之前我以前完成了“使用langchain与你自己的数据对话(一):文档加载与切割”这篇博客,没有阅读的朋友可以先阅读一下,今天我们来继续讲解deepleaning.AI的在线课程“LangChain: Chat with Your Data”的第三门课:向量存储与嵌入。
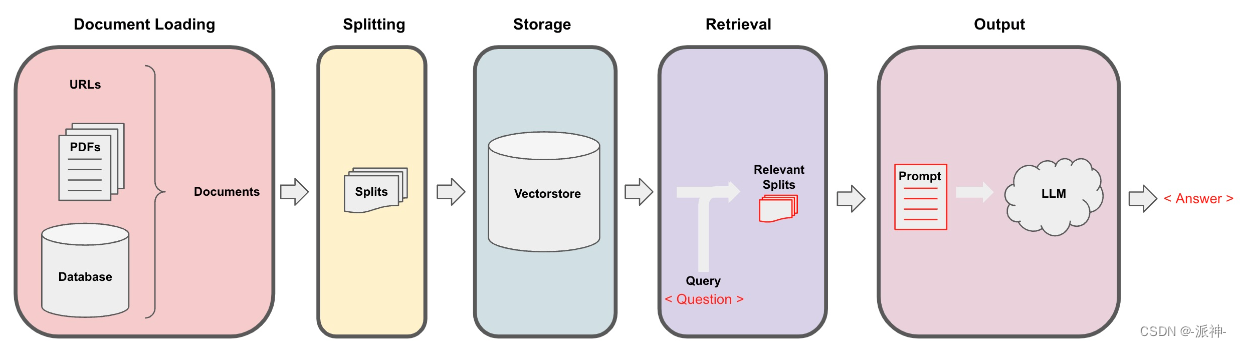
Langchain在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output,如下图所示:
在上一篇博客:文档加载与切割中我已经介绍了如何使用Langchain来加载外部的文档,以及如何切割文档,之所以要对文档做加载与切割的操作,是因为外部数据类型和属性有所不同,比如外部数据可能是pdf, text, 网页,youtube视频等,要读取不同类型的外部数据我们就需要有专门的Loader来加载这些数据,所以我们就需要各种类型的文档加载器,当数据被加载器加载以后,接下来我们需要做文档的切割,这是因为外部数据的体量可能比较大,如pdf文档可能会有几十页,几百页的内容,所以我们需要将文档内容按一点尺寸(chunk_size)均匀的切成小块(chunks), 在上一篇博客中我们介绍了几种Langchain常用的文档切割器如RecursiveCharacterTextSplitter, CharacterTextSplitter,TokenTextSplitter,MarkdownHeaderTextSplitter等,其中Langchain默认使用RecursiveCharacterTextSplitter切割器。当文档被切割以后,加下来就到了嵌入(Embeddings)和向量存储(vectorstores)的环节,如下图所示:
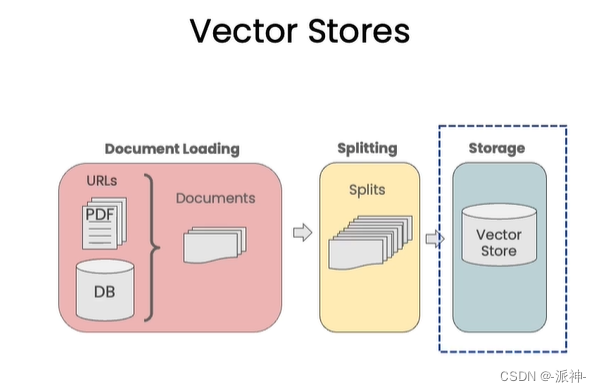
所谓的向量存储是指被切割的文档需要经过向量化操作以后存储到向量数据库的过程,因为大型语言模型(LLM)无法理解文字信息(只能理解数字),所以我们必须对文字信息进行编码,这里说的编码就是只嵌入(Embeddings), 嵌入操作可以将文本转换成数字编码并以向量的形式存储在向量数据库中,如下图所示:
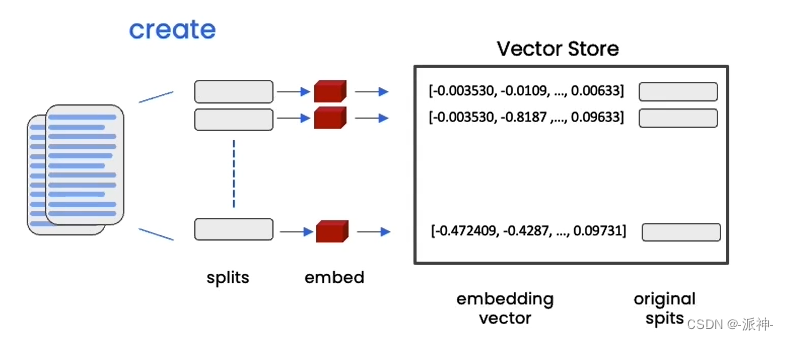
当文档被切割成块(chunks)后,每一个块都会经嵌入操作后转换成向量并存储在向量数据库中,当用户对文档内容提出问题时,用户的问题也会经嵌入操作后被转换成向量并与向量数据库中的所有向量做相似度比较,最后找出与问题最相关的n个向量,如下图所示:
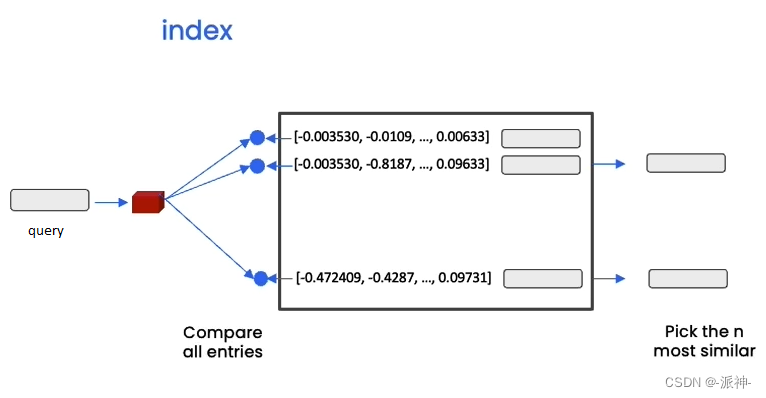
当找到与用户问题最相关的n个向量以后,这些向量会被还原成原始文本,然后将用户的问题和这些文本信息发送给LLM, LLM会针对用户的问题对这些文本内容做提炼和汇总,最后给出正确合理的答案,如下图所示:
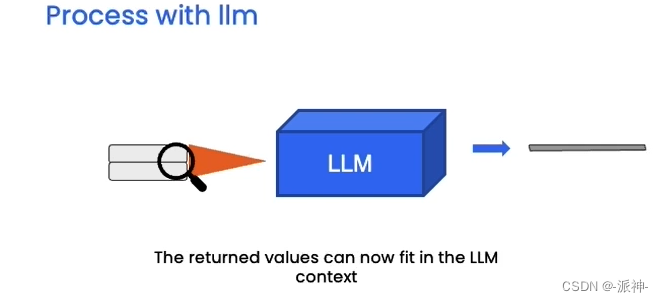
整个与文档对话的过程大致就是这样,下面我们来实操一下上面的嵌入和向量存储的过程,不过首先我们还是需要做一下些基础性工作,比如设置一下openai的api key:
import os
import openai
import sys
