目录
前言
一、unordered_set
1、简介
2、构造相关函数
3、容量相关函数
4、修改与查找相关接口
5、迭代器
二、unordered_map
1、简介
2、构造相关函数
3、容量相关接口
4、迭代器、查找与修改相关接口
5、方括号接口
三、红黑树系列与哈希系列对比
前言
unordered_map与unordered_set是C++11推出的关联式容器,他们的作用与我们前面学习的map与set差不多一样,唯一不同的是这两个容器相比于map/set数据是无序的;我们从名字也可以看出来,具体上,实际上底层map/set是用的红黑树,而unordered_map/unordered_set是使用哈希来实现的;
一、unordered_set
1、简介
unordered_set也是一种关联式容器,作用主要与我们前面学过的set相同,我们首先看这个类的声明;具体如下;
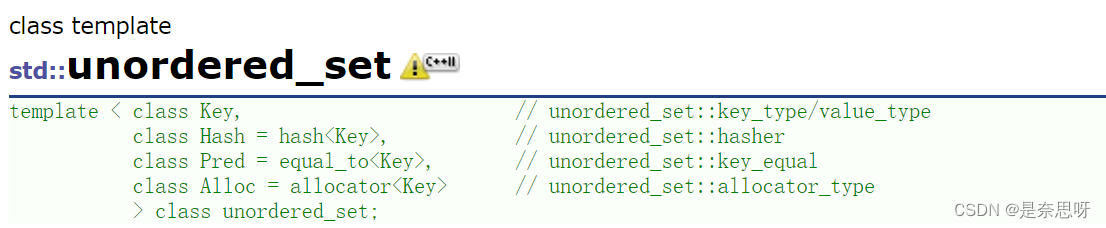
我们可以看到这个类有四个模板参数,其中后三个都有默认的模板参数,参数一是存入Key的数据类型,与我们之前的set相同;第二个参数是哈希函数,这个以及后面的两个都可以不填,哈希函数会在后面一张写实现的时候进行介绍;
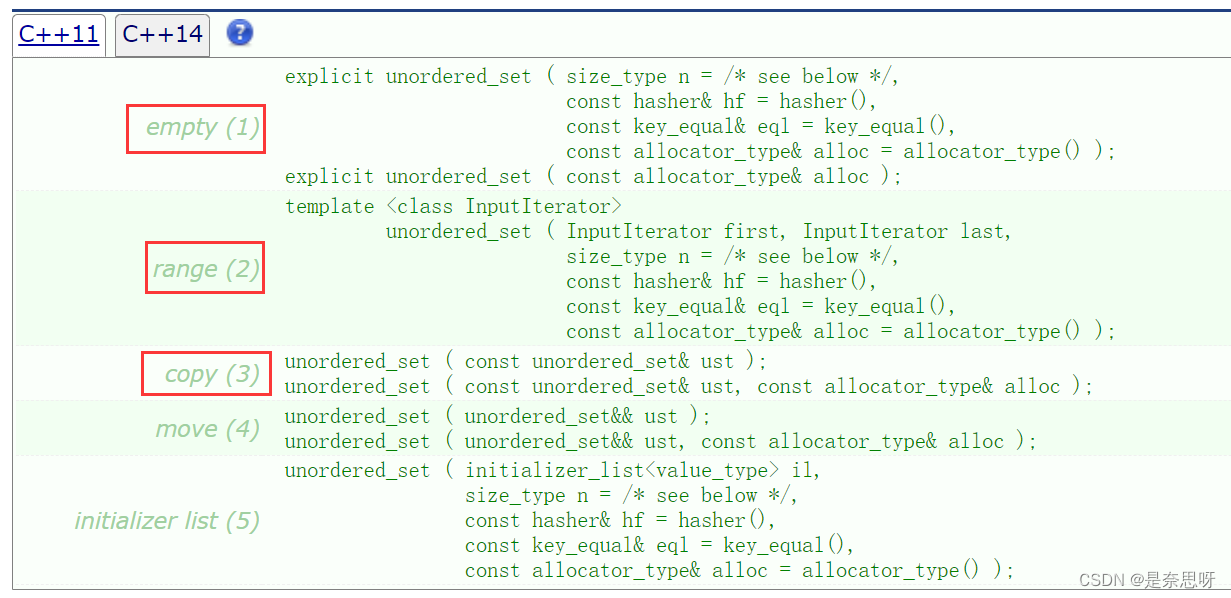
2、构造相关函数
unordered_set的构造相关函数我们用的最多的还是如下几个;分别为无参构造、迭代器区间构造、拷贝构造;当然set也支持赋值重载;

void test_unordered_set1()
{// 无参默认构造unordered_set<int> s1;// 区间构造int arr[] = { 1,2,3,4,5,6 };unordered_set<int> s2(arr, arr + 5);// 拷贝构造unordered_set<int> s3(s2);// 赋值重载s2 = s1;}3、容量相关函数
容量相关函数还是如下三个,这三个我们可以一看就懂了,主要还是第一个与第二个函数,第一个是查看容器是否为空,第二个是容器中储存元素个数;

