原理
1. 将日志进行集中化管理(beats)
2. 将日志格式化(logstash)
将其安装在那个上面就对那个进行监控
3. 对格式化后的数据进行索引和存储(elasticsearch)
4. 前端数据的展示(kibana)
环境
要准备安装包
elasticsearch
elasticsearch-head
kibana
logstash
node
phantomjs
这些安装包都在网上很好找,自己去找最新的安装包也行,和我这个版本区别不大
服务器(1)centos7 -- 192.168.254.1 -elasticsearch集群一份子,节点1(tarro1)节点1名字随便起
上面安装 elasticsearch,elasticsearch-head
服务器(2)centos7 -- 192.168.254.2 -elasticsearch集群一份子,节点2(tarro2)节点2名字随便起
上面安装 elasticsearch,elasticsearch-head logstash(监控其系统文件)
服务器(3)centos7 -- 192.168.254.3 -- http服务
上面开启http服务 并安装 logstash(监控其系统文件)
服务器(4)centos7 -- 192.168.254-3 -- kibana服务
上面开启kibana连接节点1和2 展示两位的收集出来的日志信息
(1)和(2)要做一个集群hosts相互些写一下就行
全部关闭防火墙
全部关闭防火墙
全部关闭防火墙
服务器(1)的配置
先将elasticsearch elasticsearch-head node phantomjs 包放进去
hostnamectl set-hostname tarro1
写入hosts

安装java