sys.path.append('../..')from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env fileopenai.api_key = os.environ['OPENAI_API_KEY']Document Loading & Splitting
接下来我们首先来实现文档的加载和切割,这里我们会加载一组吴恩达老师著名的机器学习课程cs229的pdf讲义稿:
from langchain.document_loaders import PyPDFLoader# Load PDF
loaders = [# Duplicate documents on purpose - messy dataPyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"),PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture02.pdf"),PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture03.pdf")
]
docs = []
for loader in loaders:docs.extend(loader.load())需要说明一下的是这里我们加载了2篇相同的pdf文档:Lecture01.pdf,之所以要加载两篇相同的pdf文档,是为了后面我们需要做一些测试看看当文档内容相同的时候LLM的表现。当文档完成加载以后,下面我们就需要对文档进行切割,首先我们需要创建一个文档切割器RecursiveCharacterTextSplitter:
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1500,chunk_overlap = 150
)这里关于参数chunk_size ,和chunk_overlap 的含义在文档加载与切割这篇博客中已经详细说明过了,这里不再赘述。当文档切割器创建完成以后,我们可以开始切割文档的操作:
#切割文档
splits = text_splitter.split_documents(docs)#查看切割后文档的数量
print(len(splits))![]()
这里我们看到切割后的文档长度是209,也就是说所有的pdf文档被切割成了209块(chunks),我们可以查看其中的某一块的文档内容:
splits[0] 
我们看到被切换的文档块中包含了文档的内容(page_content)和元数据(metadata),在元数据中记录了文档的位置和该块内容所在的页数。那么现在在splits中就包含了209个这样的文档块。
Embeddings
所谓的嵌入(Embeddings)是一种文本的编码的方法,它可以一段文字转换成一定长度的一组向量,下面我们来做一下简单的embedding测试:
from langchain.embeddings.openai import OpenAIEmbeddings
embedding = OpenAIEmbeddings()sentence1 = "我喜欢小狗。"
sentence2 = "我喜欢小动物。"
sentence3 = "我今天心情很差。"embedding1 = embedding.embed_query(sentence1)
embedding2 = embedding.embed_query(sentence2)
