开发抽奖时遇到的分布式锁问题,特此记录一下几种实现方案
背景
开发中遇到个抽奖需求,会根据当前奖池内道具数量随机道具并发送给用户。这里面涉及到超发的问题,需要使用到分布式锁,特此记录一下常用的几种方案。
“超发”:在并发情况下,假设某类道具只剩1个,线程A随机到该道具,随机完成但还没来得及减库存,这时线程B也进来了,判断还有库存,继续随机也随机到该道具,这时出现超发。库存只有1个道具,但却随机给用户出了两件道具。也就是发出去的数量大于库存数量。
加分布式锁的方案其实有多种,这里介绍四种:
1、悲观锁
2、乐观锁
3、redis+lua
4、Redisson
1、悲观锁
可以理一下思路,之所以会出现超发,就是因为存在多个线程修改共享数据,如果能在一个线程读库存时就将数据锁定,不允许别的线程进行读写操作,直到库存修改完成才释放锁,那么就不会出现超发问题了。
这种借助数据库锁机制,在修改数据之前先锁定,再修改的方式被称之为悲观锁。
步骤为:
1.开启事务,查询要随机的道具,并对该记录加for update。在查询库存时使用了 for update,这样在事务执行的过程中,就会锁定查询出来的数据,其他事务不能对其进行读写(注意,读也不行),这就避免了数据的不一致,直至事务完成释放锁。
begin; select nums from t_items where item_id = {$item_id} for update;
2、如果还有库存,则减少库存,并提交事务。
update t_items set nums = nums - {$num} where item_id = {$item_id}; commit;
这里存在几个点要注意:
1、select…for
update语句执行中所有扫描过的行都会被锁上,因此在MySQL中用悲观锁务必须确定走了索引,而不是全表扫描,否则将会将整个数据表锁住。
2、使用悲观锁,需要关闭 mysql 的自动提交功能,将 set autocommit = 0 (一般显式开启事务即可无需修改 MySQL配置);
优点:思路清晰,从数据库层面解决超发问题。
缺点:独占锁的方式对于性能影响较大。
因为悲观锁依靠数据库的锁机制实现,以保证操作最大程度的独占性。如果加锁的时间过长,其他用户长时间无法访问,影响了程序的并发访问性,同时这样对数据库性能开销影响也很大,特别是对长事务而言,这样的开销往往无法承受,这时就引出了乐观锁。
2、乐观锁
悲观锁有效但不高效,为了提高性能,出现了乐观锁方案,不使用数据库锁,不阻塞线程并发。
乐观锁,顾名思义,就是对数据的处理持乐观态度,乐观的认为数据一般情况下不会发生冲突,只有提交数据更新时,才会对数据是否冲突进行检测。
思路:乐观锁的实现不依靠数据库提供的锁机制,需要我们自已实现,实现方式一般是记录数据版本,通过版本号的方式。
给表加一个版本号字段version,读取数据时,将版本号一同读出,数据更新时,将版本号加 1。
当我们提交数据更新时,判断当前的版本号与第一次读取出来的版本号是否相等。如果相等,则予以更新,否则认为数据过期,拒绝更新,让用户重新操作。
步骤为:
查询要卖的商品,并获取版本号。
begin; select nums, version from t_items where item_id = {$item_id};
如果库存还有,则减少库存。(更新时判断当前 version 与第 1 步中获取的 version 是否相同)
update t_items set nums = nums - {$num}, version = version + 1 where item_id = {$item_id} and version = {$version};
- 判断更新操作是否成功执行,如果成功,则提交,否则就回滚。
注意:通过 version版本号,就可以知道自己读取的数据在更新时是不是旧的,如果是旧数据,就不能更新了。从而可以知道,在并发量很大的时候,失败的概率会比较高。
为了提升成功率,可以引入重试机制,当更新失败后,再走一遍流程(读取、更新)。可以规定一个次数,例如3次,如果重试了3次还是失败,就放弃;还可以规定一个时间段,比如在