yum -y install javarpm -ivh elasticsearch-5.5.0.rpm systemctl daemon-reloadsystemctl enable elasticsearch.servicecp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bakvim /etc/elasticsearch/elasticsearch.yml 17 cluster.name: my-elk23 node.name: tarro133 path.data: /data/elk_data37 path.logs: /var/log/elasticsearch/ 43 bootstrap.memory_lock: false55 network.host: 0.0.0.059 http.port: 920068 discovery.zen.ping.unicast.hosts: ["tarro1", "tarro2"]前面的# 全去掉
群集名称
17 cluster.name: my-elk-cluster
节点服务器名称23 node.name: node1
数据存放路径33 path.data: /data/elk_data
日志存放路径37 path.logs: /var/log/elasticsearch/ 在启动时不锁定内存43 bootstrap.memory_lock: false提供服务绑定的ip地址,0.0.0.0表示所有地址55 network.host: 0.0.0.0侦听端口59 http.port: 9200群集发现通过单播实现68 discovery.zen.ping.unicast.hosts: ["node1", "node2"]mkdir -p /data/elk_datachown elasticsearch.elasticsearch /data/elk_data/systemctl start elasticsearch.servicenetstat -anpt | grep 9200
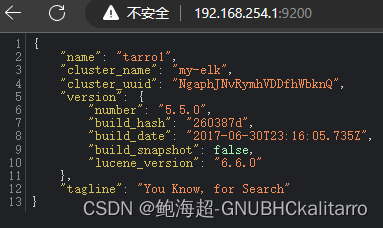
开启成功
yum -y install make gcc gcc-c++
tar xf node-v8.2.1.tar.gzcd node-v8.2.1./configure && make && make install# 这里耐心等待,需要20分钟左右
tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/srccp /usr/src/phantomjs-2.1.1-linux-x86_64/bin/phantomjs /usr/local/bin/tar xf elasticsearch-head.tar.gz -C /usr/srccd /usr/src/elasticsearch-head/npm installvim /etc/elasticsearch/elasticsearch.yml 末尾添加
http.cors.enabled: true
http.cors.allow-origin: "*"systemctl restart elasticsearchnpm start &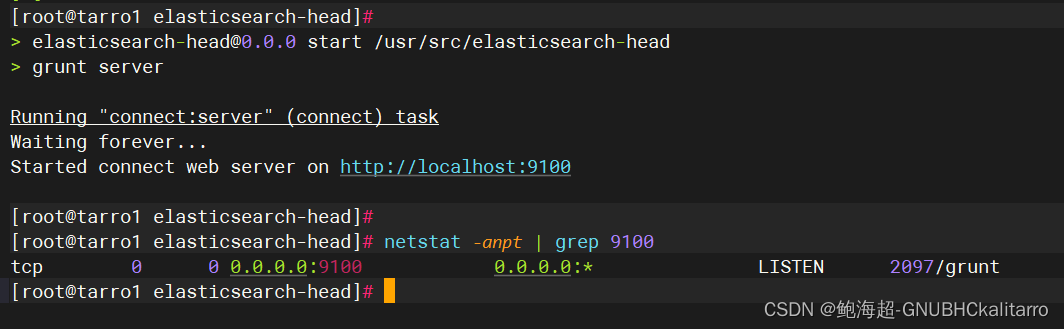
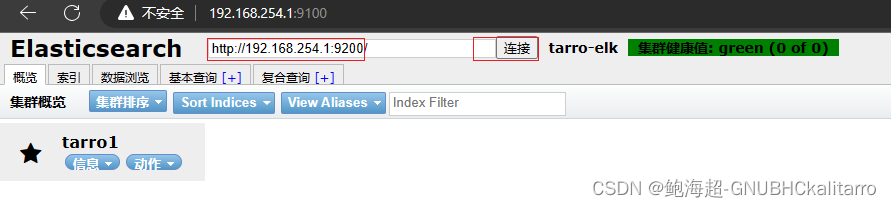
如果你重启以后可以执行
cd /usr/src/elasticsearch-head/ && npm start &快速启动
成功
服务器(2)的配置
先将elasticsearch elasticsearch-head node phantomjs logstash 包放进去
hostnamectl set-hostname tarro2 写入hosts
安装java
