连接还是外连接,凡是不符合WHERE子句中过滤条件的记录被不会被加入到最后的结果集。 - ON 子句中的过滤条件
如果无法在被驱动表中找到匹配ON子句中过滤条件的记录,那么改驱动表记录仍然会加入到结果集种。
- 左连接的语法
select * from t1 left join t2 on 连接条件 [where 普通过滤条件] - 右连接的语法
select * from t1 right join t2 on 连接条件 [where 普通过滤条件] - 内连接的语法
select * from t1 [INNER | CROSS] t2 on 连接条件 [where 普通过滤条件] SELECT * FROM t1 JOIN t2; SELECT * FROM t1 INNER JOIN t2; SELECT * FROM t1 CROSS JOIN t2;
2.连接的原理
2.1 嵌套循环连接
两个表进行内查询的大致过程:
- 选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的单表访问方法来执行对驱动表的单表查询。
- 对1中查询驱动表得到的结果集中的每一条记录,都分别到被驱动表中查找匹配的记录。
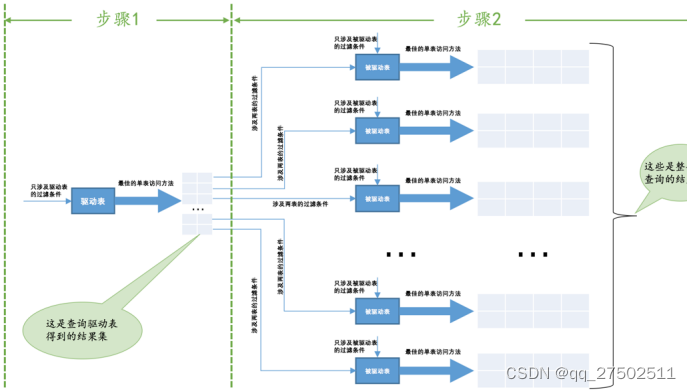
“驱动表只访问一次,单被驱动表却可能访问多次,且访问次数取决对驱动表执行单表查询后的结果集中有多少条记录”的连接执行方式称为嵌套循环连接(Nested-Loop Join)。
for each row in t1 satisfying conditions about t1{for each row in t2 satisfying conditions about t2{for each row in t3 satisfying conditions about t3{send to client;}}
}
2.2 使用索引加快连接速度
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 < 'd';
