开会时间:2023.05.28 15:30 线下会议
目录
01【fhzny项目】
02【Spark】
03【调研-数仓构建】
3.1【数仓构建,流程图、架构图、使用场景】
场景选择
组件设计
构建流程
04【专利】
05【导师点评】
01【fhzny项目】
- GitLab
- MyBatis-Plus
- Springboot,黑马瑞吉外卖项目视频
- 算法模块和镜像模块代码
- docker
02【Spark】
sparkSql
03【调研-数仓构建】
分享“数仓构建”,流程图、架构图、使用场景,五分钟。
数仓构建(场景(实时、离线)、组件、流程)(第二周)【元数据管理、主数据】
3.1【数仓构建,流程图、架构图、使用场景】
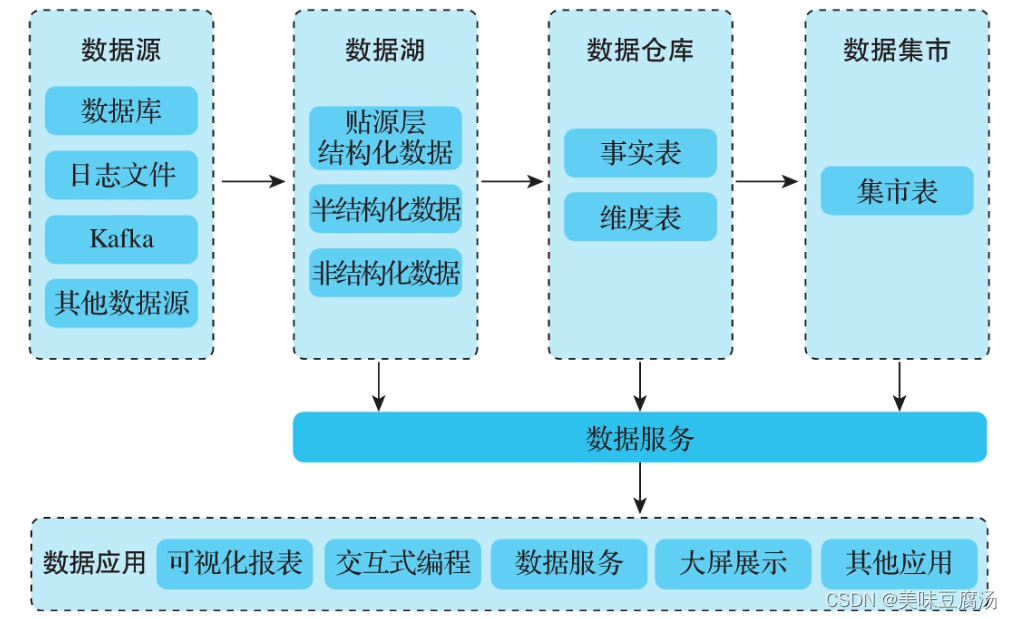
数仓(Data Warehouse)是一个用于集成、管理和分析组织内部和外部数据的存储系统。数仓构建的过程涉及多个方面,包括场景选择(实时和离线)、组件设计和构建流程。下面是一个常见的数仓构建的概述。
场景选择
- 实时场景(Real-time):适用于需要快速获取最新数据并进行实时分析和决策的情况。这种场景通常涉及数据流处理和流式计算,要求低延迟和高吞吐量。
- 离线场景(Offline):适用于对历史数据进行批处理分析和决策支持的情况。这种场景通常使用批处理作业和离线计算,能够处理大规模的数据集。
组件设计
- 数据抽取(Extraction):从各个数据源(例如数据库、日志文件、API)中提取数据,并进行必要的清洗和转换,以满足数据仓库的要求。
- 数据存储(Storage):选择合适的存储技术和架构,例如关系型数据库、列式数据库或者分布式文件系统,用于存储数据仓库中的数据。
- 数据转换和集成(Transformation and Integration):对抽取的数据进行转换和整合,以便进行分析。这包括数据清洗、格式转换、字段映射等操作。
- 数据加载(Loading):将转换和整合后的数据加载到数据仓库中,保证数据的完整性和一致性。可以使用批量加载或者增量加载的方式。
- 数据建模(Modeling):设计和创建数据仓库的逻辑模型,包括维度模型和事实模型。这有助于提供用户友好的数据访问和分析方式。
构建流程
- 需求分析:明确业务需求和数据分析目标,确定需要收集和分析的数据类型和来源。
- 数据源识别和接入:确定需要接入的数据源,并制定相应的数据接入策略和技术方案。
- 数据抽取和清洗:实施数据抽取和清洗的过程,确保数据的准确性和一致性。
- 数据转换和集成:将清洗后的数据进行转换和整合,形成统一的数据模型。
- 数据存储和加载:选择合适的存储技术和加载方式,将整合后的数据加载到数据仓库中。
- 数据建模和优化:设计和创建数据仓库的逻辑模型,对数据进行建模和优化,以满足用户的查询和分析需求。
- 数据访问和分析:提供用户友好的数据
04【专利】
做一个工具实现mysql与es数据的完全一致。
linux,三个节点的es集群。
在mysql中编写包含json类型字段的数据表,将mysql中的数据插入到es中后,mysql中的json数据插入es后效果如下:




05【导师点评】
模型创新点、模型的改造与创新、一个新的应用场景。
- 算法创新点
- 场景创新点
mysql->es
canal记录数据的变化,加入触发器,一旦表变化,写到另外一个表。
canal更改配置文件,很多企业不让更改配置文件。
一种算法型的东西,快速地查找数据条数是否一样。
es—>es
flink-cdc,更改binLog,企业不让改。
es到es的数据备份,快速定位-二分查找,数量核对,
集群数据备份
高考大数据的数据备份与迁移及数据变化。
系统、分析模型、xxx。

![[k8s]Kubernetes简介](https://img-blog.csdnimg.cn/06a83908c3a14c638630043b2178652c.png#pic_center)