yum -y install javarpm -ivh elasticsearch-5.5.0.rpm systemctl daemon-reloadsystemctl enable elasticsearch.servicecp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bakvim /etc/elasticsearch/elasticsearch.yml 17 cluster.name: my-elk23 node.name: tarro233 path.data: /data/elk_data37 path.logs: /var/log/elasticsearch/ 43 bootstrap.memory_lock: false55 network.host: 0.0.0.059 http.port: 920068 discovery.zen.ping.unicast.hosts: ["tarro1", "tarro2"]前面的# 全去掉
群集名称
17 cluster.name: my-elk-cluster
节点服务器名称23 node.name: node1
数据存放路径33 path.data: /data/elk_data
日志存放路径37 path.logs: /var/log/elasticsearch/ 在启动时不锁定内存43 bootstrap.memory_lock: false提供服务绑定的ip地址,0.0.0.0表示所有地址55 network.host: 0.0.0.0侦听端口59 http.port: 9200群集发现通过单播实现68 discovery.zen.ping.unicast.hosts: ["node1", "node2"]mkdir -p /data/elk_datachown elasticsearch.elasticsearch /data/elk_data/systemctl start elasticsearch.servicenetstat -anpt | grep 9200
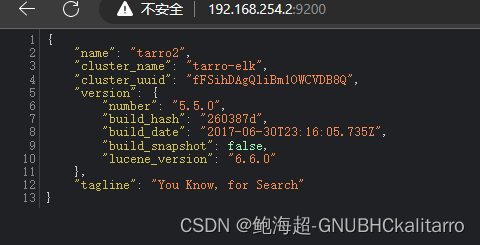
成功
yum -y install make gcc gcc-c++tar xf node-v8.2.1.tar.gz cd node-v8.2.1./configure && make && make install# 很久,耐心等待
tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/src
cp /usr/src/phantomjs-2.1.1-linux-x86_64/bin/phantomjs /usr/local/bin/tar xf elasticsearch-head.tar.gz -C /usr/srccd /usr/src/elasticsearch-head/npm installvim /etc/elasticsearch/elasticsearch.yml 末尾添加
http.cors.enabled: true
http.cors.allow-origin: "*"systemctl restart elasticsearch
npm start &
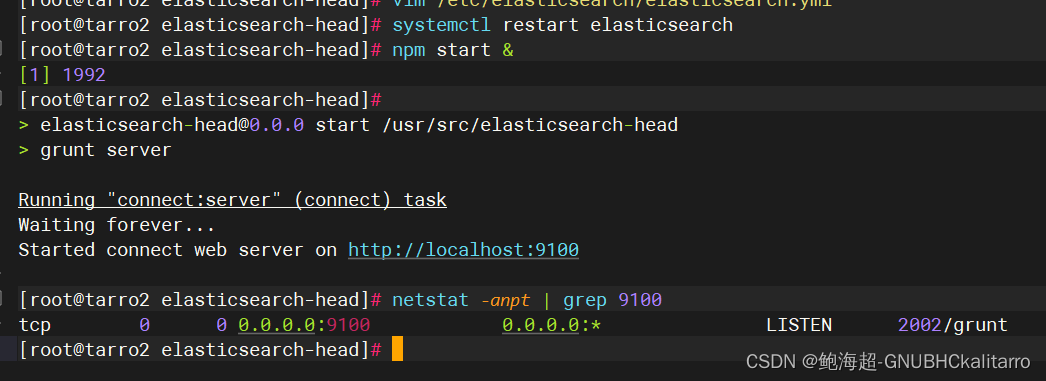
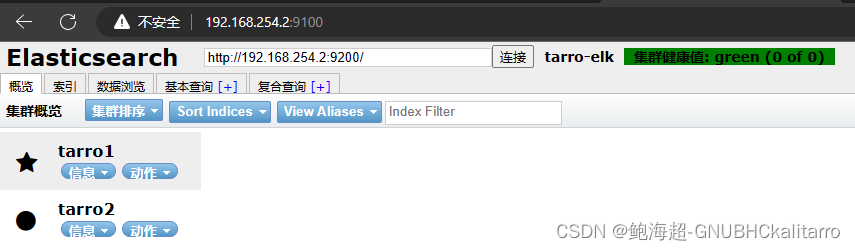
如果你重启以后可以执行
cd /usr/src/elasticsearch-head/ && npm start &快速启动
成功
rpm -ivh logstash-5.5.1.rpm systemctl start logstash.serviceln -s /usr/share/logstash/bin/logstash /usr/local/bin/chmod o+r /var/log/messages vim /etc/logstash/conf.d/system.confinput {file {path => "/var/log/messages"type => "system"start_position => "beginning"}