embedding3 = embedding.embed_query(sentence3)这里我们有三句简单的中文句子,前两句表达人和动物之间的关系,第三句表达人的心情,所以前两句的含义应该比较相似,后第三句和前两句的含义完全不同,下面我们可以通过计算两个向量的点积来得到两个向量的相似度:
np.dot(embedding1, embedding2) 
np.dot(embedding1, embedding3) 
np.dot(embedding2, embedding3) 
我们可以看到embedding1与embedding2之间有较高的相似性达到了0.94,而embedding3与embedding1和embedding2的相似度只都只有0.8以下,这说明第一句和第二句话有较高的相似度。下面我们看一下经过embedding操作以后的结果是怎么样的:
print(embedding1) 
这里我们看到经过embdding操作后生成的向量是一个python的list, 其中包含了很多数字,下面我们再看一下这个embdding的长度:
print(len(embedding1))![]()
这里我们可以看到经过embdding操作以后生成的向量的长度是1536,也就是说由1536个数字来表示了被embdding的这句文本,我们也可以看成是由1536个维度来表示这句文本。
向量数据库
当我们知道了Embedding的原理以后,接下来我们来介绍一种向量数据库Chroma,Chroma 是开源嵌入(Embedding)数据库。Chroma 通过为大型语言模型(LLM)提供可嵌入的知识、事实和技能,让构建大型语言模型(LLM)的应用程序变得更加容易,如下图所示:
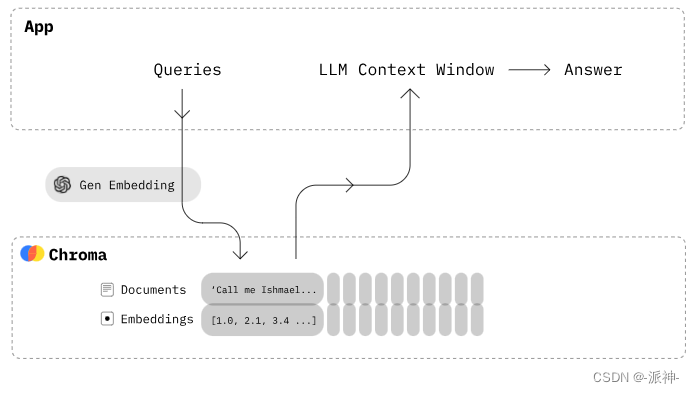
接下来我们来实际操作创建向量数据库的过程,并且将生成的向量数据库保存在本地。当我们在创建Chroma数据库时,我们需要传递如下参数:
- documents: 切割好的文档对象
- embedding: embedding对象
- persist_directory: 向量数据库存储路径
from langchain.vectorstores import Chroma#向量数据库保存位置
persist_directory = 'docs/chroma/'#创建向量数据库
vectordb = Chroma.from_documents(documents=splits,embedding=embedding,persist_directory=persist_directory
)#查看向量数据库中的文档数量
print(vectordb._collection.count()) ![]()
这里我们看到向量数据库中存储这209个向量,这和我们之前切割文档后的splits 中的数量是一至的,这说明原来209个文档块已经被转换成了209个向量并且被保存在了Chroma数据库中。
相似度搜索(Similarity Search)
当文档被切割并经embedding操作后转换成向量存储到Chroma数据库中后,我们可以对Chroma数据库中的向量进行相似度的比较,也就是我们可以模拟用户提出问题,然后去Chroma执行相似内容搜索,并返回与问题相似度较高的文本内容:
