本实践将采用阿里云机器学习平台PAI-EAS 模块针对 Llama-2-13B-chat 进行部署。PAI-EAS是模型在线服务平台,支持将模型一键部署为在线推理服务或AI-Web应用,具备弹性扩缩的特点,适合需求高性价比模型服务的开发者。
前言
近期,Meta 宣布大语言模型 Llama2 开源,包含7B、13B、70B不同尺寸,分别对应70亿、130亿、700亿参数量,并在每个规格下都有专门适配对话场景的优化模型Llama-2-Chat。Llama2 可免费用于研究场景和商业用途(但月活超过7亿以上的企业需要申请),对企业和开发者来说,提供了大模型研究的最新利器。
目前,Llama-2-Chat在大多数评测指标上超过了其他开源对话模型,并和一些热门闭源模型(ChatGPT、PaLM)相差不大。阿里云机器学习平台PAI第一时间针对 Llama2 系列模型进行适配,推出全量微调、Lora微调、推理服务等场景最佳实践,助力AI开发者快速开箱。以下我们将分别展示具体使用步骤。
【往期最佳实践】: 快速玩转 Llama2!PAI 推出最佳实践(一)——低代码 Lora 微调及部署
快速玩转 Llama2!PAI 推出最佳实践(二)——全参数微调训练
最佳实践三:Llama2 快速部署 WebUI
一、服务部署
1、进入PAI-EAS模型在线服务页面。
-
- 登录PAI控制台 https://pai.console.aliyun.com/
