网址:
gwhttps://patents.google.com/
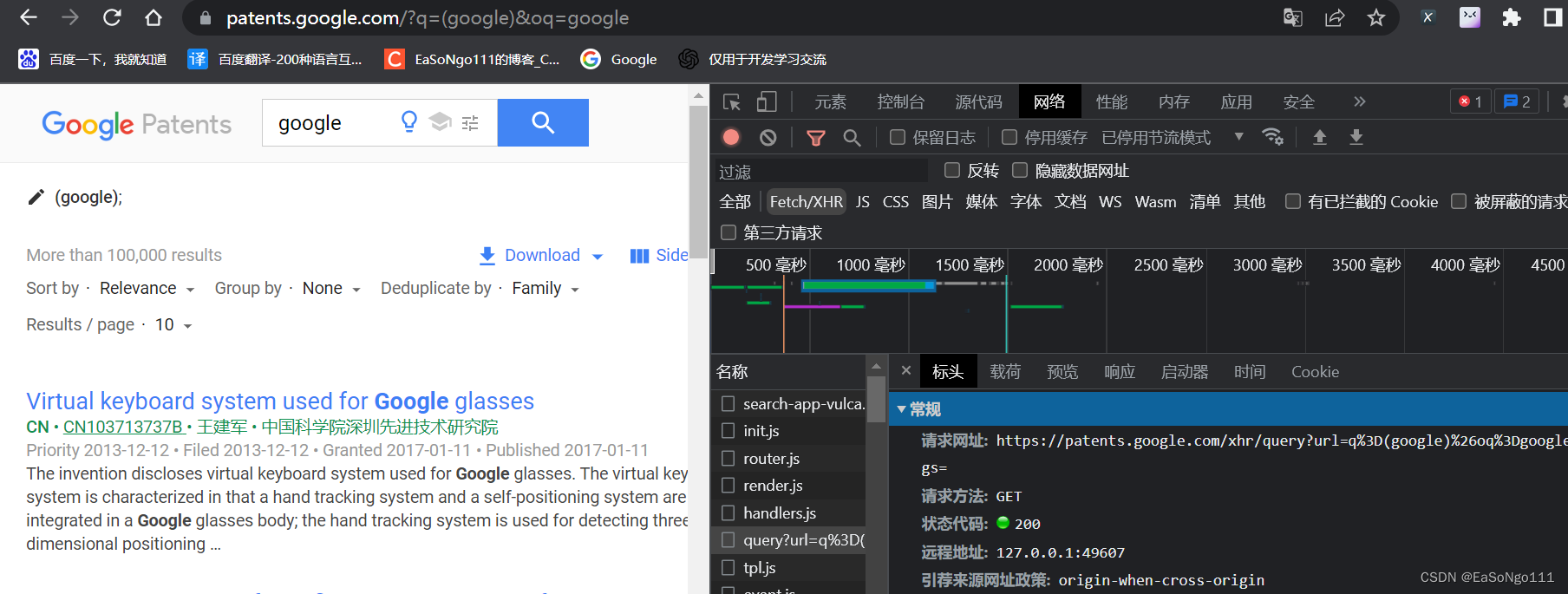
通过F12找到请求头
https://patents.google.com/xhr/query?url=q=(google)&oq=google&exp=&tags=
# -*- coding: utf-8 -*-
import scrapy
import io
import sys
import requests
import xlrd
from xlwt import *
from openpyxl import Workbook as wb
import os
import re
import csv
import time
import random
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')def read_company():fileName0 = 'sample.xlsx'bk=xlrd.open_workbook(fileName0)shxrange=range(bk.nsheets)try:sh=bk.sheet_by_name("Sheet1")except:print ("代码出错")# ncols=sh.ncols #获取列数# nrows=sh.nrows #获取列数book = Workbook(encoding='utf-8')# sheet = book.add_sheet('Sheet1') #创建一个sheetUPC = []tmp1 = sh.col_values(0)[1:] #companytmp2 = sh.col_values(1)[1:] #tic# tmp3 = sh.col_values(2)[1:] #IRIreturn tmp1def start_requests():base_url = 'https://patents.google.com/xhr/query?'company = 'CANCERVAX CORP'patent_name = 'url=assignee=' + company + '&oq=' + company + '&exp=&download=true'param = {}suburl = base_url + patent_nameprint(suburl)file_name = 'test.csv'r = requests.get(suburl)fo = open(file_name,'wb') # 注意要用'wb',b表示二进制,不要用'w'fo.write(r.content) # r.content -> requests中的二进制响应内容:以字节的方式访问请求响应体,对于非文本请求fo.close()# start_requests()
read_company()
proxies = {"https": "https://127.0.0.1:1080", "http": "http://127.0.0.1:1080"}
base_url = 'https://patents.google.com/xhr/query?'
url_list = []
company_list = read_company()
headers = {'user_agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
'authority':'patents.google.com',
'method':'GET',
'scheme':'https',
'accept':'*/*',
'accept-encoding':'gzip, deflate, br',
'accept-language':'en,en-US;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'cookie':'_ga=GA1.3.650546010.1557842690; 1P_JAR=2019-06-13-03; NID=185=HFLQWsc9gyTy7jWJiX-sZ242_kqMdEVUKf89m0r0R8jrCT1n2jN8cuSFmh6abb50bDB8u6qYhcF7KXWHgZy4TPj-zkheFl9g6kiLCqFrNEf6G_2hLhWzCfjwkz7EjLB8jrROilpayn5NIIKf0WLZsZCBemnNt88RdO4Tik_zYwg; _gid=GA1.3.814134454.1560407883; _gat=1'
}
user_agent_pool = ["Mozilla/5.0 (Macintosh; U; Mac OS X Mach-O; en-US; rv:2.0a) Gecko/20040614 Firefox/3.0.0 ",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.0.3) Gecko/2008092414 Firefox/3.0.3",
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1) Gecko/20090624 Firefox/3.5",
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.6; en-US; rv:1.9.2.14) Gecko/20110218 AlexaToolbar/alxf-2.0 Firefox/3.6.14",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"]
ip_pool = ['114.230.69.170:9999','61.135.155.82:443']
print(company_list)
for company in company_list:# print(company)patent_name = 'url=assignee=' + company + '&oq=' + company + '&exp=&download=true'url = base_url + patent_namefilename = './company_patent/' + company + '.csv'# print(url)ip = ip_pool[random.randrange(0,2)]headers['user_agent'] = user_agent_pool[random.randrange(0,len(user_agent_pool))]proxy_ip = 'http://'+ipproxies = {'http':proxy_ip}r = requests.get(url,headers=headers,proxies=proxies)fo = open(filename,'wb') # 注意要用'wb',b表示二进制,不要用'w'fo.write(r.content) # r.content -> requests中的二进制响应内容:以字节的方式访问请求响应体,对于非文本请求# filename1 = './company_patent/' + company + '.csv'# with open(filename1) as f:# csv_reader =csv.reader(f)# for line in csv_reader:# print(line)fo.close() time.sleep(15)- 导入需要的库,如Scrapy、requests、xlrd等;
- 通过read_company()函数读取excel表格中的公司名称;
- 通过start_requests()函数发送GET请求获取特定公司的专利信息,并将响应内容写入csv文件中;
- 最后循环遍历所有公司,调用requests库发送GET请求获取专利信息,再将响应内容写入csv文件中。
反爬措施:
(1)随机ip池
(2)随机user-agent池
(3)增加每次爬取的延时