}output {elasticsearch {hosts => ["192.168.254.1:9200"]index => "system-%{+YYYY.MM.dd}"}
}
#________________________________________注释:
input {file { 从文件中读取path => "/var/log/messages" 文件路径type => "system"start_position => "beginning" 是否从头开始读取}}output {elasticsearch { 输出到elasticsearch中hosts => ["192.168.10.181:9200"] elasticsearch主机地址和端口index => "system-%{+YYYY.MM.dd}" 索引名称}}
---------------------------systemctl restart logstash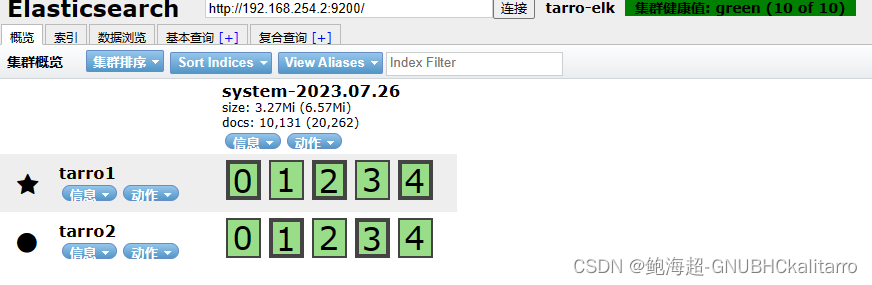
现在就已经可以收集日志了,收集的是tarro2主机上的日志
这样就配置成功了
服务器(3)的配置
yum -y install httpdsystemctl start httpd
可以访问就行,这里主要将的不是http而是logstash
将logstash 传入服务器(3)内
yum -y install javarpm -ivh logstash-5.5.1.rpm systemctl daemon-reload