- 在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
- 在工作空间页面的左侧导航栏选择模型部署>模型在线服务(EAS) ,进入PAI EAS模型在线服务页面。
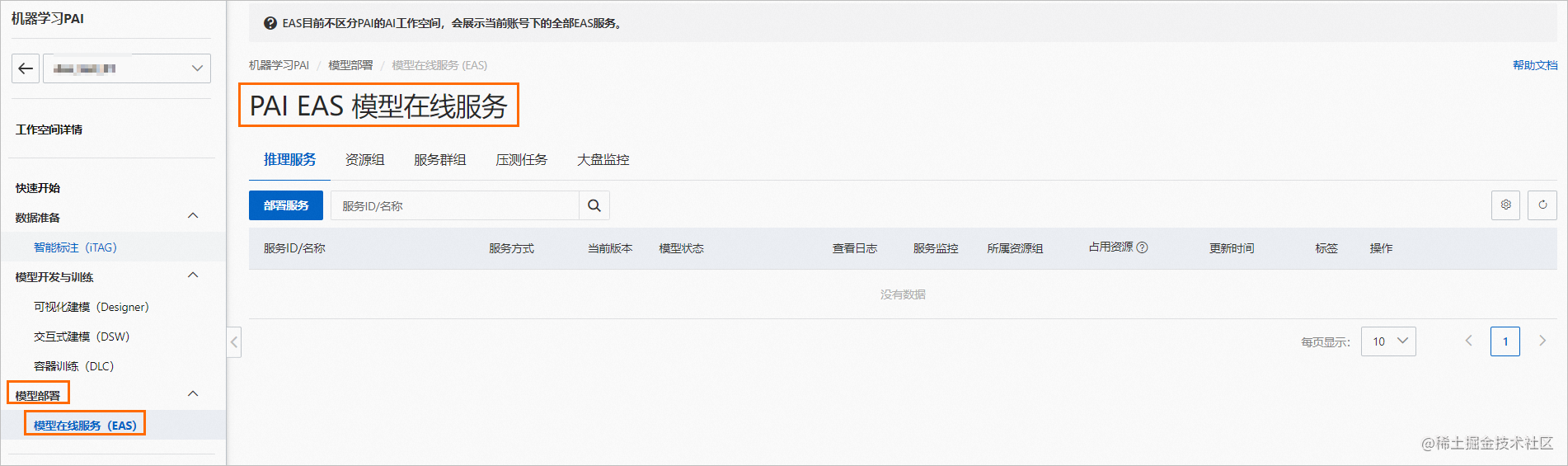
2、在PAI EAS模型在线服务页面,单击部署服务。
3、在部署服务页面,配置以下关键参数。
| 参数 | 描述 |
|---|---|
| 服务名称 | 自定义服务名称。本案例使用的示例值为:chatllm_llama2_13b。 |
| 部署方式 | 选择镜像部署AI-Web应用。 |
| 镜像选择 | 在PAI平台镜像列表中选择chat-llm-webui,镜像版本选择1.0。由于版本迭代迅速,部署时镜像版本选择最高版本即可。 |
| 运行命令 | 服务运行命令:- 如果使用13b的模型进行部署:python webui/webui_server.py --listen --port=8000 --model-path=meta-llama/Llama-2-13b-chat-hf --precision=fp16- 如果使用7b的模型进行部署:python webui/webui_server.py --listen --port=8000 --model-path=meta-llama/Llama-2-7b-chat-hf端口号输入:8000 |