100ms 内循环操作,期间如果某次成功了就退出,否则一直重试到时间到为止。
优点:没有阻塞性,性能优于悲观锁。
缺点:实现思路较复杂,增加version控制,还需要加入重试机制。并且高并发的修改下,失败率较高。
3、redis + lua
错误做法:可能直接会想到redis的setnx+expire命令。如下所示:
public boolean tryLock(String key,String requset,int timeout) {Long result = jedis.setnx(key, requset);// result = 1时,设置成功,否则设置失败if (result == 1L) {return jedis.expire(key, timeout) == 1L;} else {return false;}
}
Redis的SETNX命令,setnx key value,将key设置为value,当键不存在时,才能成功,若键存在,什么也不做,成功返回1,失败返回0 。 因为分布式锁还需要超时机制,所以利用expire命令来设置。
实际上上面的步骤是有问题的,setnx和expire是分开的两步操作,不具有原子性,如果执行完第一条指令应用异常或者重启了,锁将无法过期。
正确的做法应该是使用jedis的set指令:
private static final String LOCK_SUCCESS = "OK";private static final String SET_IF_NOT_EXIST = "NX";private static final String SET_WITH_EXPIRE_TIME = "PX";/*** 尝试获取分布式锁* @param jedis Redis客户端* @param lockKey 锁* @param requestId 请求标识* @param expireTime 超期时间* @return 是否获取成功*/public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, long expireTime) {String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);if (LOCK_SUCCESS.equals(result)) {return true;}return false;}
可以看到加锁就一行代码:jedis.set(String key, String value, String nxxx, String expx, long time),这个set()方法一共有五个形参:
第一个为key,使用key来当锁,因为key是唯一的。
第二个为value,传的是requestId。requestId可以使用UUID.randomUUID().toString()方法生成。
假如value不是随机字符串,而是一个固定值,那么就可能存在下面的问题:
1.客户端1获取锁成功
2.客户端1在某个操作上阻塞了太长时间
3.设置的key过期了,锁自动释放了
4.客户端2获取到了对应同一个资源的锁
5.客户端1从阻塞中恢复过来,因为value值一样,所以执行释放锁操作时就会释放掉客户端2持有的锁,这样就会造成问题
所以通常来说,在释放锁时,我们需要对value进行验证。通过给value赋值为requestId,我们就知道这把锁是哪个请求加的了,在解锁的时候就可以有依据。
第三个为nxxx,这个参数填的是NX,意思是SET IF NOT EXIST,即当key不存在时,我们进行set操作,若key已经存在,则不做任何操作;如果是XX的话,就是只在key存在时候进行set操作。
第四个为expx,这个参数传的是PX,EX代表过期时间单位为 秒,PX代表毫秒。具体时间由第五个参数决定。
第五个为time,与第四个参数相呼应,代表key的过期时间。
总的来说,执行上面的set()方法就只会导致两种结果:1. 当前没有锁(key不存在),那么就进行加锁操作,并对锁设置个有效期,同时value表示加锁的客户端。2. 已有锁存在,不做任何操作。
那么怎么释放锁呢?