systemctl enable logstash.servicevim /etc/logstash/conf.d/apache_log.confinput {file {path => "/etc/httpd/logs/access_log"type => "access"start_position => "beginning"} file {path => "/etc/httpd/logs/error_log"type => "error"start_position => "beginning"}
}output {if [type] == "access" {elasticsearch {hosts => ["192.168.254.1:9200"]index => "apache_access-%{+YYYY.MM.dd}"}}if [type] == "error" {elasticsearch {hosts => ["192.168.254.1:9200"]index => "apache_error-%{+YYYY.MM.dd}"}}}
ln -s /usr/share/logstash/bin/logstash /usr/local/binlogstash -f /etc/logstash/conf.d/apache_log.conf 
这样以后去 Elasticsearch 集群看一下
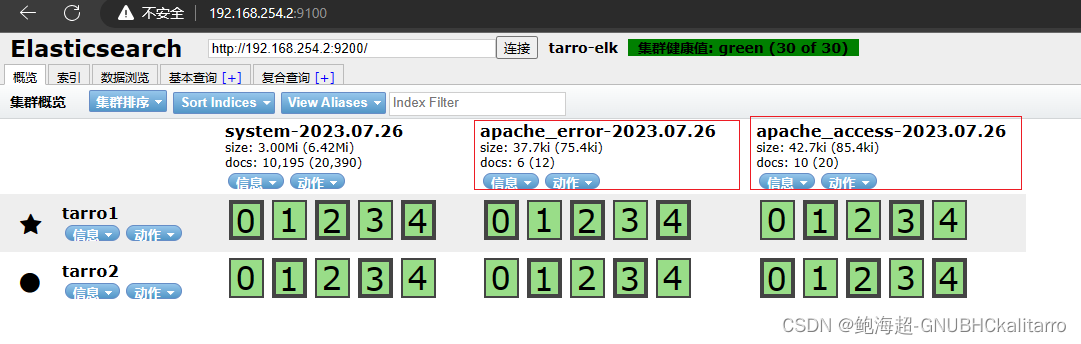
收集日志成功
服务器(4)的配置
安装一个kibana展示出来
yum -y install java将 kibana包传入服务器(4)
rpm -ivh kibana-5.5.1-x86_64.rpm systemctl enable kibanavim /etc/kibana/kibana.yml 2 server.port: 56017 server.host: "0.0.0.0"21 elasticsearch.url: "http://192.168.254.1:9200"30 kibana.index: ".kibana"去掉前面#注释:server.port: 5601 kibana打开的端口server.host: "0.0.0.0" kibana侦听的地址elasticsearch.url: "http://192.168.10.181:9200" 和elasticsearch建立联系kibana.index: ".kibana" 在elasticsearch中添加.kibana索引systemctl start kibana
http://192.168.254.4:5601/
↑
http://kibanaip:5601/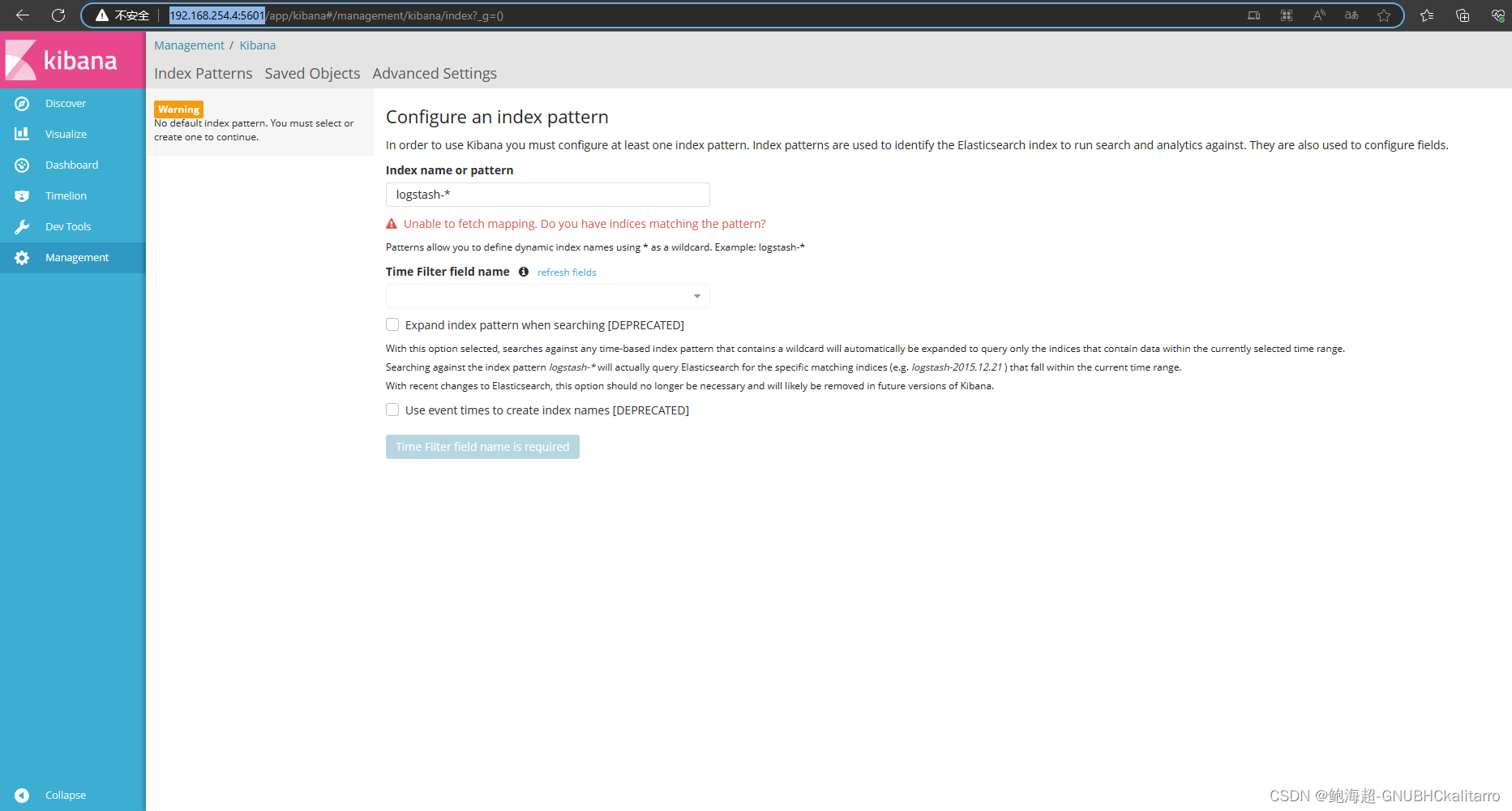
进入成功
设置kibana展示
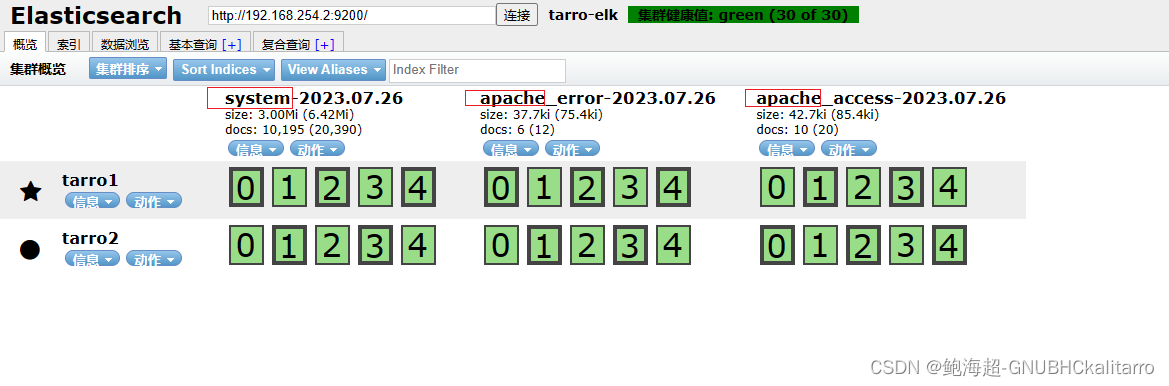

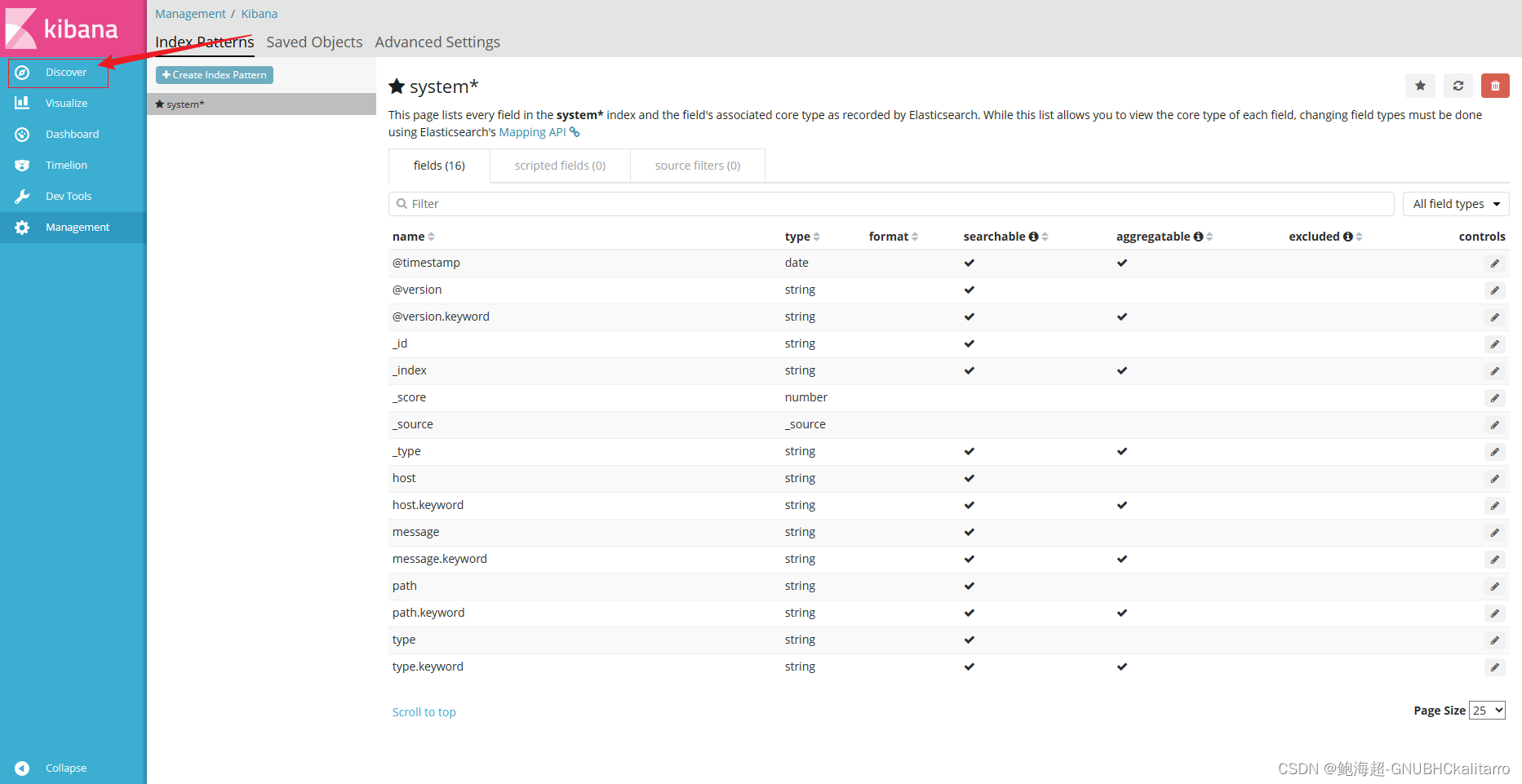
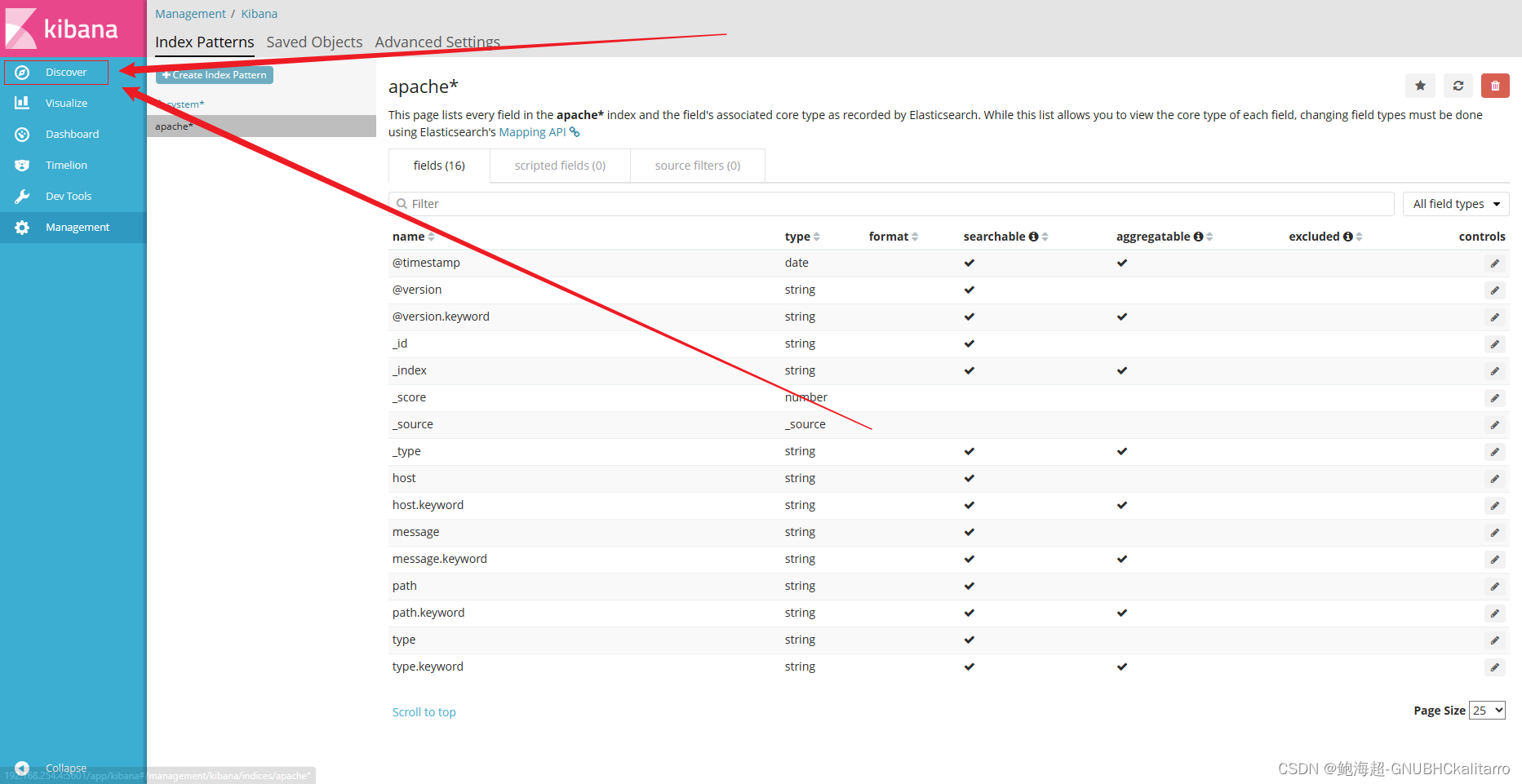
 这个是192.168.254.2的系统日志展示,还差个192.168.254.3的网站日志展示
这个是192.168.254.2的系统日志展示,还差个192.168.254.3的网站日志展示
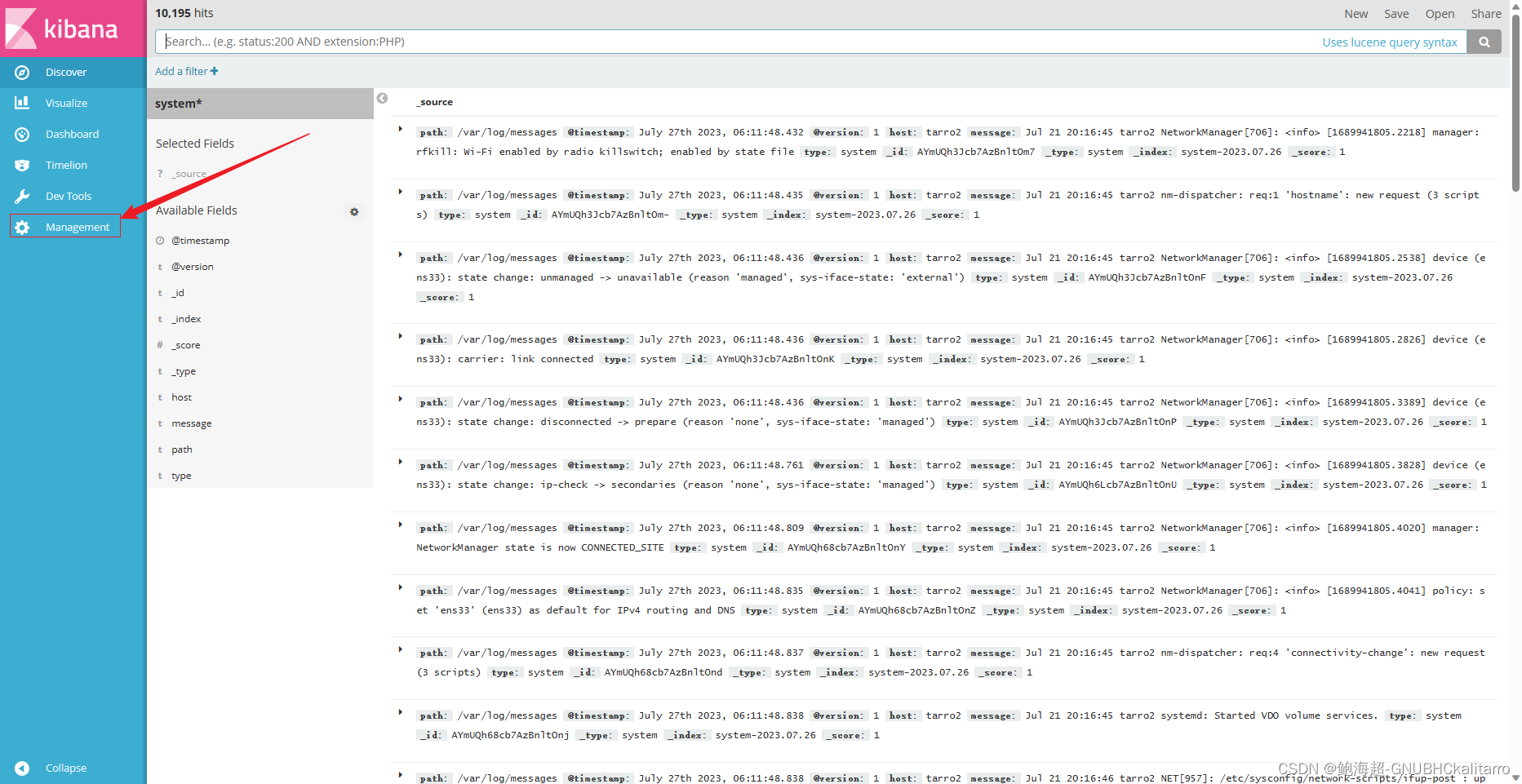
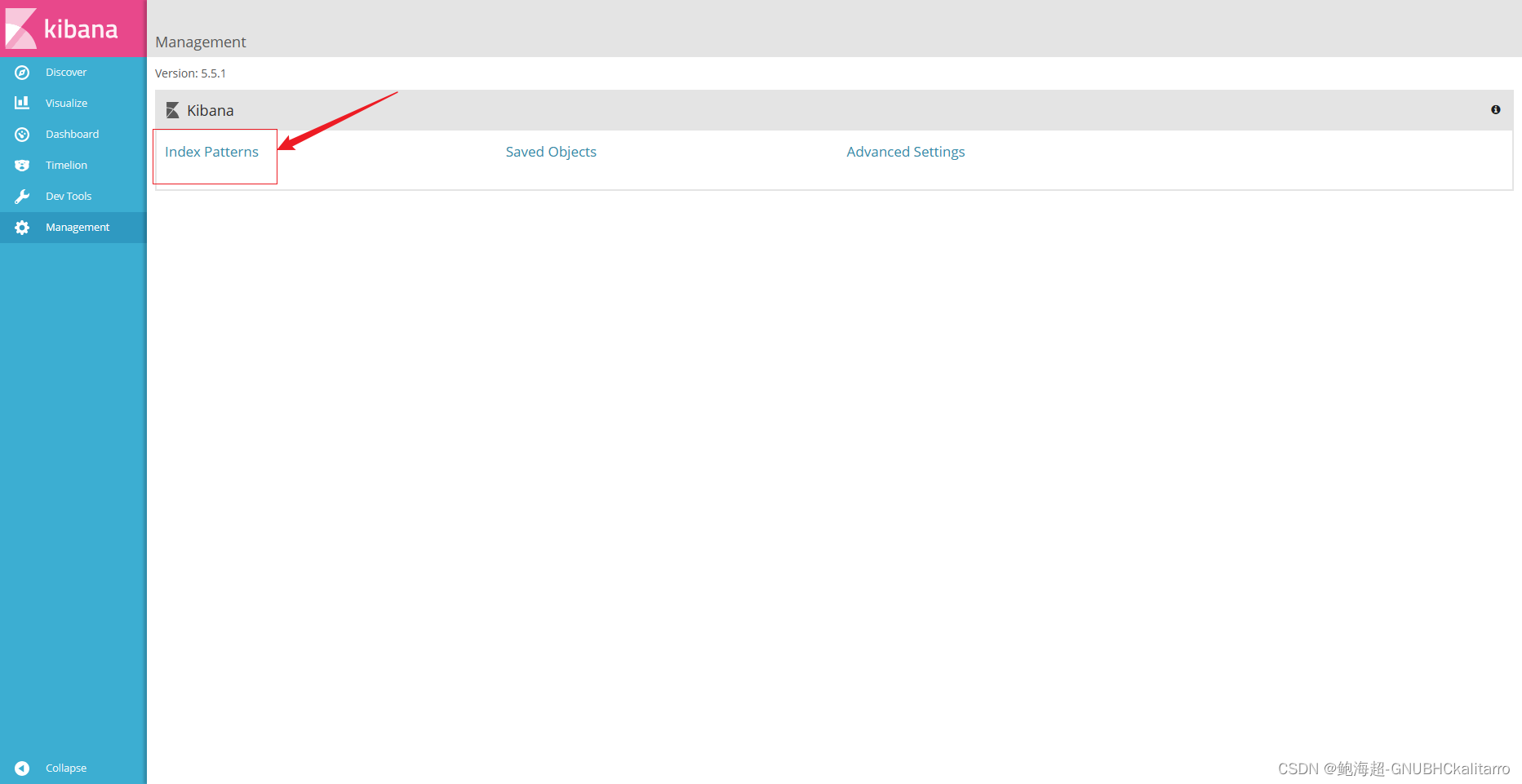
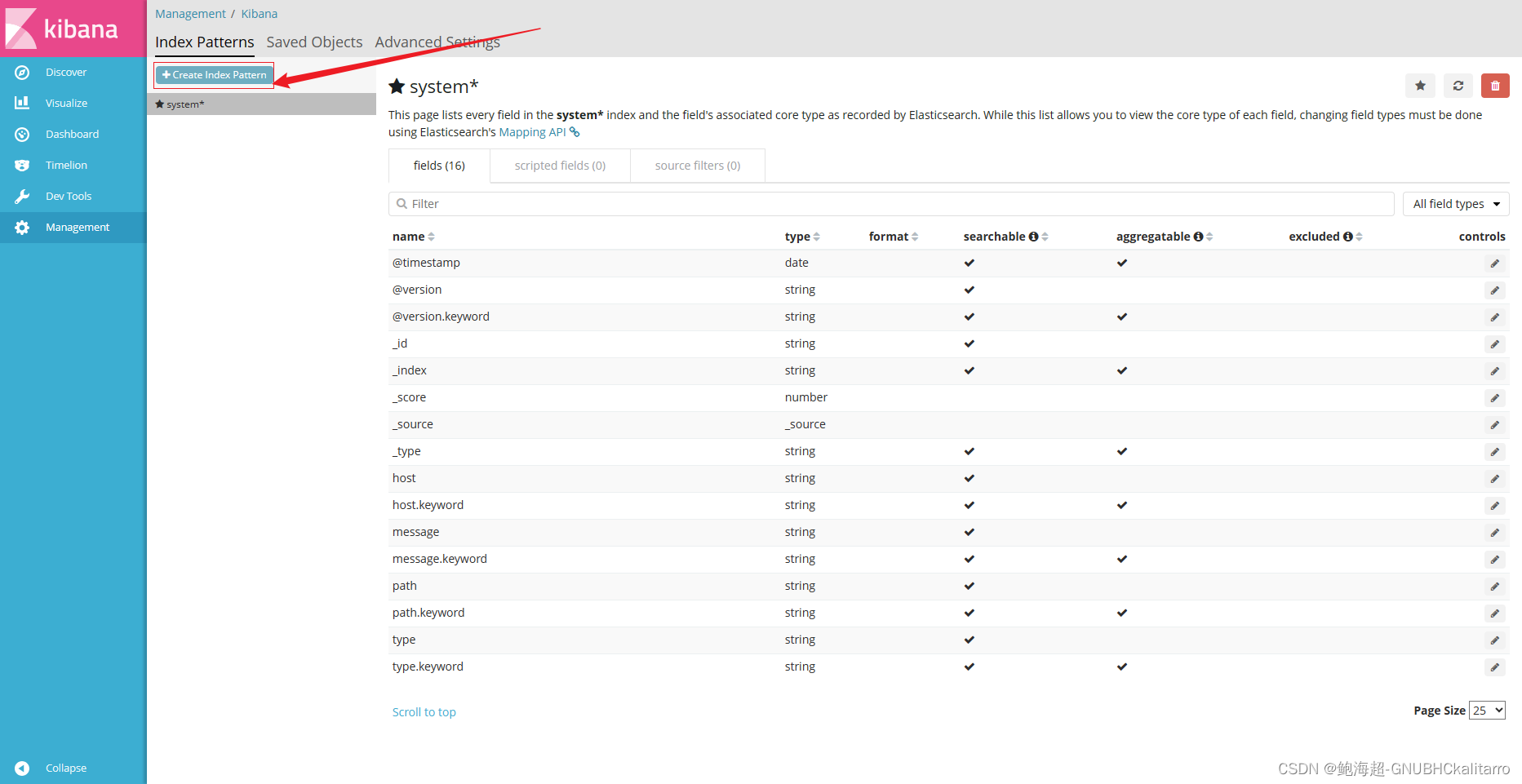
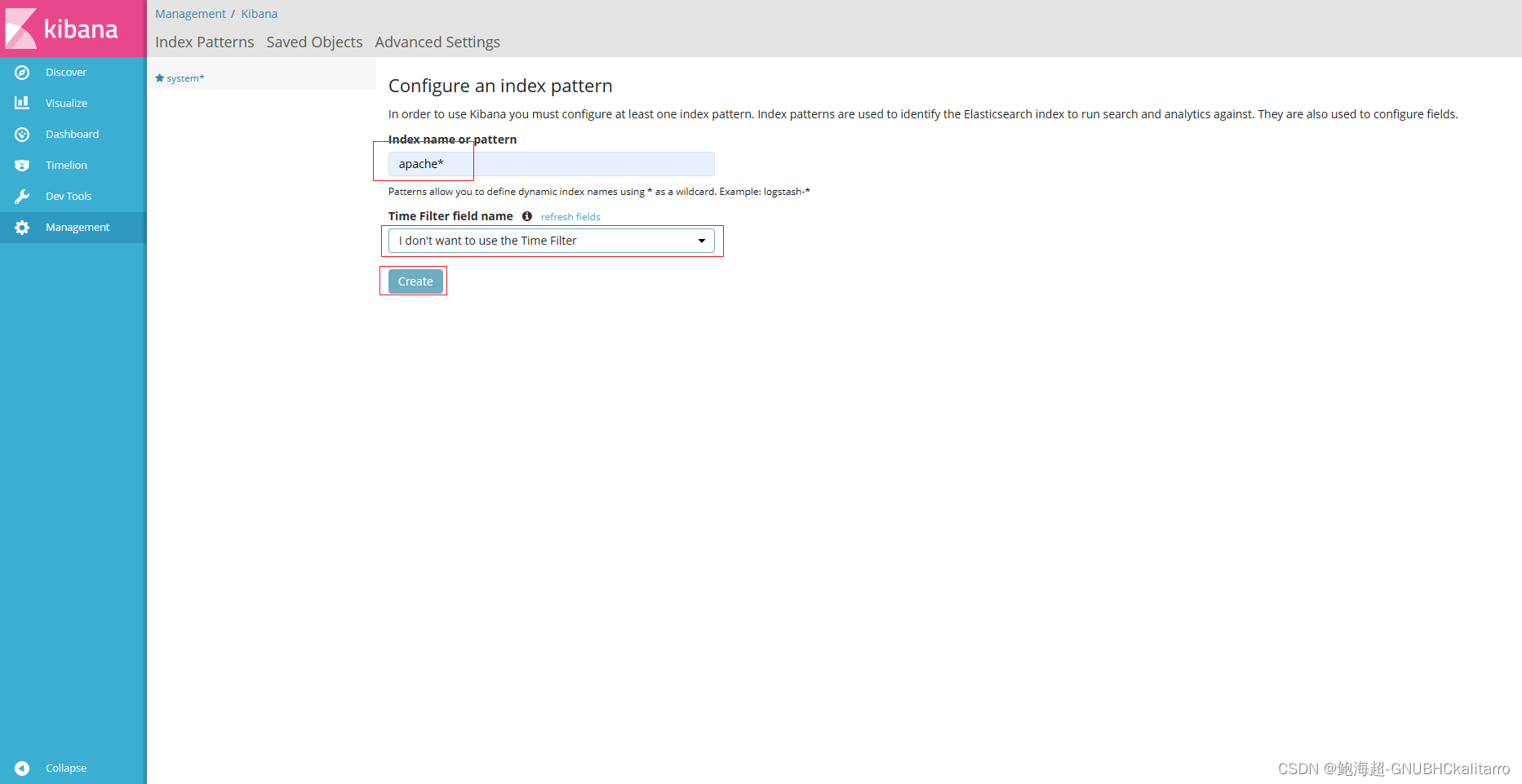
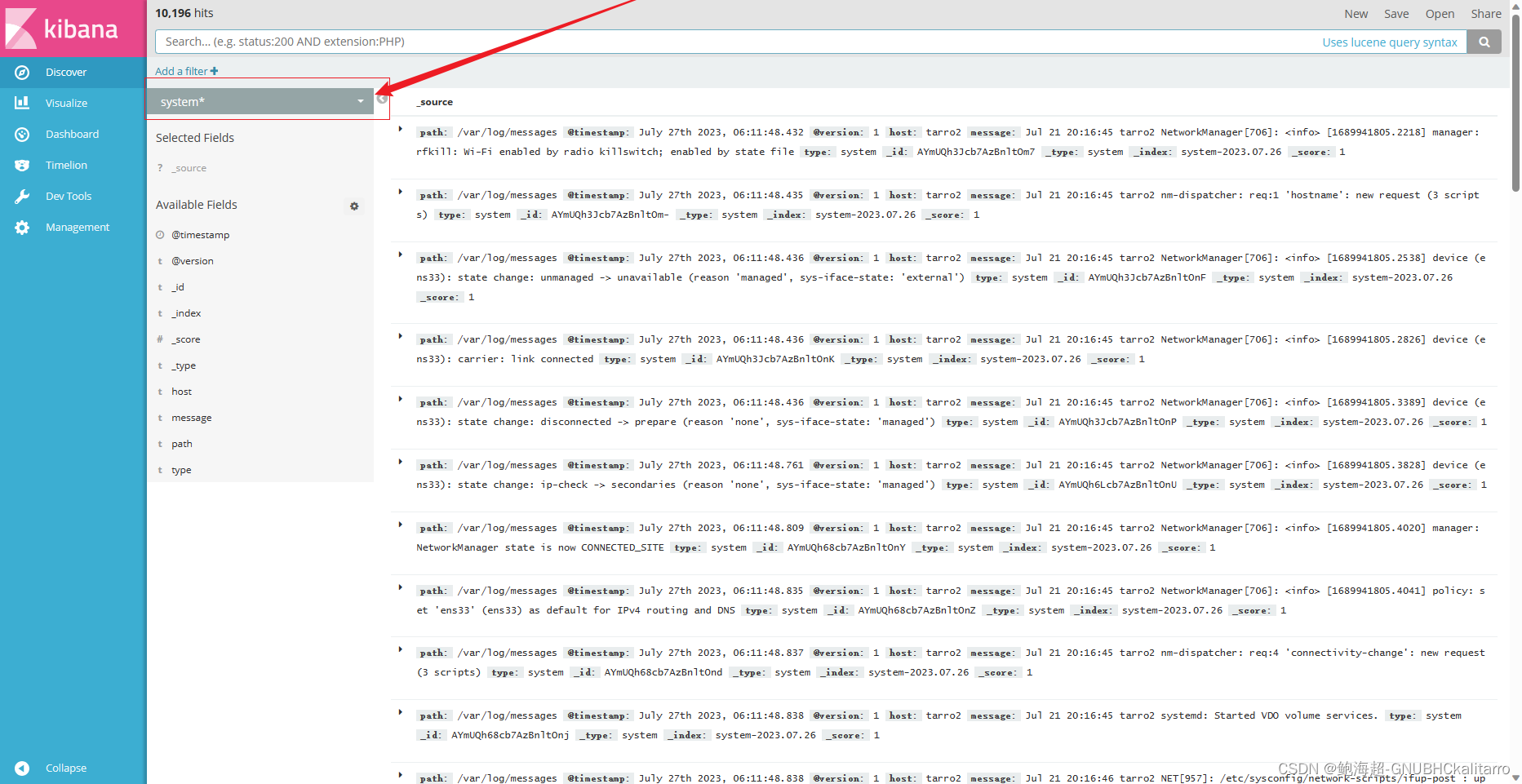 点击切换
点击切换
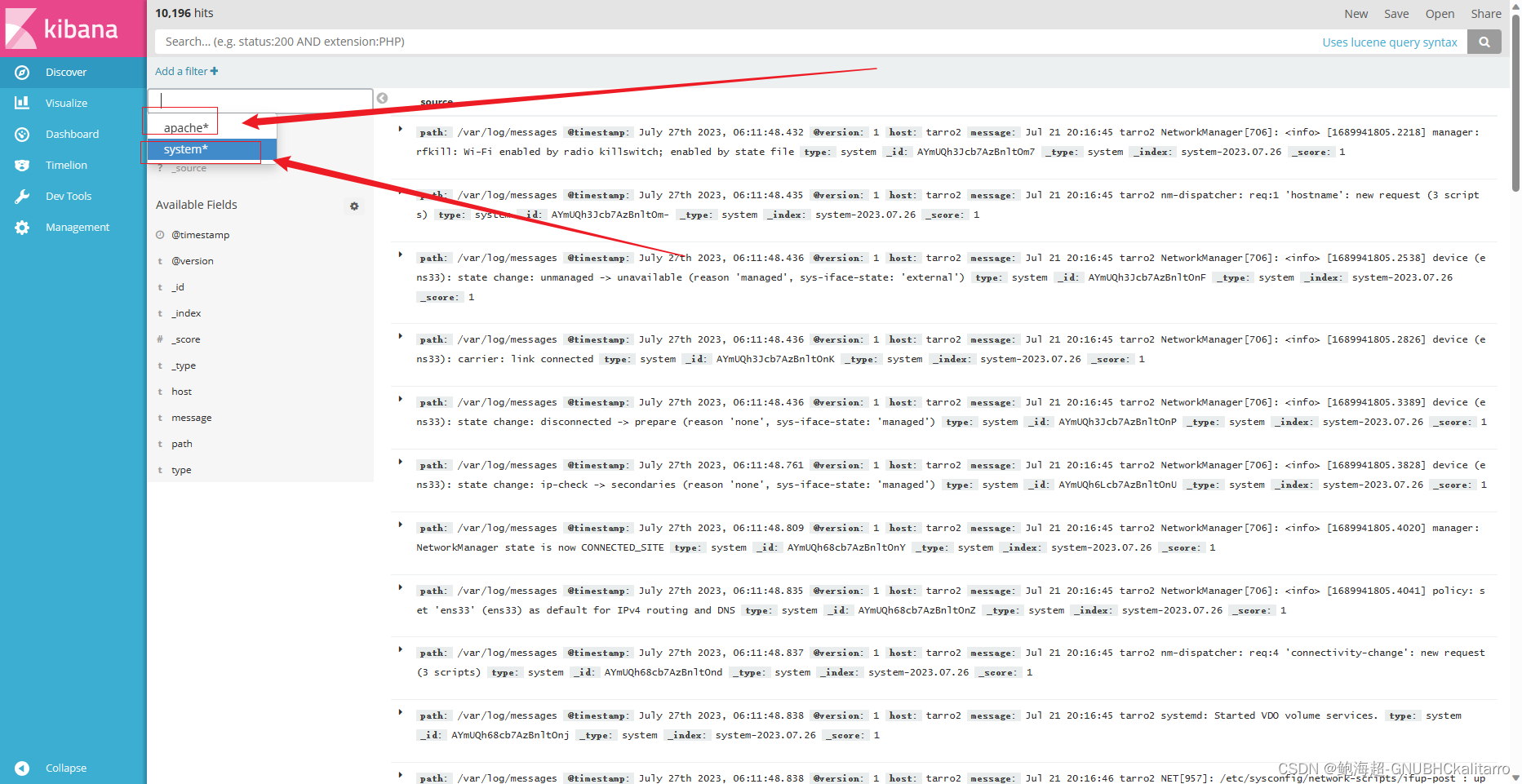
要看那个选那个
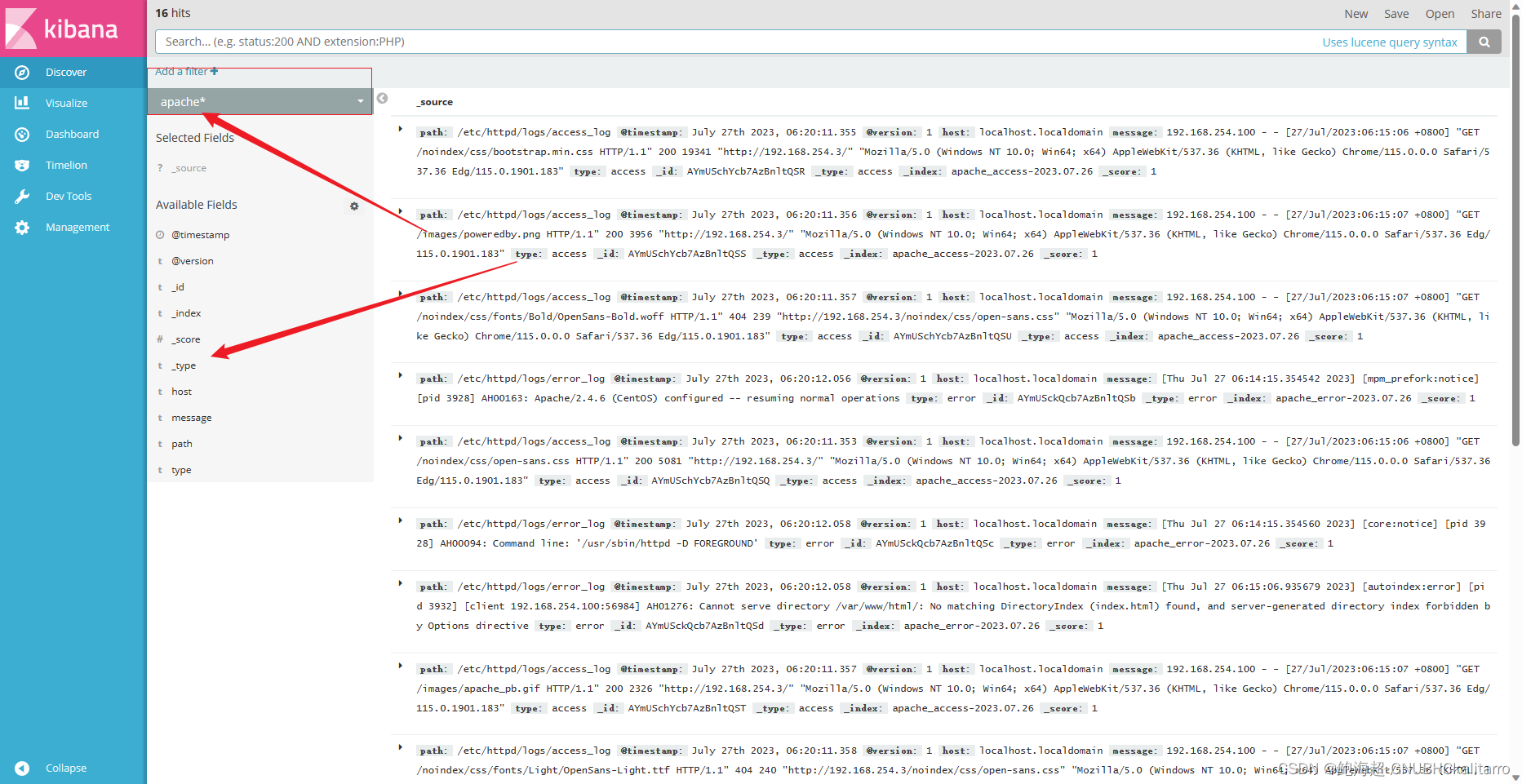
展示成功