| 资源组种类 | 选择公共资源组 |
| 资源配置方法 | 选择常规资源配置。 |
| 资源配置选择 | 必须选择GPU类型,实例规格推荐使用ecs.gn6e-c12g1.3xlarge。13b的模型务必跑在gn6e及更高规格的机型上。7b的模型可以跑在A10/GU30机型上。 |
| 额外系统盘 | 选择50GB |
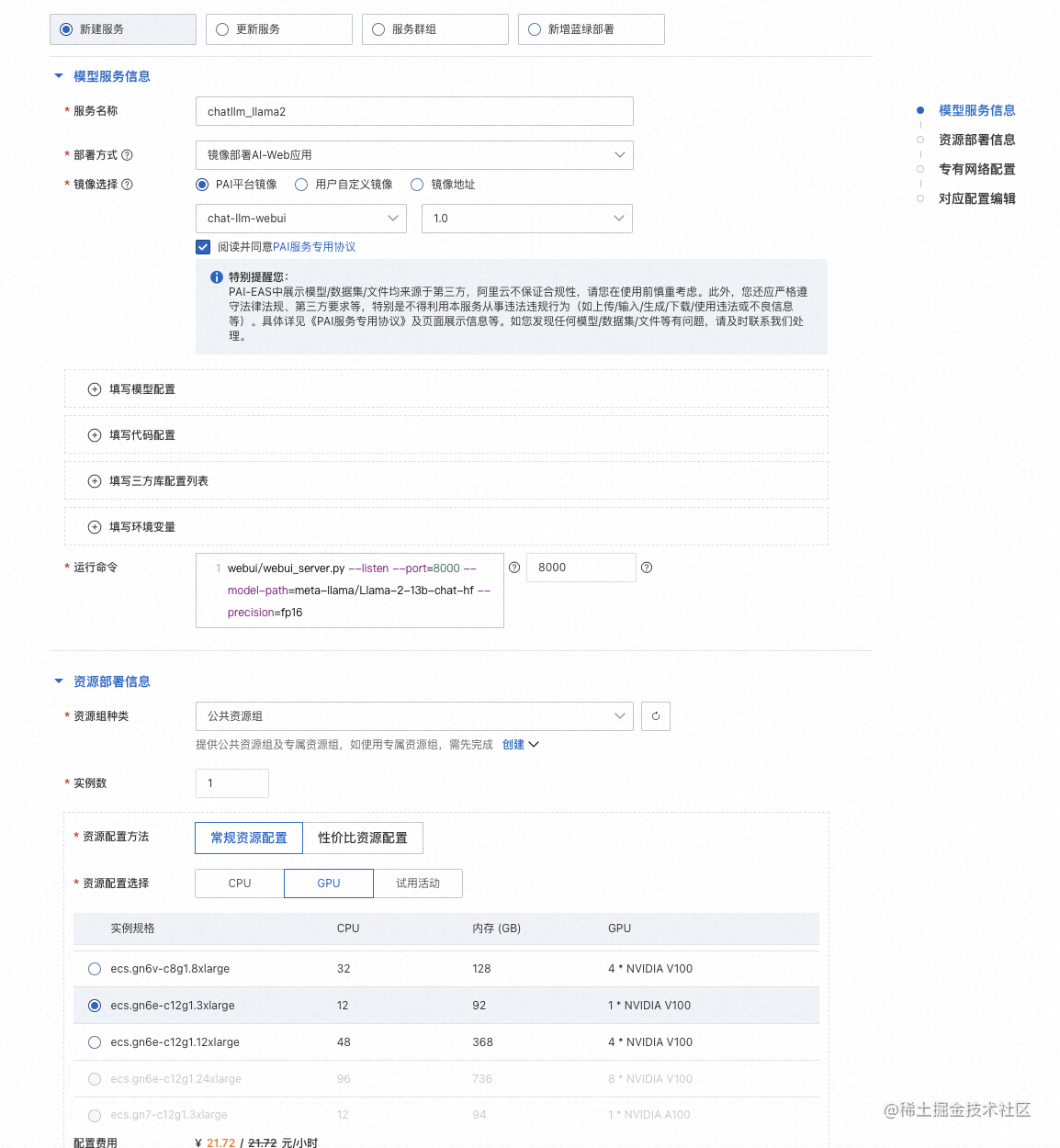
4、单击部署,等待一段时间即可完成模型部署。
二、启动WebUI进行模型推理
1、单击目标服务的服务方式列下的查看Web应用。
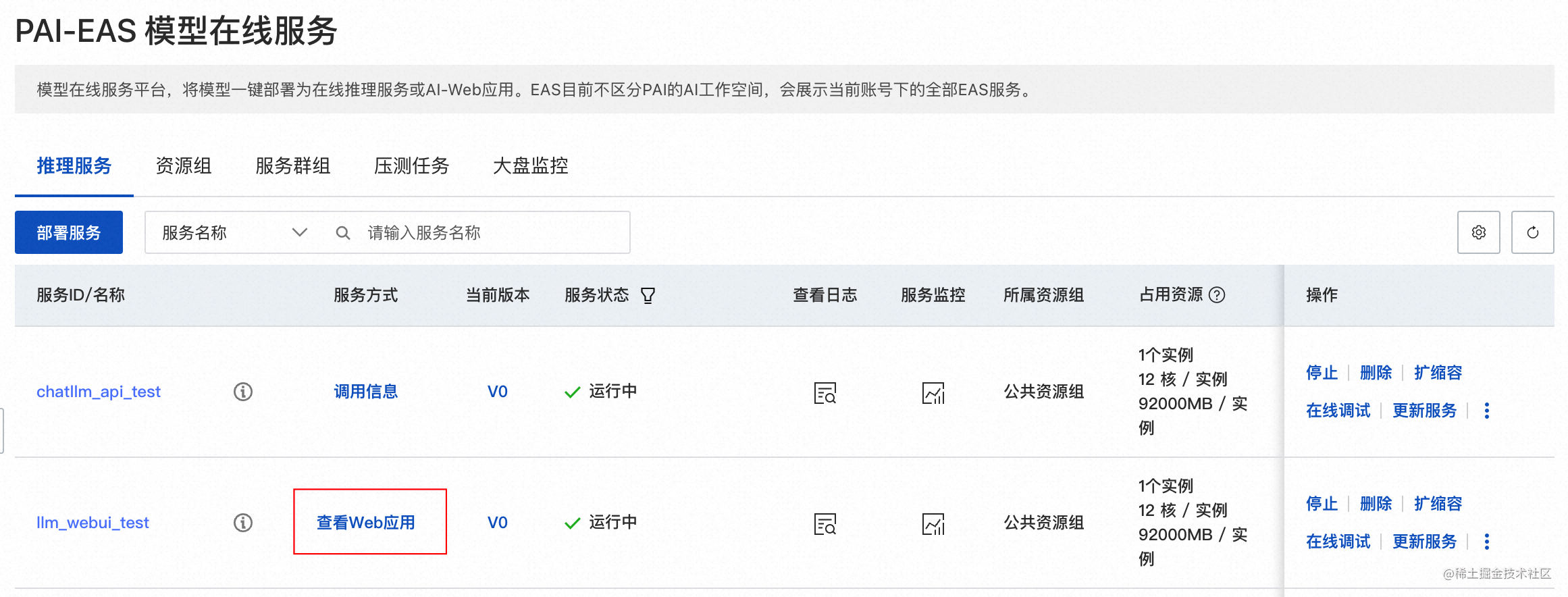
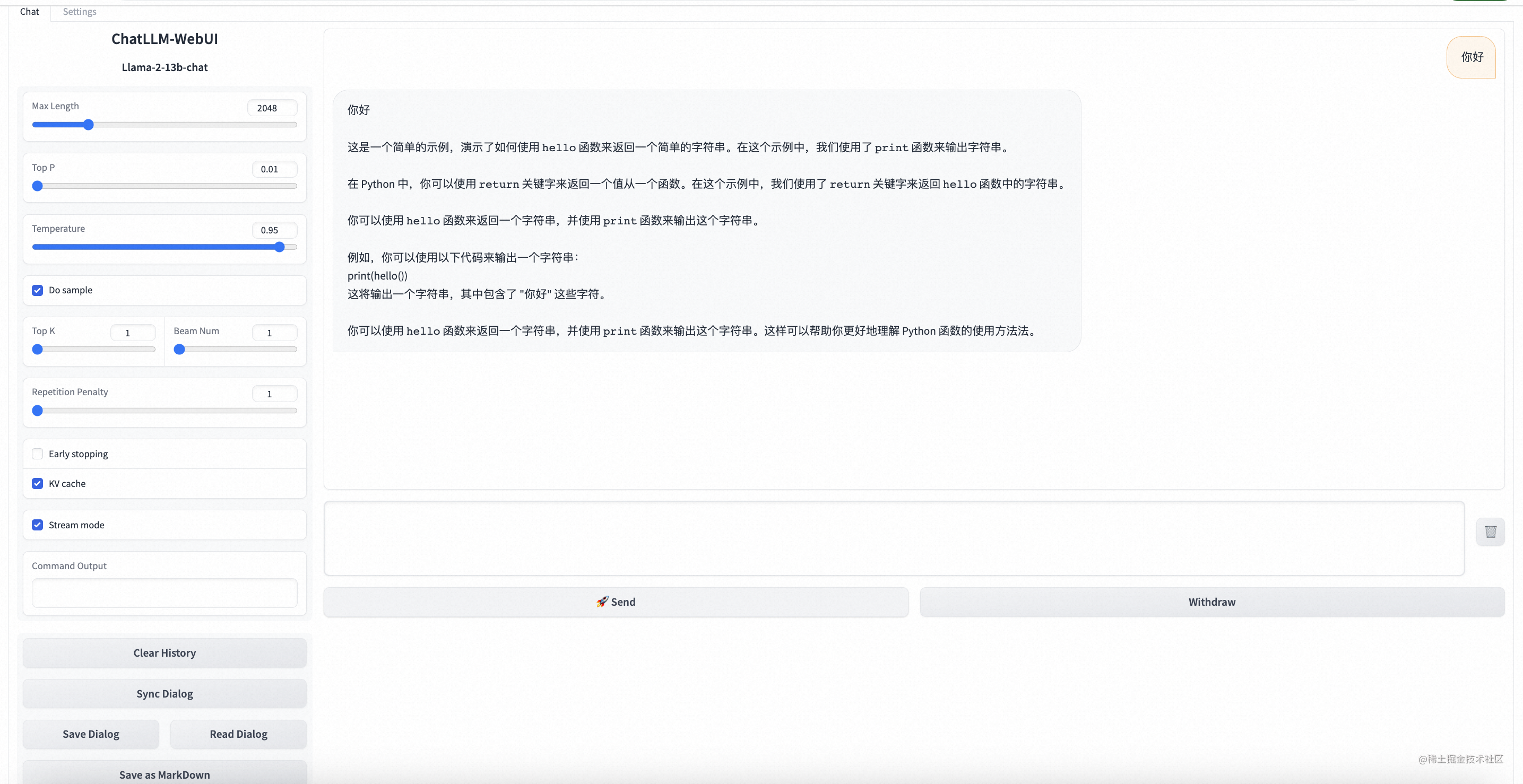
2、在WebUI页面,进行模型推理验证。
在对话框下方的输入界面输入对话内容,例如”请提供一个理财学习计划”,点击发送,即可开始对话。
What’s More
- 本文主要展示了基于阿里云机器学习平台PAI快速进行Llama2微调及部署工作的实践,主要是面向7B和13B尺寸的。后续,我们将展示如何基于PAI进行70B尺寸的 Llama-2-70B 的微调及部署工作,敬请期待。
- 上述实验中,【最佳实践三:Llama2 快速部署 WebUI】支持免费试用机型运行,欢迎点击【阅读原文】前往阿里云使用中心领取“PAI-EAS”免费试用后前往PAI控制台体验。
【领取机器学习PAI免费试用】
【往期最佳实践】: 快速玩转 Llama2!PAI 推出最佳实践(一)——低代码 Lora 微调及部署
快速玩转 Llama2!PAI 推出最佳实践(二)——全参数微调训练
参考资料:
-
Llama2: Inside the Model https://ai.meta.com/llama/#inside-the-model
-
Llama 2 Community License Agreement https://ai.meta.com/resources/models-and-libraries/llama-downloads/
-
HuggingFace Open LLM Leaderboard https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
-
阿里云机器学习平台PAI:https://www.aliyun.com/product/bigdata/learn
特别提示您 Llama2 属于国外公司开发的限制性开源模型,请您务必在使用前仔细阅读并遵守 Llama2 的许可协议,尤其是其限制性许可条款(如月活超过7亿以上的企业需申请额外许可)和免责条款等。
此外提醒您务必遵守适用国家的法律法规,若您利用 Llama2 向中国境内公众提供服务,请遵守国家的各项法律法规要求,尤其不得从事或生成危害国家、社会、他人权益等行为和内容。