private static final Long RELEASE_SUCCESS = 1L;/*** 释放分布式锁* @param jedis Redis客户端* @param lockKey 锁* @param requestId 请求标识* @return 是否释放成功*/public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));if (RELEASE_SUCCESS.equals(result)) {return true;}return false;}
释放锁时需要验证value值,也就是说我们在获取锁的时候需要设置一个value,不能直接用del key这种粗暴的方式,因为直接del key任何客户端都可以进行解锁了,所以解锁时,我们需要判断锁是否是自己的,基于value值来判断。
第二行代码,我们将Lua代码传到jedis.eval()方法里,并使参数KEYS[1]赋值为lockKey,ARGV[1]赋值为requestId。eval()方法是将Lua代码交给Redis服务端执行。那么这段Lua代码的功能是什么呢?其实很简单,首先获取锁对应的value值,检查是否与requestId相等,如果相等则删除锁(解锁)。
为什么要使用Lua语言来实现呢?因为要确保上述操作是原子性的。
执行eval()方法可以确保原子性,源于Redis的特性,下面是官网对eval命令的部分解释:
简单来说,就是在eval命令执行Lua代码的时候,Lua代码将被当成一个命令去执行,并且直到eval命令执行完成,Redis才会执行其他命令。
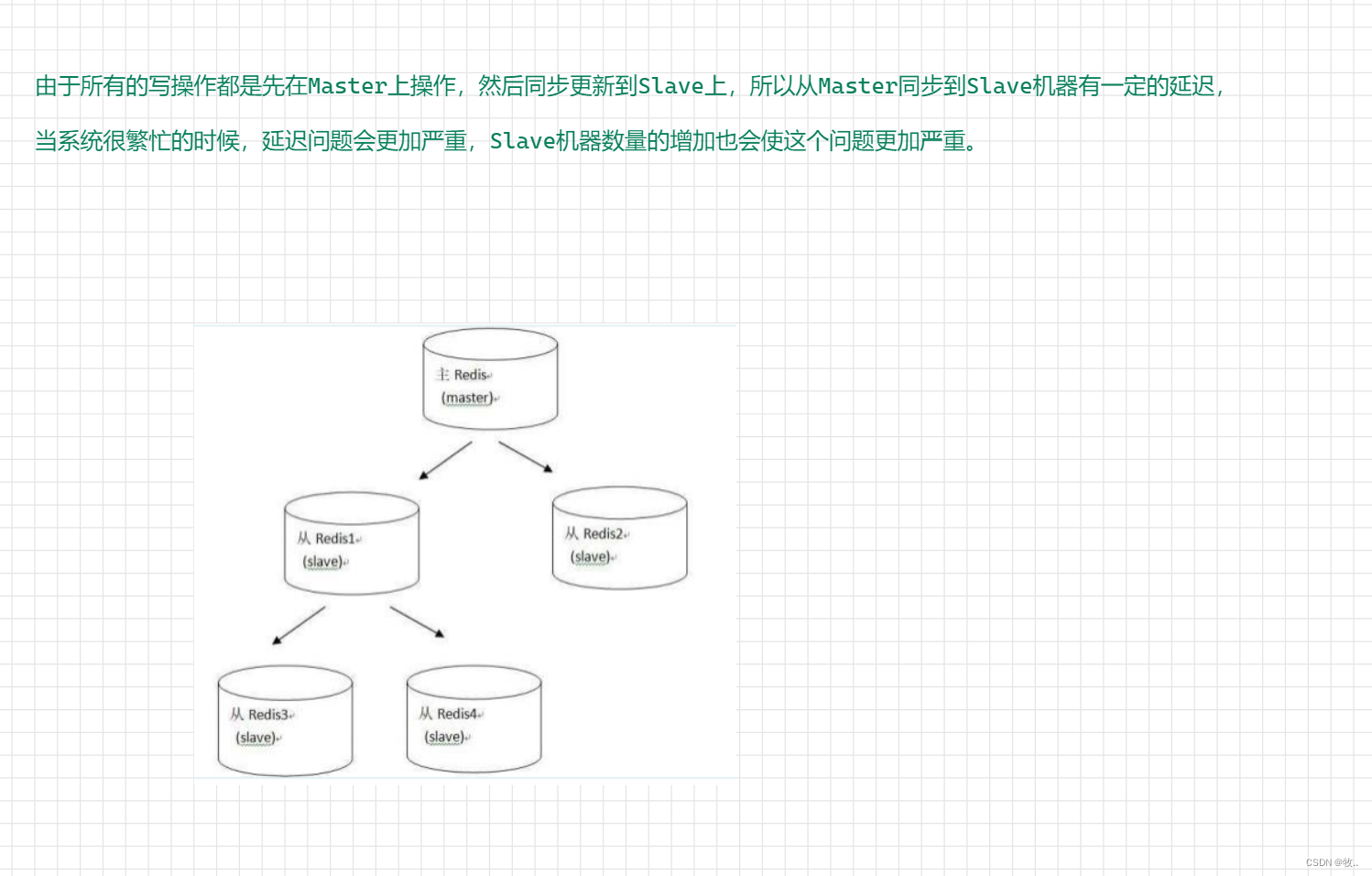
实际上在Redis集群的时候也会出现问题,比如说A客户端在Redis的master节点上拿到了锁,但是这个加锁的key还没有同步到slave节点,master故障,发生故障转移,一个slave节点升级为master节点,B客户端也可以获取同个key的锁,但客户端A也已经拿到锁了,这就导致多个客户端都拿到锁。
4、Redission
对于Java用户而言,我们经常使用Jedis,Jedis是Redis的Java客户端,除了Jedis之外,Redisson也是Java的客户端。
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
具体使用过程如下。
- 首先加入pom依赖
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.10.6</version>
</dependency>
- 使用Redisson,代码如下:
// 1. 配置文件
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword(RedisConfig.PASSWORD).setDatabase(0);
//2. 构造RedissonClient
RedissonClient redissonClient = Redisson.create(config);//3. 设置锁定资源名称
RLock lock = redissonClient.getLock("redlock");
lock.lock();
try {System.out.println("获取锁成功,实现业务逻辑");Thread.sleep(10000);
} catch (InterruptedException e) {e.printStackTrace();
} finally {lock.unlock();
}
并且在redisson中,还封装了其他的锁算法,比如红锁。
详情可以看官方github:https://github.com/redisson/redisson/wiki/Table-of-Content
附录:
在传统单体应用单机部署的情况下,可以使用Java并发处理相关的API(如ReentrantLock或Synchronized)进行锁控制。但是在分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java
API并不能提供分布式锁的能力。