4、修改与查找相关接口
修改相关接口主要是如下四个为主,其他的需要我们拥有右值引用相关知识,暂可不了解;查找主要以find接口为主来学习;


void test_unordered_set2()
{unordered_set<int> s1;// 插入接口s1.insert(2); // 返回值类型:pair<iterator,bool>s1.insert(5);s1.insert(3);s1.insert(1);s1.insert(7);// 删除接口s1.erase(3); // 返回值类型:size_type// 查找 finds1.find(5); // 返回值是查找值的迭代器,没找到返回end()// 查找个数(在unordered_set中要么返回1要么返回0,因为会去重,unordered_multiset中有意义)cout << s1.count(3) << endl;// 清空s1s1.clear();// 交换unordered_set<int> s2;s1.swap(s2);
}关于insert的返回值是一个pair,该结构的第二个为bool值,记录是否插入成功,第一个记录插入数据迭代器的位置;
5、迭代器
注意,哈希版本的set与map这里都是单向迭代器,因此没有反向迭代器的概念;与set最大的不同是哈希版本是无序的;
void test_unordered_set3()
{unordered_set<int> s1;s1.insert(2); s1.insert(5);s1.insert(3);s1.insert(1);s1.insert(7);// 迭代器unordered_set<int>::iterator it = s1.begin();while (it != s1.end()){cout << *it << " ";it++;}cout << endl;// 范围forfor (auto& e : s1){cout << e << " ";}cout << endl;
}还有一些别的函数方法在我们后面模拟实现以后自然会用了,所以本文暂不介绍;
二、unordered_map
1、简介
同样unordered_map与map最大区别是无序性,其中map底层是红黑树,而unordered_map底层是哈希;其类声明也如下所示;最大的不同是,这里有五个模板参数,多了一个T,因为unordered_map同样也是KeyValue结构;因此多了一个T,也即是Value;

2、构造相关函数
构造相关我们仅仅只需要会使用默认构造,范围构造,拷贝构造即可,因为大部分都是使用这三个构造;赋值我们仅仅需要会使用第一个拷贝赋值即可;其他有关右值引用知识得到后面了解;


void test_unordered_map1()
{// 默认构造unordered_map<int, int> m1;// 区间构造int arr[] = { 1,2,3,4,5,6,7 };unordered_map<int, int> m2;for (auto e : arr){m2.insert(make_pair(e, e));}// 拷贝构造unordered_map<int, int> m3(m2);// 赋值重载m2 = m1;
}3、容量相关接口
容量相关接口非常简单,size是返回容器中元素个数,max_size是返回容器最多能存多少个元素(没啥用),empty是查看容器是否为空;

4、迭代器、查找与修改相关接口
这里跟前面unordered_set差不多,我们就融合到一起讲解了,大体用法也差不多;没什么学习成本;



void test_unordered_map2()
{// 去重unordered_map<int, int> m1;// 插入接口,一般为键值对KV结构m1.insert(make_pair(3, 3)); // 返回值:pair<iterator,bool>m1.insert(make_pair(7, 7));m1.insert(make_pair(1, 1));m1.insert(make_pair(5, 5));m1.insert(make_pair(3, 3));// 查找接口unordered_map<int, int>::iterator it1 = m1.find(5); // 返回5位置的迭代器// 删除接口 返回值为 size_type (删除元素的个数)m1.erase(1); // 删除key为1的键值对// 迭代器遍历unordered_map<int, int>::iterator it2 = m1.find(5);while (it2 != m1.end()){cout << it2->first << ": " << it2->second << endl;it2++;}cout << endl;// 范围for自然也就可以了for (auto& e : m1){cout << e.first << ": " << e.second << endl;}cout << endl;// 交换unordered_map<int, int> m2;m1.swap(m2);// 清空m2.clear();
}5、方括号接口
与map一样,unordered_map也有对方括号进行重载,而且这里的方括号与map一样,功能多样化,可以插入数据,也可以修改键值对的value,还可以查找某个键值对的value;
void test_unordered_map3()
{unordered_map<int, int> m1;m1.insert(make_pair(3, 3));m1.insert(make_pair(7, 7));m1.insert(make_pair(1, 1));m1.insert(make_pair(5, 5));m1.insert(make_pair(3, 3));// 查找cout << m1[3] << endl;// 修改m1[3]++;// 查找cout << m1[3] << endl;}三、红黑树系列与哈希系列对比
我们发现set/map与unordered_set/unordered_map在使用方面似乎没有什么区别,我们的红黑树系列会将数据进行排序;接下来我会从两者之间的速度进行比较;测试代码如下;
// 测试代码
void test2()
{const size_t N = 100000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); // 随机 + 大量重复//v.push_back(rand()+i); // 随机 + 部分重复v.push_back(i); // 有序}size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;size_t begin3 = clock();for (auto e : v){s.find(e);}size_t end3 = clock();cout << "set find:" << end3 - begin3 << endl;size_t begin4 = clock();for (auto e : v){us.find(e);}size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl << endl;cout << "set 插入元素个数" << s.size() << endl;cout << "unordered_set 插入元素个数" << us.size() << endl << endl;size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;
}我们分别对三种类型的数据进行比较;结果如下

我们不难发现,综合来讲,我们的unordered系类的效率明显远远大于红黑树系列,因为我们unordered系列增删查改的综合效率为O(1);而红黑树的增删查改的综合效率为
O(log N);为什么能做到O(1),在我们探究底层原理以后我们就会有大体的认识;