question = "is there an email i can ask for help"docs = vectordb.similarity_search(question,k=3)#打印文档数量
print(len(docs))![]()
这里我们要求向量数据库对问题进行相似度搜索,找出和问题最相关的3个(k=3)文档。下面我们查看其中的一个文档的内容:
docs[0].page_content
我们看到第一篇文档中包含了"email"这个单词,这和我们的问题显然是相关的。接下来我们来实现向量数据库的持久化:
vectordb.persist()执行了persist()操作以后向量数据库才真正的被保存到了本地,下次在需要使用该向量数据库时我们只需要从本地加载数据库即可,无需再根据原始文档来生成向量数据库了。
失败的应用场景
虽然有了向量数据库,基本上可以让我们轻松完成 80% 的相似性搜索任务。但也存在一些失败的场景,比如下面的例子:
question = "what did they say about matlab?"docs = vectordb.similarity_search(question,k=5)这里我们要求向量数据库搜索5个和问题相关的答案,但是大家还记得之前我们在创建文档加载器时加载了两篇相同的文档(Lecture01.pdf),所以现在向量数据库中应该有重复的向量,因此如果当用户的问题和Lecture01.pdf中的内容相关时,向量数据库会返回重复的内容:
docs[0]
docs[1] 
这两我们看到docs[0]和docs[1]的内容是完全一样的,这是因为我们之前加载了重复的文档(Lecture01.pdf)所导致的。如何避免让向量数据库返回重复的内容,我们将在下一篇博客中讨论这个问题,下面我们再看一种失败的场景,这里我们要求向量数据库在第三篇原始文档()中搜索相关答案:
question = "what did they say about regression in the third lecture?"docs = vectordb.similarity_search(question,k=5)for doc in docs:print(doc.metadata)
从上面的返回结果中我们看到,虽然我们要求向量数据库只能从第三篇文档中搜索相关答案,但是从返回结果的元数据中我们看到第一篇(Lecture01.pdf)和第二篇(Lecture02.pdf)的内容也在其中,这与我们的要求(问题)相违背,因为我们只要求搜索第三篇文档(Lecture03.pdf)即可。这似乎说明向量数据库并没有很好的理解问题的语义。下面我们查看一下返回的最后一个文档的内容(Lecture01.pdf):
print(docs[4].page_content)
这里我们看到docs[4]对应的是Lecture01.pdf中的第8页的内容,其中也包含了“regression”,这和我们的问题相关。
关于如何避免上述失效的应用场景,我们将会在下一篇博客中进行讨论。
总结
今天我们学习了嵌入和向量数据库的基本原理,并且对嵌入(Embeddings)和开源数据库Chroma进行了实际的操作,并观察了它们的返回结果,同时我们还发现了两种Chroma数据库相似搜索失效的场景。关于如何避免产生失效的结果我们将在下一篇博客中进行讨论。
参考资料
🏡 Home | Chroma
Chroma | 🦜️🔗 Langchain