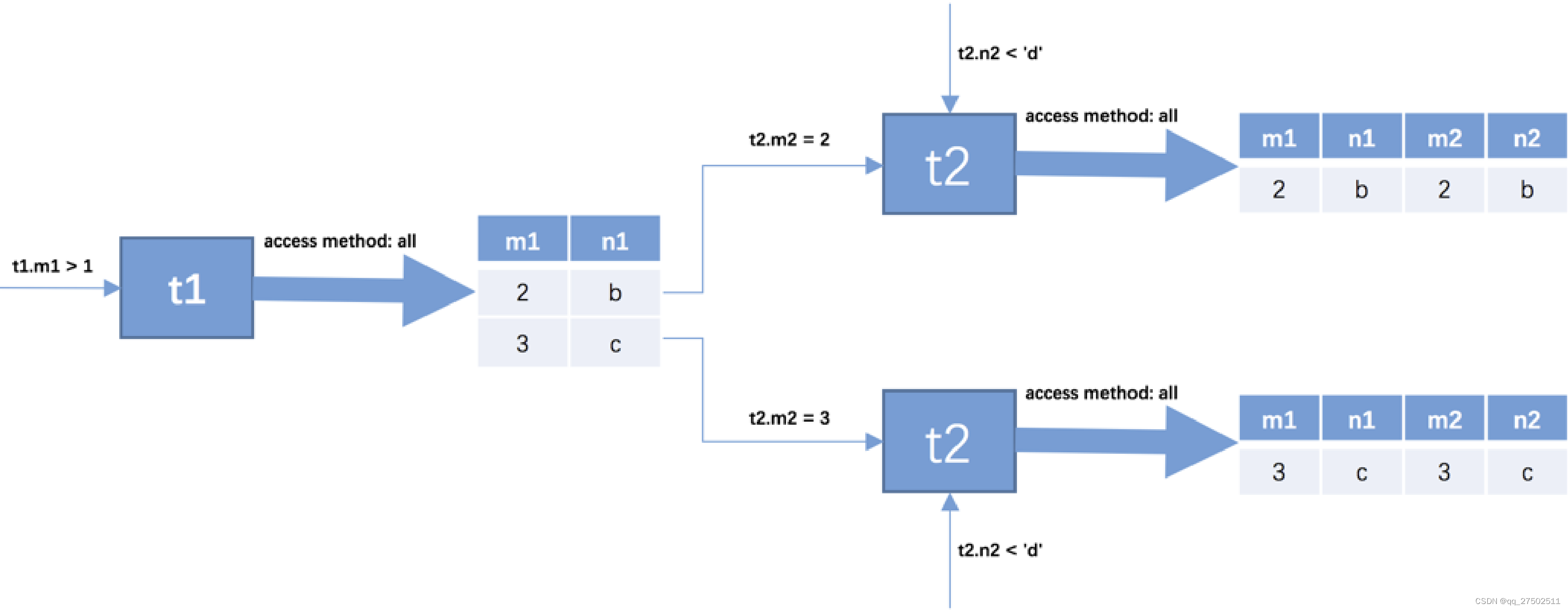
可以看到,原来的t1.m1 = t2.m2这个涉及两个表的过滤条件在针对t2表做查询时关于t1表的条件就已经确定了,所以我们只需要单单优化对t2表的查询了,上述两个对t2表的查询语句中利⽤到的列是m2和n2列,我们可以:
- 在m2列上建⽴索引,因为对m2列的条件是等值查找,⽐如t2.m2 = 2、t2.m2 = 3等,所以可能使⽤到ref的访问⽅法,假设使⽤ref的访问⽅法去执⾏对t2表的查询的话,需要回表之后再判断t2.n2 < d这个条件是否成⽴。
这⾥有⼀个⽐较特殊的情况,就是假设m2列是t2表的主键或者唯⼀⼆级索引列,那么使⽤t2.m2 = 常数值这样的条件从t2表中查找记录的过程的代价就是常数级别的。我们知道在单表中使⽤主键值或者唯⼀⼆级索引列的值进⾏等值查找的⽅式称之为const,⽽设计MySQL的⼤叔把在连接查询中对被驱动表使⽤主键值或者唯⼀⼆级索引列的值进⾏等值查找的查询执⾏⽅式称之为:eq_ref。 - 在n2列上建⽴索引,涉及到的条件是t2.n2 < ‘d’,可能⽤到range的访问⽅法,假设使⽤range的访问⽅法对t2表的查询的话,需要回表之后再判断在m2
列上的条件是否成⽴。
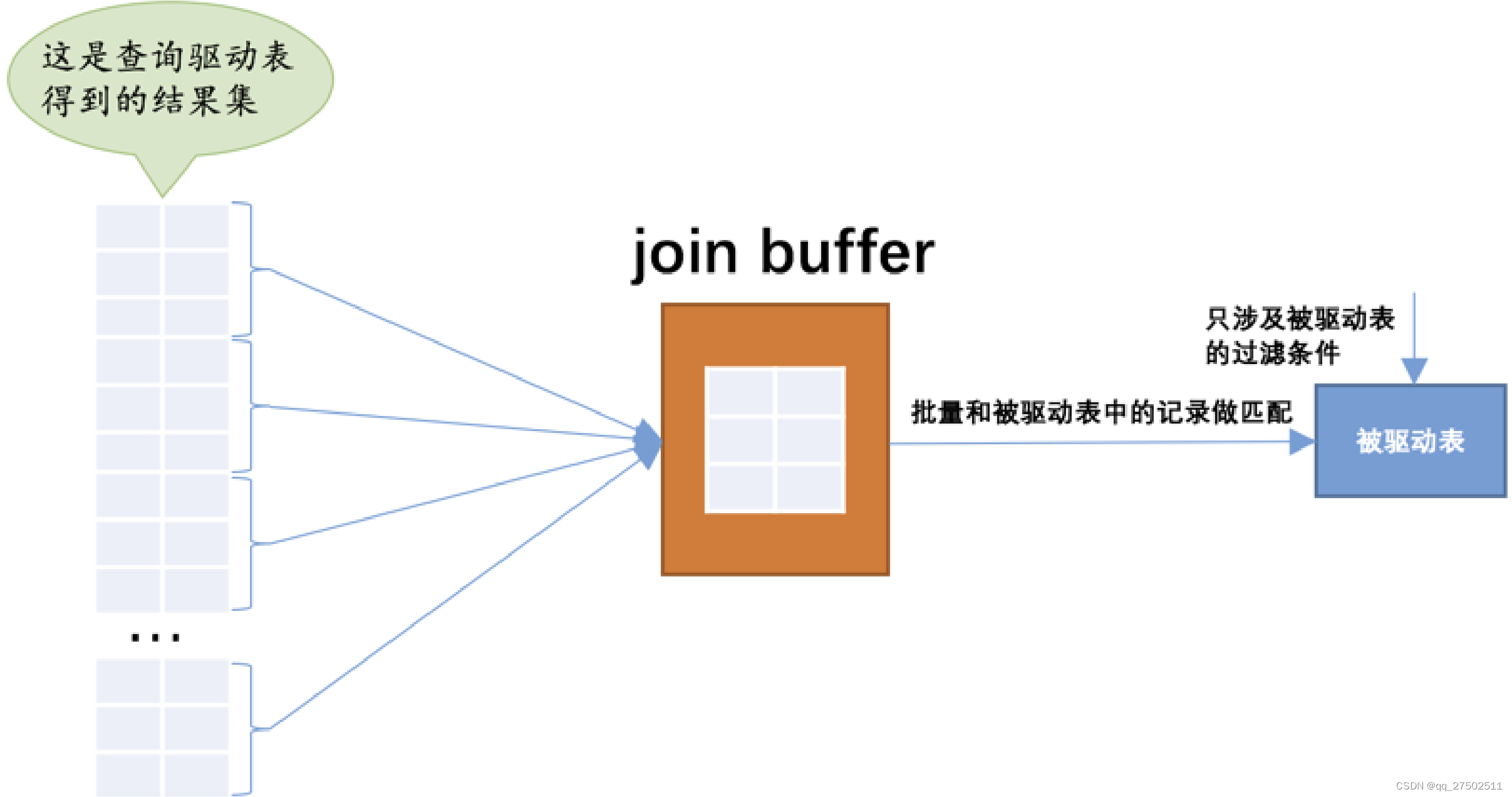
2.3 基于块的嵌套循环连接(Block Nested-Loop Join)
被驱动表中的数据特别多⽽且不能使⽤索引进⾏访问,那就相当于要从磁盘上读好⼏次这个表,这个I/O代价就⾮常⼤了,所以我们得想办法:尽量减少访问被驱动表的次数。
join buffer的概念,join buffer就是执⾏连接查询前申请的⼀块固定⼤⼩的内存,先把若⼲条驱动表结果集中的记录(查询的字段以及需要过滤的字段信息)装在这个join buffer中,然后开始扫描被驱动表,每⼀条被驱动表的记录⼀次性和join buffer中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价。